标签:debug asi ror 正弦 嵌入 框架 distrib 常用 std
作者:李丕绩(腾讯AI Lab)
模型:Transformer + copy mechanism for abstractive summarization
数据集:CNN/Daily Mail
WARNING: IN DEBUGGING MODE
USE COPY MECHANISM
USE COVERAGE MECHANISM
USE AVG NLL as LOSS
USE LEARNABLE W2V EMBEDDING
RNN TYPE: transformer
idx_gpu: 0
norm_clip: 2 # gradient clipping by norm
dim_x: 512
dim_y: 512
len_x: 401
len_y: 101
num_x: 1
num_y: 1
hidden_size: 512
d_ff: 1024
num_heads: 8 # 8头注意力机制
dropout: 0.2
num_layers: 4
label_smoothing: 0.1
alpha: 0.9
beta: 5
batch_size: 5
testing_batch_size: 1
min_len_predict: 35
max_len_predict: 120
max_byte_predict: None
testing_print_size: 500
lr: 0.15
beam_size: 4
max_epoch: 50
print_time: 20 # 每个 epoch 打印信息,以及保存模型的次数
save_epoch: 1
dict_size: 50003 # vocabulary 大小
pad_token_idx: 0
loading train set...
num_files = 13
num_batches = 3Model(
(tok_embed): Embedding(50003, 512, padding_idx=0)
(pos_embed): LearnedPositionalEmbedding(
(weights): Embedding(1024, 512)
)
(enc_layers): ModuleList(
(0): TransformerLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(fc1): Linear(in_features=512, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(attn_layer_norm): LayerNorm()
(ff_layer_norm): LayerNorm()
)
(1): TransformerLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(fc1): Linear(in_features=512, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(attn_layer_norm): LayerNorm()
(ff_layer_norm): LayerNorm()
)
(2): TransformerLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(fc1): Linear(in_features=512, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(attn_layer_norm): LayerNorm()
(ff_layer_norm): LayerNorm()
)
(3): TransformerLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(fc1): Linear(in_features=512, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(attn_layer_norm): LayerNorm()
(ff_layer_norm): LayerNorm()
)
)
(dec_layers): ModuleList(
(0): TransformerLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(fc1): Linear(in_features=512, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(attn_layer_norm): LayerNorm()
(ff_layer_norm): LayerNorm()
(external_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(external_layer_norm): LayerNorm()
)
(1): TransformerLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(fc1): Linear(in_features=512, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(attn_layer_norm): LayerNorm()
(ff_layer_norm): LayerNorm()
(external_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(external_layer_norm): LayerNorm()
)
(2): TransformerLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(fc1): Linear(in_features=512, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(attn_layer_norm): LayerNorm()
(ff_layer_norm): LayerNorm()
(external_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(external_layer_norm): LayerNorm()
)
(3): TransformerLayer(
(self_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(fc1): Linear(in_features=512, out_features=1024, bias=True)
(fc2): Linear(in_features=1024, out_features=512, bias=True)
(attn_layer_norm): LayerNorm()
(ff_layer_norm): LayerNorm()
(external_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(external_layer_norm): LayerNorm()
)
)
(attn_mask): SelfAttentionMask()
(emb_layer_norm): LayerNorm()
(word_prob): WordProbLayer(
(external_attn): MultiheadAttention(
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(proj): Linear(in_features=1536, out_features=50003, bias=True)
)
(smoothing): LabelSmoothing()
)
模型结构:
1. 嵌入表示:token embedding,positional embedding
2. encoder:3个blocks(8头注意力)
3. decoder:3个blocks(8头注意力)
