标签:== 结果 rto ast size datasets 抽取 相关 ges
聚类就是对大量未知标注的数据集,按照数据内部存在的数据特征将数据集划分为多个不同的类别,使类别内的数据比较相似,类别之间的数据相似度比较小;属于无监督学习。
算法步骤
1.初始化的k个中心点
2.为每个样本根据距离分配类别
3.更新每个类别的中心点(更新为该类别的所有样本的均值)
4.重复上面两步操作,直到达到某个中止条件
层次聚类方法对给定的数据集进行层次的分解,直到满足某种条件为止,传统的层次聚类算法主要分为两大类算法:
AGNES算法==>采用自底向上的策略。
agglomerative(凝聚) nesting(嵌套)
最初将每个对象作为一个簇,然后这些簇根据某些准则(两个簇之间的相似度度量方式)被一步一步合并,两个簇间的距离可以由这两个不同簇中距离最近的数据点的相似度来确定;聚类的合并过程反复进行直到所有的对象满足簇数目。
AGNES就是把每个水果当成一个类别,然后再进行聚类。


合并点的选择:
两个簇间的最大距离(complete)
两个簇间的最小距离(word)
两个簇间的平均距离(average)
适合链式的聚类,条状的就比较适合。
代码:
linkages :complete,word,average
import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt # 调用AGNES from sklearn.cluster import AgglomerativeClustering from sklearn.neighbors import kneighbors_graph ## KNN的K近邻计算 import sklearn.datasets as ds # 拦截异常信息 import warnings ? warnings.filterwarnings(‘ignore‘) # 设置属性防止中文乱码 mpl.rcParams[‘font.sans-serif‘] = [u‘SimHei‘] mpl.rcParams[‘axes.unicode_minus‘] = False # 模拟数据产生: 产生600条数据 np.random.seed(0) n_clusters = 4 N = 1000 data1, y1 = ds.make_blobs(n_samples=N, n_features=2, centers=((-1, 1), (1, 1), (1, -1), (-1, -1)), random_state=0) ? n_noise = int(0.1 * N) r = np.random.rand(n_noise, 2) min1, min2 = np.min(data1, axis=0) max1, max2 = np.max(data1, axis=0) r[:, 0] = r[:, 0] * (max1 - min1) + min1 r[:, 1] = r[:, 1] * (max2 - min2) + min2 ? data1_noise = np.concatenate((data1, r), axis=0) y1_noise = np.concatenate((y1, [4] * n_noise)) # 拟合月牙形数据 data2, y2 = ds.make_moons(n_samples=N, noise=.05) data2 = np.array(data2) n_noise = int(0.1 * N) r = np.random.rand(n_noise, 2) min1, min2 = np.min(data2, axis=0) max1, max2 = np.max(data2, axis=0) r[:, 0] = r[:, 0] * (max1 - min1) + min1 r[:, 1] = r[:, 1] * (max2 - min2) + min2 data2_noise = np.concatenate((data2, r), axis=0) y2_noise = np.concatenate((y2, [3] * n_noise)) ? ? def expandBorder(a, b): d = (b - a) * 0.1 return a - d, b + d ? ? ## 画图 # 给定画图的颜色 cm = mpl.colors.ListedColormap([‘#FF0000‘, ‘#00FF00‘, ‘#0000FF‘, ‘#d8e507‘, ‘#F0F0F0‘]) plt.figure(figsize=(14, 12), facecolor=‘w‘) linkages = ("ward", "complete", "average") # 把几种距离方法,放到list里,后面直接循环取值 for index, (n_clusters, data, y) in enumerate(((4, data1, y1), (4, data1_noise, y1_noise), (2, data2, y2), (2, data2_noise, y2_noise))): # 前面的两个4表示几行几列,第三个参数表示第几个子图(从1开始,从左往右数) plt.subplot(4, 4, 4 * index + 1) plt.scatter(data[:, 0], data[:, 1], c=y, cmap=cm) plt.title(u‘原始数据‘, fontsize=17) plt.grid(b=True, ls=‘:‘) min1, min2 = np.min(data, axis=0) max1, max2 = np.max(data, axis=0) plt.xlim(expandBorder(min1, max1)) plt.ylim(expandBorder(min2, max2)) ? # 计算类别与类别的距离(只计算最接近的七个样本的距离) -- 希望在agens算法中,在计算过程中不需要重复性的计算点与点之间的距离 connectivity = kneighbors_graph(data, n_neighbors=7, mode=‘distance‘, metric=‘minkowski‘, p=2, include_self=True) connectivity = (connectivity + connectivity.T) for i, linkage in enumerate(linkages): ##进行建模,并传值 ac = AgglomerativeClustering(n_clusters=n_clusters, affinity=‘euclidean‘, connectivity=connectivity, linkage=linkage) ac.fit(data) y = ac.labels_ ? plt.subplot(4, 4, i + 2 + 4 * index) plt.scatter(data[:, 0], data[:, 1], c=y, cmap=cm) plt.title(linkage, fontsize=17) plt.grid(b=True, ls=‘:‘) plt.xlim(expandBorder(min1, max1)) plt.ylim(expandBorder(min2, max2)) ? plt.tight_layout(0.5, rect=(0, 0, 1, 0.95)) plt.show()
AGNES使用不同合并方式的结果:

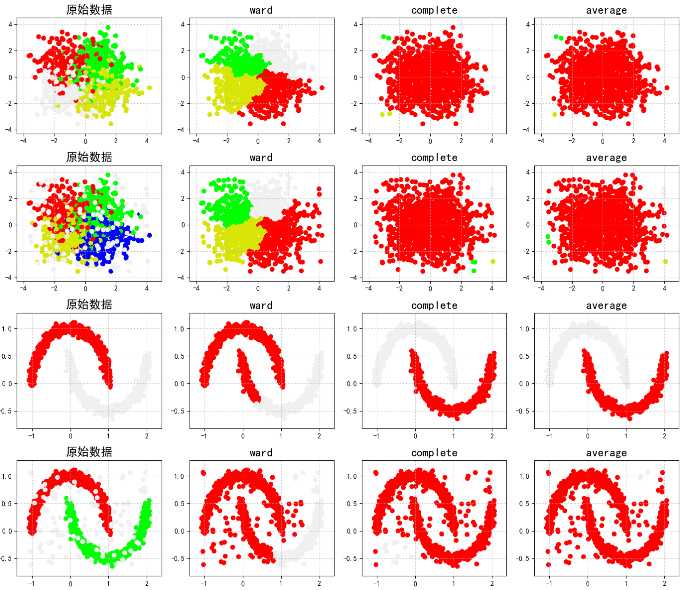
DIANA算法==>采用自顶向下的策略。
divisive(分裂) analysis(分析)
首先将所有对象置于一个簇中,然后按照某种既定的规则逐渐细分为越来越小的簇(比如利用kmeans),直到达到某个终结条件(簇数目或者簇距离达到阈值)。
