标签:range 方法 直接 糗事百科 ike 模拟 sts 实战 并保存
偶然看到了一些项目,有爬取糗事百科的,我去看了下,也没什么难的
首先,先去糗事百科的https://www.qiushibaike.com/text/看一下,
先检查一下网页代码,
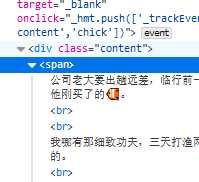
就会发现,需要爬取的笑话内容在一个span标签里,而且父标签是class为content的div里,那就很简单了,用select方法,先找到该文件,然获取下来并保存在txt文件里。比较枯燥。
直接贴代码吧
from bs4 import BeautifulSoup import lxml import requests #url = ‘https://www.qiushibaike.com/text/‘ def spyder(url): try: print(url) #模拟浏览器 kv = {‘user-agent‘:‘Mozilla/5.0‘} r = requests.get(url , headers = kv) #状态码检查,用于 r.raise_for_status() #print(r.text) r.encoding = r.apparent_encoding soup = BeautifulSoup(r.text,‘lxml‘) s = soup.select("div.content>span") data = open(r"qiushi.txt","w", encoding="utf-8") txt = "hello" for i in range(25): txt = s[i].text print(txt) data.write(txt) data.close() except: ("爬取失败") def main(): for i in range(13): url = ‘https://www.qiushibaike.com/text/page/‘ url=url+str(i+1) #print(url) spyder(url) main()4
这段代码能直接爬取13页的内容,不过在保存的时候有个小毛病,只能保存最后的代码,我也懒得去管了,毕竟实现功能了嘛,如果有兴趣可以稍加改动。
在main里,我用了字符串拼接,主要是观察了下他的url的规律,也就避免了“自动翻页”
标签:range 方法 直接 糗事百科 ike 模拟 sts 实战 并保存
原文地址:https://www.cnblogs.com/afei123/p/11234065.html