4. mask attention层
5. layer normalization:层标准化
6. word probability layer:映射到单词表上的概率分布处理数据,得到的结果如下:
拿test set举例,数据集中有11489对 article-summary。数据结构如下:
所有的数据对组成一级列表,每对数据由两个子列表组成,分别代表article 和 summary
article列表和summary中,分为两个子列表,第一个是分词后的序列,第二个是分词之前的原始文本
利用pytorch框架构建了Transformer summarizer模型:
设置模型参数,几个比较重要的:
使用了copy mechanism 和 coverage mechanism;
使用NLL作为loss function;
d_ff size = 1024;
context size = 512;
hidden size = 512;定义了几个比较常用的结构:
label smoothing
可学习的token embedding,positional embedding
word probability layer
embedding layer normalization 
可以看到encoder,decoder中都包含多个(4个)基本modules。每个module的结构如下:

其中包含了子模块,子模块的下级模块如下:self-attention结构,两个全连接层,attention normalization layer,feed forward nomalization layer:

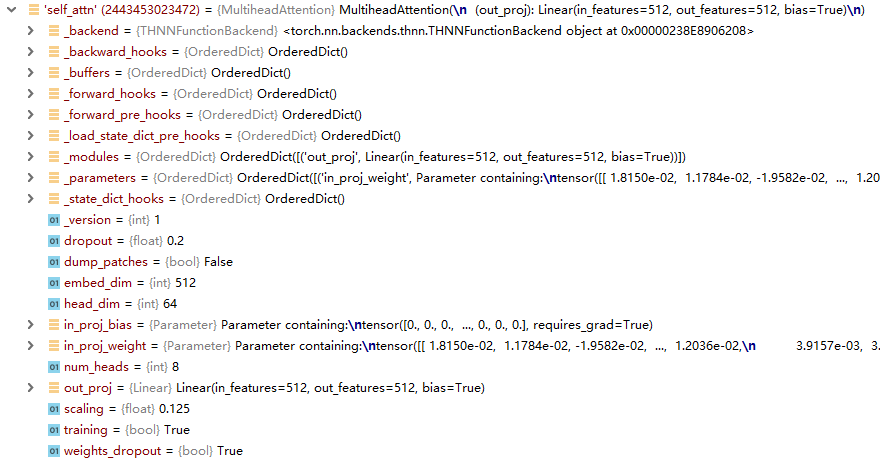
self-attention 模块结构如下图:
token embedding 用的是 nn.Embedding 在训练的时候进行学习。模块化参数:vocabulary size = 50003,embedding dim = 512
positional embedding 用的还nn.Embedding,随着训练进行学习。模块参数:init_size = 1024(最大的position),embedding dim = 512;参数用正态分布进行随机初始化
作者同样实现了类 SinusoidalPositionalEmbedding 可以将 learnable positional embedding 变为 fixed,即论文中加入位置信息的方式
# encoder
self.enc_layers = nn.ModuleList()
for i in range(self.num_layers):
self.enc_layers.append(TransformerLayer(self.dim_x, self.d_ff, self.num_heads, self.dropout))
# decoder
self.dec_layers = nn.ModuleList()
for i in range(self.num_layers):
self.dec_layers.append(TransformerLayer(self.dim_x, self.d_ff, self.num_heads, self.dropout, with_external=True))
torch可以用nn.ModuleList()来增加模块的层,此处num_layer = 4 ,即加入4层Transformer stack作为encoder。
定义基本单元的时候TransformerLayer的初始化定义不同。
流程:
decoding 此处分为两种情况:
流程:
进行条件判别:
class MultiheadAttention)计算attention。函数参数:scatter_add_(dim, ?indexTensor, ?otherTensor)?→ 输出Tensor
函数用法:selfTensor.scatter_add_(dim, ?indexTensor, ?otherTensor)
# 该函数将?otherTensor?的所有值加到?selfTensor?中,加入位置由?indexTensor?指明
def label_smotthing_loss(self, y_pred, y, y_mask, avg=True):
seq_len, bsz = y.size()
y_pred = T.log(y_pred.clamp(min=1e-8))
loss = self.smoothing(y_pred.view(seq_len * bsz, -1), y.view(seq_len * bsz, -1))
if avg:
return loss / T.sum(y_mask)
else:
return loss / bszloss function的实现中用到了一个clamp夹逼函数:
torch.clamp(input, min, max, out=None) → Tensor作用是将inpout tensor的数值限制在min到max之间,大于max即为max,小于min即为min,在两者之间不变
然后y_pred(预测的单词对应的概率值)与真实值y送入smoothing函数,作者写了一个类class LabelSmoothing
初始化类的时候需要传入label_smoothing_factor,即padding位在vocabulary中的索引。利用target计算出model prob;
返回model prob与y_pred之间的KL divergence作为loss
def nll_loss(self, y_pred, y, y_mask, avg=True):
cost = -T.log(T.gather(y_pred, 2, y.view(y.size(0), y.size(1), 1)))
cost = cost.view(y.shape)
y_mask = y_mask.view(y.shape)
if avg:
cost = T.sum(cost * y_mask, 0) / T.sum(y_mask, 0)
else:
cost = T.sum(cost * y_mask, 0)
cost = cost.view((y.size(1), -1))
return T.mean(cost) class TransformerLayer(nn.Module):
def __init__(self, embed_dim, ff_embed_dim, num_heads, dropout, with_external=False, weights_dropout = True):
super(TransformerLayer, self).__init__()
self.self_attn = MultiheadAttention(embed_dim, num_heads, dropout, weights_dropout)
self.fc1 = nn.Linear(embed_dim, ff_embed_dim)
self.fc2 = nn.Linear(ff_embed_dim, embed_dim)
self.attn_layer_norm = LayerNorm(embed_dim)
self.ff_layer_norm = LayerNorm(embed_dim)
self.with_external = with_external
self.dropout = dropout
if self.with_external:
self.external_attn = MultiheadAttention(embed_dim, num_heads, dropout, weights_dropout)
self.external_layer_norm = LayerNorm(embed_dim)
self.reset_parameters()
def reset_parameters(self):
nn.init.normal_(self.fc1.weight, std=0.02)
nn.init.normal_(self.fc2.weight, std=0.02)
nn.init.constant_(self.fc1.bias, 0.)
