标签:ini 出现 下一步 tps 策略 影响 pool 多重 简化
文献所提出的模型旨在解决交通中行人的轨迹预测(pedestrian trajectory prediction)问题,特别是在拥挤环境中——人与人交互(interaction)行为常有发生的地方。
文献构建的数据驱动模型,利用在序列预测上表现突出的LSTM模型以行人为单位进行轨迹预测,同时为了解决多个行人的LSTMs之间无法捕捉行人空间中交互的问题,模型在LSTMs每一步运行之间加入了“Social”池化层,池化层将整合其他行人的隐藏状态(Hidden State),并作为隐藏状态一部分传递下去,最终形成模型Social LSTM。
由于池化层的引入,使得LSTMs间出现动态数据(在模型运行中才能得到)的依赖,模型训练时需要有多个LSTMs同步并行运行和反向传播,为了简化训练压力,文献也提出了O-LSTM模型,该模型可针对每位行人的轨迹进行独立的训练。
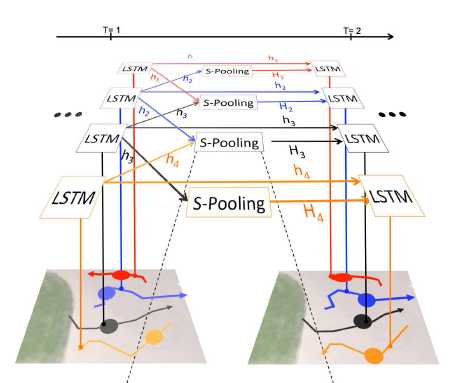
最后,文献使用了ETH和UCY两个公开数据库数据,从轨迹平均误差、重点误差和轨迹非线性区间误差三个指标衡量多重模型的预测性能,得出Social-LSTM和O-LSTM性能整体上优于其他模型的结论。
前人对交互环境下的轨迹预测已经提出了多种方法,例如以Social Force为基础的将行人行动模型之间刻画吸引力和排斥力的模型,已发展出了相当多的方法,然而文献中提到这些方法大都受限于两个方面:
数据源:ETH、UCY
数据格式(经处理和提取以适应此训练任务)
? 元数据标签:time frame(时间片序号)、pedestrian ID(行人标识符)、position x、position y
? 时间精度:time frame之间间隔均为10的倍数,精度为0.4秒
? 位置精度:训练数据中x和y均经过标准化处理,\(0 <= x,y <= 1\) 。源数据中x,y,z精度为米。
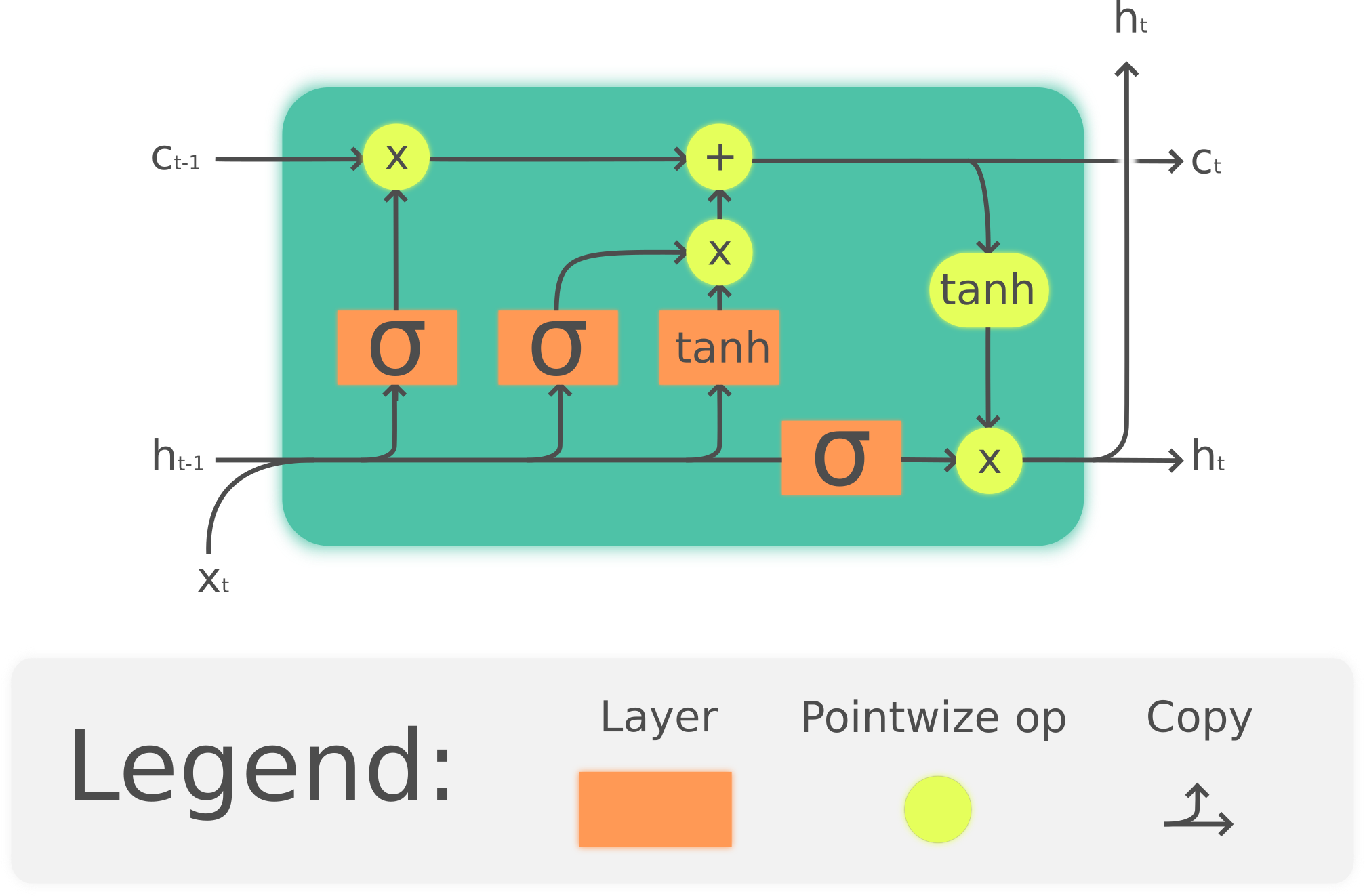
LSTM模型被证明为解决序列预测问题的有效方式,由一个LSTM Cell经过多次迭代,每步迭代中都会接受输入和产生输出,从而产生序列型输出。有关RNN及LSTM标准模型本文不再详细介绍,此处仅说明实际应用时的要点。