1,将所有样本数据作为一个簇放到一个队列中2,划分为两个子簇(初始化两个中心点进行聚类),并将子簇添加到队列中3,循环迭代第二步操作,直到中止条件达到(聚簇数量、最小平方误差、迭代次数)
分割点的选择:
各自簇的误差
各自簇的SSE(优选这种策略)
选择样本数据量最多的簇
DIANA类似于分面包

简单,理解容易
合并点/分裂点选择不太容易
合并/分类的操作不能进行撤销(面包切开就合不上了)
大数据集不太适合
执行效率较低O(t*n2),t为迭代次数,n为样本点数
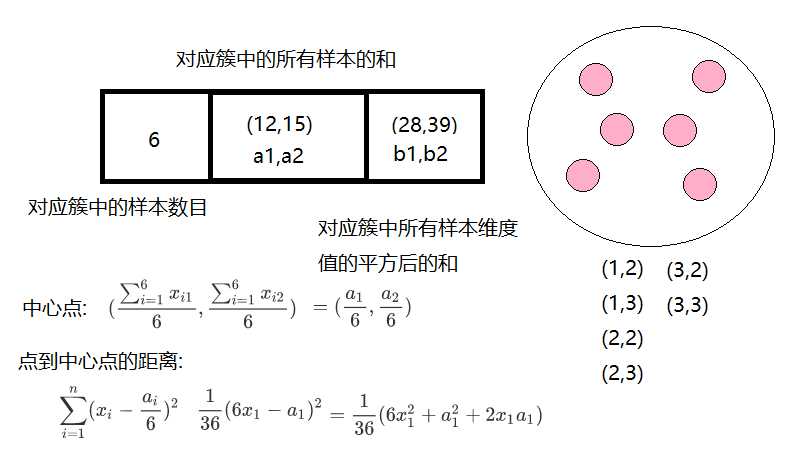
BIRCH算法(平衡迭代削减聚类法):
聚类特征使用3元组进行一个簇的相关信息,通过构建满足分枝因子和簇直径限制的聚类特征树来求聚类,聚类特征树其实是一个具有两个参数分枝因子和类直径的高度平衡树;分枝因子规定了树的每个节点的子女的最多个数,而类直径体现了对这一类点的距离范围;非叶子节点为它子女的最大特征值;
聚类特征树的构建可以是动态过程的,可以随时根据数据对模型进行更新操作。

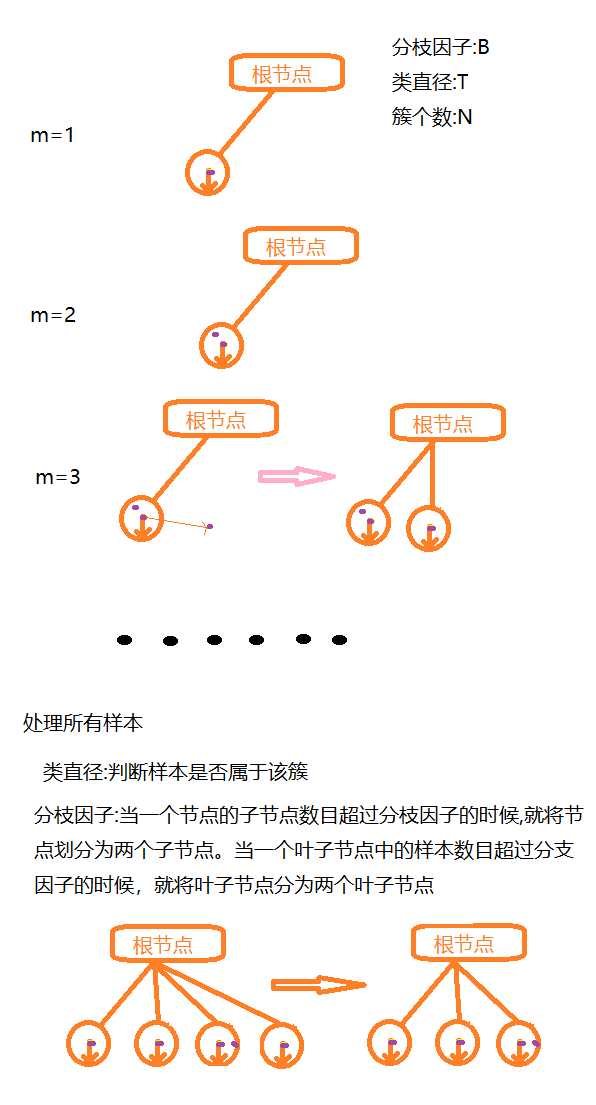
从根节点到叶子节点一层一层的取判断,
优缺点:
适合大规模数据集,线性效率;
只适合分布呈凸形或者球形的数据集、需要给定聚类个数和簇之间的相关参数
代码实现:
库参数:
threshold 类直径
branshing_factor 分支因子
n_clusters 簇个数
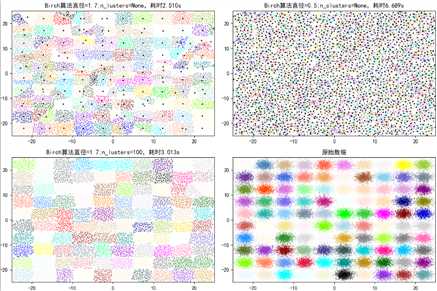
from itertools import cycle from time import time import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import matplotlib.colors as colors ? from sklearn.cluster import Birch from sklearn.datasets.samples_generator import make_blobs ? ## 设置属性防止中文乱码 mpl.rcParams[‘font.sans-serif‘] = [u‘SimHei‘] mpl.rcParams[‘axes.unicode_minus‘] = False ## 产生模拟数据 xx = np.linspace(-22, 22, 10) yy = np.linspace(-22, 22, 10) xx, yy = np.meshgrid(xx, yy) n_centres = np.hstack((np.ravel(xx)[:, np.newaxis], np.ravel(yy)[:, np.newaxis])) # 产生10万条特征属性是2,类别是100,符合高斯分布的数据集 X, y = make_blobs(n_samples=100000, n_features=2, centers=n_centres, random_state=28) # 创建不同的参数(簇直径)Birch层次聚类 birch_models = [ Birch(threshold=1.7, n_clusters=None), Birch(threshold=0.5, n_clusters=None), Birch(threshold=1.7, n_clusters=100) ] # threshold:簇直径的阈值, branching_factor:大叶子个数 ? # 我们也可以加参数来试一下效果,比如加入分支因子branching_factor,给定不同的参数值,看聚类的结果 ## 画图 final_step = [u‘直径=1.7;n_lusters=None‘, u‘直径=0.5;n_clusters=None‘, u‘直径=1.7;n_lusters=100‘] ? plt.figure(figsize=(12, 8), facecolor=‘w‘) plt.subplots_adjust(left=0.02, right=0.98, bottom=0.1, top=0.9) colors_ = cycle(colors.cnames.keys()) cm = mpl.colors.ListedColormap(colors.cnames.keys()) ? for ind, (birch_model, info) in enumerate(zip(birch_models, final_step)): t = time() birch_model.fit(X) time_ = time() - t # 获取模型结果(label和中心点) labels = birch_model.labels_ centroids = birch_model.subcluster_centers_ n_clusters = len(np.unique(centroids)) print("Birch算法,参数信息为:%s;模型构建消耗时间为:%.3f秒;聚类中心数目:%d" % (info, time_, len(np.unique(labels)))) ? # 画图 subinx = 221 + ind plt.subplot(subinx) for this_centroid, k, col in zip(centroids, range(n_clusters), colors_): mask = labels == k plt.plot(X[mask, 0], X[mask, 1], ‘w‘, markerfacecolor=col, marker=‘.‘) if birch_model.n_clusters is None: plt.plot(this_centroid[0], this_centroid[1], ‘*‘, markerfacecolor=col, markeredgecolor=‘k‘, markersize=2) plt.ylim([-25, 25]) plt.xlim([-25, 25]) plt.title(u‘Birch算法%s,耗时%.3fs‘ % (info, time_)) plt.grid(False) ? # 原始数据集显示 plt.subplot(224) plt.scatter(X[:, 0], X[:, 1], c=y, s=1, cmap=cm, edgecolors=‘none‘) plt.ylim([-25, 25]) plt.xlim([-25, 25]) plt.title(u‘原始数据‘) plt.grid(False) ? plt.show()
运行结果:
Birch算法,参数信息为:直径=1.7;n_lusters=None;模型构建消耗时间为:2.510秒;聚类中心数目:171Birch算法,参数信息为:直径=0.5;n_clusters=None;模型构建消耗时间为:6.689秒;聚类中心数目:3205Birch算法,参数信息为:直径=1.7;n_lusters=100;模型构建消耗时间为:3.013秒;聚类中心数目:100
Process finished with exit code 0

CURE算法(使用代表点的聚类法):
该算法先把每个数据点看成一类,然后合并距离最近的类直至类个数为所要求的个数为止。但是和AGNES算法的区别是:取消了使用所有点或用中心点+距离来表示一个类
而是从每个类中抽取固定数量、分布较好的点作为此类的代表点,并将这些代表点乘以一个适当的收缩因子,使它们更加靠近类中心点。
代表点的收缩特性可以调整模型可以匹配那些非球形的场景,而且收缩因子的使用可以减少噪音对聚类的影响。
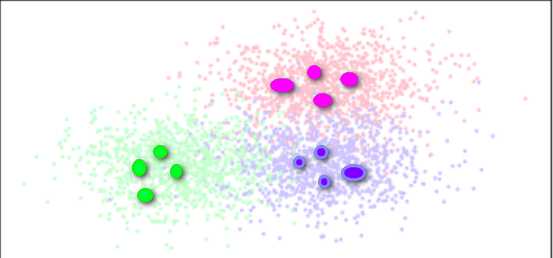

找几个特殊的点来代替整个类别中的样本
优缺点:能够处理非球形分布的应用场景采用随机抽样和分区的方式可以提高算法的执行效率
标签:== 结果 rto ast size datasets 抽取 相关 ges
原文地址:https://www.cnblogs.com/TimVerion/p/11229542.html