标签:现在 表锁 没有 必须 vcc 数据存储 ima 不可重复读 匹配
聚集和非聚集索引
简单概括:
- 聚集索引就是以主键创建的索引
- 非聚集索引就是以非主键创建的索引
区别:
- 聚集索引在叶子节点存储的是表中的数据
- 非聚集索引在叶子节点存储的是主键和索引列
- 使用非聚集索引查询出数据时,拿到叶子上的主键再去查到想要查找的数据。(拿到主键再查找这个过程叫做回表)
非聚集索引也叫做二级索引,不用纠结那么多名词,将其等价就行了~
非聚集索引在建立的时候也未必是单列的,可以多个列来创建索引。
- 此时就涉及到了哪个列会走索引,哪个列不走索引的问题了(最左匹配原则-->后面有说)
- 创建多个单列(非聚集)索引的时候,会生成多个索引树(所以过多创建索引会占用磁盘空间
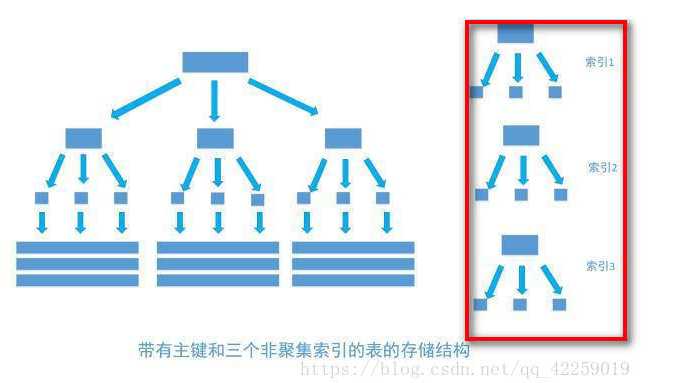
创建多列索引中也涉及到了一种特殊的索引-->覆盖索引
- 我们前面知道了,如果不是聚集索引,叶子节点存储的是主键+列值
- 最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢
- 覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
比如说:
- 现在我创建了索引
(username,age),在查询数据的时候:select username , age from user where username = ‘Java3y‘ and age = 20。
- 很明显地知道,我们上边的查询是走索引的,并且,要查询出的列在叶子节点都存在!所以,就不用回表了~
- 所以,能使用覆盖索引就尽量使用吧~
存储特点
- 聚集索引。表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。
- 非聚集索引。表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
总结一下:聚集索引是一种稀疏索引,数据页上一级的索引页存储的是页指针,而不是行指针。而对于非聚集索引,则是密集索引,在数据页的上一级索引页它为每一个数据行存储一条索引记录。
innodb可重复读隔离级别解决国不可重复读在问题,利用MVCC版本解决的。
innode利用next-key locks间隙锁解决的是当前读情况下的幻读。
脏读和不可重复读都是一个事务读,另外一个事务写引起的。
而两个事务一起写造成读写冲突时,造成丢失更新:一个事务的更新覆盖了其它事务的更新结果。解决的办法有:
- 使用Serializable隔离级别,事务是串行执行的!
- 乐观锁
- 悲观锁
如果我们的锁用到索引就是行锁,如果没有用到索引就是表锁,但是我们操作的数据必须用到锁才行。
注意几点:
1.行锁必须有索引才能实现,否则会自动锁全表,那么就不是行锁了。
2.两个事务不能锁同一个索引
聚集和非聚集索引
标签:现在 表锁 没有 必须 vcc 数据存储 ima 不可重复读 匹配
原文地址:https://www.cnblogs.com/heqiyoujing/p/11221980.html