标签:顺时针 png src 场景 分布 因此 新建 alt logs
当我们在数据库中存储海量数据时,由于单表数据存在上限,所以不得不分库分表存储。假设我们有2000W条数据,而单表上限为500W,我们部署了4台数据库服务器来存储这些数据,当我们需要查找某一条数据时,我们对四个数据库进行逐个查找,显然这样做效率太低。因此我们可以使用哈希算法,建立数据与数据库服务器之间的映射关系,存储数据时,将数据某属性(尽量保证唯一性)进行哈希,结果模4,用来选择将该条数据存储在哪台服务器上。这样当查找数据时,使用相同的哈希算法,就可直接定位到该数据存储的服务器,而不必对每个服务器进行查找,只需在某一服务器查找。
上述哈希已经解决了分布式存储数据查找效率的问题。
但是,当对系统中服务器数量进行增加或减少时,由原来的4变为5或3,这将导致之前建立的映射关系大规模失效,因为在存储时模4,而在查找时因服务器数量变化需模3或5。因此每当服务器增加或减少时,我们需要对所以数据重新建立映射,重新存储。显然代价是巨大的。而一致性哈希有效的解决了这一问题。
在上面进行哈希运算时,我们对结果模数据库服务器的数量,而一致性哈希再取模时模2^32(整形最大值),一致性哈希算法将结果取值范围组织成一个虚拟的环,整个空间按顺时针组织,具体如下:
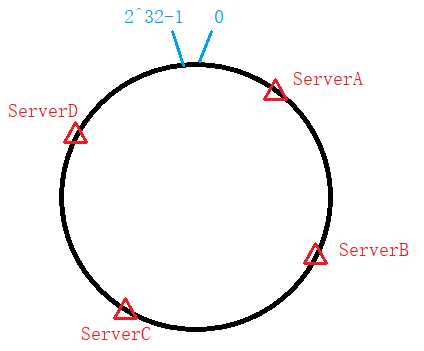
(1)一开始,分别对4台服务器各自的IP进行哈希,确定每一台服务器在该环中的位置,结果如下:
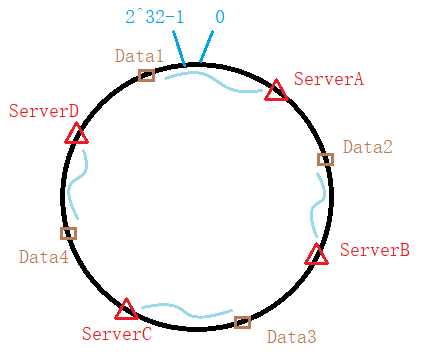
(2)将数据使用相同的哈希算法计算出哈希值,确定每条数据在环中的位置,从该位置顺时针前进,遇到的第一台服务器就是该数据应该被存储到的服务器。如下:
当系统中新加入服务器时,如图:
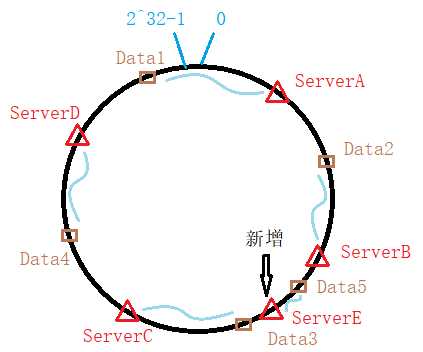
根据相同的哈希算法确定新增服务器的位置,图中ServerE。可以看出,此时并不影响ServerA ServerB ServerD,只是原本存储于ServerC上的位于ServerB和ServerE之间的数据(如Data5)需要从新存储到ServerE。
当系统中服务器数量减少时:
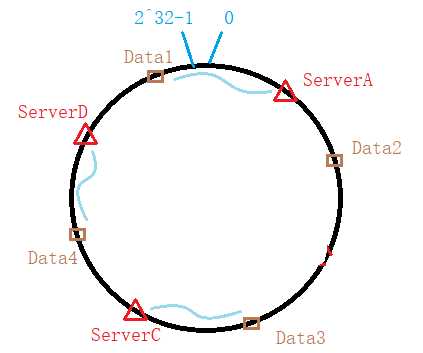
我们只需将原本存储在ServerB中的数据(如Data2)存储到ServerC即可,而不影响SeverA ServerD以及ServerC中原本的数据。
总结:与未使用一致性哈希算法相比,一致性哈希算法避免了系统中节点数目发生变化时所有数据重新载入的问题,减少了不必要的消耗。总之一致性哈希大大减少了分布式系统中节点数量改变时需重新载入的数据总量。
参考:https://www.cnblogs.com/study-everyday/p/8629100.html
标签:顺时针 png src 场景 分布 因此 新建 alt logs
原文地址:https://www.cnblogs.com/dabai56/p/11221875.html