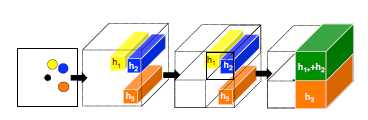
Social Tensor是使得每位行人的LSTM模型进行信息交换的途径,实质是一个池化层,每个行人\(i\)在每个时间点\(t\)均对应一个Social Tensor-\(H^i_t\),用于记录在该行人划定的范围\(Z^i_t\)中,其他行人的信息,并作为行人\(i\)隐藏状态的一部分,参与其下一步轨迹预测从而起到传递行人间交互信息的作用。
量化描述:
Shape : [\(N_0\), \(N_0\), \(D\)](其中\(N_0\)是\(Z_i\)区域的进一步等距划分,\(D\)是隐藏状态 Hidden State的维度大小)
数据组成:每个\(H^i_t\)均由其他LSTM模型的\(h^i_t\)按一定策略加和。首先,只有处在\(Z^t_i\)区域中的行人的LSTM模型的\(h^i_t\)会被累积;其次,\(Z_t^i\)区域存在进一步分区,对于被累积的\(h^i_t\),其会被累加至对应的分区上。
\[H_t^i(m,n,:) = \sum_{j \in N_i } 1_{mn}[x_t^j - x_t^i, y_t^j - y_t^i]h_{t-1}^j\]
其中,\(1_{mn}[...]\)是01函数用于判断是否处在区域中,\(h_{t-1}^j\)是隐藏状态,\(N_i\)是相邻行人。
Social Tensor池化的简化版,使得模型训练时无需同时处理所有的轨迹,下述公式也可看出Tensor中不再统计隐藏状态的值,而只统计行人数量。
\[ O_t^i(m,n,:) = \sum_{j \in N_i} 1_{mn}[x_t^j - x_t^i, y_t^j - y_t^i]\]
文献阅读报告 - Social LSTM:Human Trajectory Prediction in Crowded Spaces
标签:ini 出现 下一步 tps 策略 影响 pool 多重 简化
原文地址:https://www.cnblogs.com/sinoyou/p/11227348.html