nn.init.constant_(self.fc2.bias, 0.)
def forward(self, x, kv = None,
self_padding_mask = None, self_attn_mask = None,
external_memories = None, external_padding_mask=None,
need_weights = False):
# x: seq_len x bsz x embed_dim
residual = x # 残差:add & norm操作中,需要先将residual,以及residual经过feed forward得到的output进行求和,再进行norm的计算
if kv is None:
x, self_attn = self.self_attn(query=x, key=x, value=x, key_padding_mask=self_padding_mask, attn_mask=self_attn_mask, need_weights = need_weights)
else:
x, self_attn = self.self_attn(query=x, key=kv, value=kv, key_padding_mask=self_padding_mask, attn_mask=self_attn_mask, need_weights = need_weights)
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.attn_layer_norm(residual + x) # 先将residual,以及residual经过feed forward得到的output进行求和,再进行norm的计算
if self.with_external:
residual = x
x, external_attn = self.external_attn(query=x, key=external_memories, value=external_memories, key_padding_mask=external_padding_mask, need_weights = need_weights)
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.external_layer_norm(residual + x)
else:
external_attn = None
residual = x
x = gelu(self.fc1(x)) # 高斯误差线性单元 Gaussian Error Linear Units(GELU)
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.fc2(x) # 全连接层
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.ff_layer_norm(residual + x)
return x, self_attn, external_attn基本结构:
class MultiheadAttention):初始化Transformer单元的时候,需要指定number of headexternal attention层(class MultiheadAttention):如果参数with_external为True,计算attention的时候需要考虑外界的输入。即不再是query = key = value了,而key 和 value可能来自source端,这在decoder中需要用到。
全连接层(两个),形状:(embed_dim, ff_embed_dim),(ff_embed_dim, embed_dim)
class LayerNorm)parameter initialization:主要针对的是两个全连接层的weights和bias
功能(forward函数):
class MultiheadAttention,需要提供给forward函数:query,key,value;以及key_padding_mask,atten_maskwith_external为True,需要额外进行:
其中激活函数GLUE的定义如下:
def gelu(x):
cdf = 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
return cdf*x初始化MultiheadAttention需要几个参数:
head_dim,即每个注意力头的维度的计算方式为:head_dim = embed_dim // num_heads,前者必须可以为后者所整除
attention 用的还是论文中scaled attention,scaling参数是head_dim开方
对收入、输出的映射:
in_proj_bia:(3*embed_dim),先定义出来,前1/3是Query的,中间1/3是Key的,最后1/3是Value的。后面定义了一个函数_in_proj,根据传入的参数确定需要对qkv中的那几个进行映射,取出来就行了。但是输入映射的参数肯定是从in_proj_weight,in_proj_bia中取的
out_proj:(embed_dim, embed_dim)
对具体情况进行判别,对应地对输入的qkv进行输入映射:
对attention weights进行mask,使用的是方法masked_fill_ 输入一个ByteTensor,其中元素为1的位置,对应Tensor中元素会被置0。
对attention weights进行mask,再进行softmax,再进行dropout
attention output是attention weights与value进行bmm (batch matrix multiply),结果再包上一层dropout
进行一次输出映射,得到MultiheadAttention的输出
def forward(self, x):
u = x.mean(-1, keepdim=True)
s = (x - u).pow(2).mean(-1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
return self.weight * x + self.bias流程:
计算均值
计算方差
减去方差,除以标准差
经过一个线性映射(fully connected layer)
定义了两个类:
class LearnedPositionalEmbeddingclass SinusoidalPositionalEmbedding定义与Attention is All You Need 论文中一致[code] Transformer For Summarization Source Code Reading
标签:debug asi ror 正弦 嵌入 框架 distrib 常用 std
原文地址:https://www.cnblogs.com/lauspectrum/p/11229125.html