标签:line hadoop dash hive 加载 流处理 stream 质量 数据表
– 批量数据采集传输sqoop,spark
– 离线数据处理Hadoop,Hive,Spark
– 实时流处理Storm,Spark Streaming,Flink
– 公司业务本身产生和沉淀的数据
– 公司运作产生的数据(如财务、行政)
– 第三方数据:外界购买、交换或者爬虫而来的数据
相关数据管理技术和概念:数据仓库、数据建模、数据质量、数据规范、数据安全和元数据管理
心形模型
维度表:一些属性的字典表 商品信息,
事实表:用户行为
雪花模型
比如说用户年龄,性别 id---》id 姓名,与年龄
统一标准:比如 一个业务部门 删除 0 在线 1 ,另一个 ,删除 N 在线 Y
口径就是常说的 where过滤条件
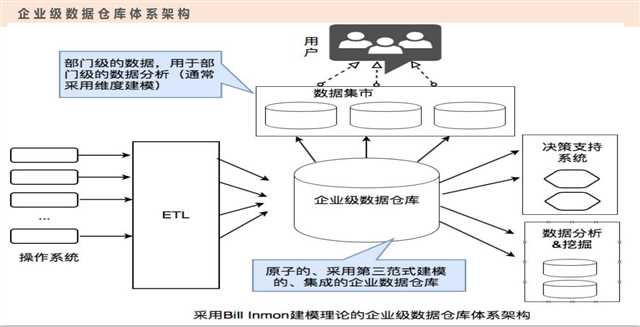
上面的是一个业务线的数据建模
整个大数据部门的数据仓库-------》数据集市{
拉取相关字段建立宽表--------》在宽表的基础-----》各个业务抽取字段形成对应的业务表(机器学习的,数据分析的)-------》统计分析过程(join,或者中间临时表)-----》
}
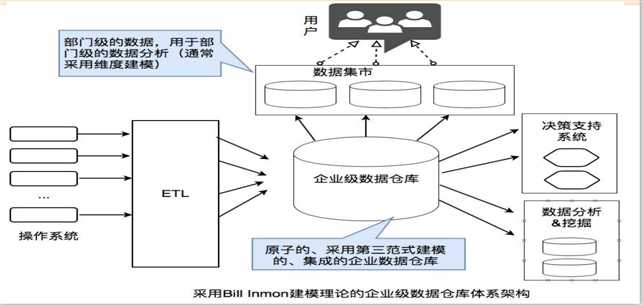
这张 是对于公司所有类型的数据(埋点收集数据,员工数据、业务产品数据)全部存在数据仓库==============》后续分对应部门使用建表
建模---》分层 的好处 :解耦,上游数据对下游影响较小,表的依赖关系去寻找业务问题
ODS(Operational Data Store,操作数据存储):原始数据层,数据源头表通常会原封不动的存储一份。DW层(DWD和DWS层):
DWD(data warehouse detail)明细层
DWS(data warehouse service 汇总层
数据仓库明细层DWD和数据仓库汇总层DWS是数据平台的主要内容。它们是通过ODS层经过ETL清洗、转换、加载生成的,
基于维度建模理论来构建,通过一致性维度和数据总线来保证各个子主题的维度一致性。(就算数据表被删了也可以重新跑 从ODS恢复过来)
ADS(集市数据层,也称应用层):应用层主要是各个业务方或者部门基于DWD和DWS建立的数据集市(DM),数据集市是相对于数据仓库来说的。一般应用层的数据是来源于DW层,原则上是不能访问ODS层的。对比于DW层,应用层只包含部门或业务方自己关心的明细层和汇总层的数据。(一般是将各个要用的表join起来形成宽表,供下游业务分析人员 select * )
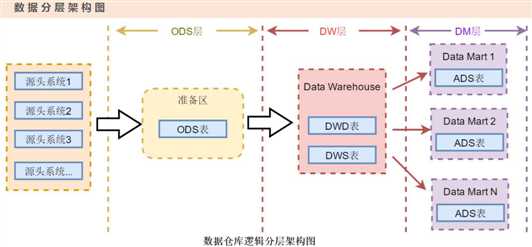
准备区:在hdfs备份一份原始数据
dw:数据仓库,数据开发建模
dm:数据集市应用 多表join的结果
OLTP与OLAP的区别:
OLTP(online transaction Processing) 联机事务处理过程:侧重于单条数据的查新,主要是在关系型数据库上
OLAP联机分析处理:专门的分析性数据库,侧重于批量的数据请求,更加试用于大数据查询处理
列式存储的好处:
对于OLAP 查询都是相关的列,不需要读取整个表所有字段进行处理
对于OLTP 进行增删改查,多半是对整行数据进行操作
标签:line hadoop dash hive 加载 流处理 stream 质量 数据表
原文地址:https://www.cnblogs.com/hejunhong/p/11241656.html