标签:数学 线性 检测 int fast big 上采样 mini 产生
转自:https://www.jianshu.com/p/68844476e975
DenseBox百度IDL的作品,提出的最初动机是为了解决普适的物体检测问题。其在2015年初就被提出来了,甚至比Fast R-CNN还要早,但是由于论文发表的比较晚,虽然算法上非常有创新点,但是依旧阻挡不了Fast R-CNN一统江山。
DenseBox的主要贡献如下:
DenseBox没有使用整幅图作为输入,因为作者考虑到一张图上的背景区域太多,计算时间会严重浪费在对没用的背景区域的卷积上。而且使用扭曲或者裁剪将不同比例的图像压缩到相同尺寸会造成信息的丢失。作者提出的策略是从训练图片中裁剪出包含人脸的patch,这些patch包含的背景区域足够完成模型的训练,详细过程如下:
举例说明:一张训练图片中包含一个 的人脸,那么第一步会裁剪出大小是
的一个patch。在第二步中将这个patch resize到
。这张图片便是训练样本的输入。
通过上面方法采样得到的patch叫做正patch,除了这些正patch,DenseBox还随机采样到了等数量的随机patch,同时使翻转,位移和尺度变换三个数据增强的方法产生样本以增强模型的拟合能力。
训练集的标签是一个 的热图(图1),
表示热图的尺寸,从这个尺寸我们也可以看出训练样本经过了两次降采样。
表示热图的通道数,组成方式如下:



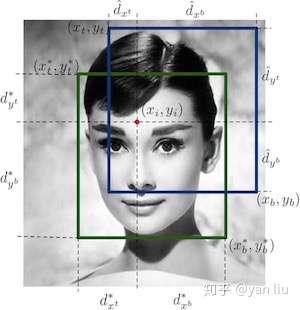
如果训练样本中的人脸比较密集,一个patch中可能出现多个人脸,如果某个人脸和中心点处的人脸的高的比例在 之间,则认为该样本为正样本。
作者认为DenseBox的标签设计是和感受野密切相关的,具体的讲,结合1.2节要分析的网络结构我们可以计算得到热图中每个像素的感受野是 ,这和我们每个patch中每个人脸的尺寸是非常接近的。在DenseBox中,每个像素点有5个预测值,而这5个预测值便可以确定一个检测框,所以DenseBox本质上也是一个密集采样,每个图片的采样个数是
个。
DenseBox使用了16层的VGG-19作为骨干网络,但是只使用了其前12层,如图3所示。
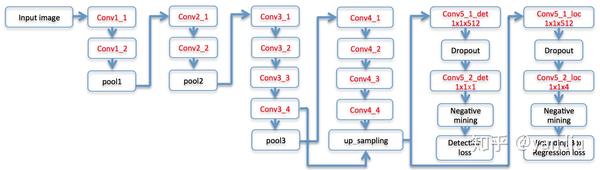
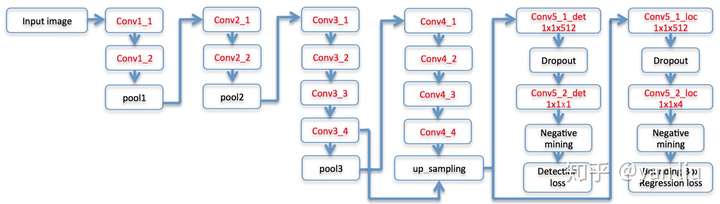
首先需要注意的是在网络的Conv3_4和Conv4_4之间发生了一次特征融合,融合的方式是Conv4_4层的双线性插值上采样,因此得到的Feature Map和Conv3_4是相同的,即为 ,通过计算我们可以得知Conv3_4层的感受野的尺寸是
,该层的尺寸和标签中的人脸尺寸接近,用于捕捉人脸区域的关键特征;Conv4_4层的感受野的大小是
,用于捕捉人脸的上下文特征。
上采样之后网络有两个分支,分别用于计算检测损失和Bounding Box的回归损失,分支由 卷积核Dropout组成。从这里我们看出DenseBox也是一个多任务模型,下面我们开始介绍这个多任务模型。
网络在VGG-19部分的初始化使用的是ImageNet上得到的迁移学习的参数,其余部分使用的是Xavier初始化。
DenseBox的第一个损失为分类损失(检测损失)。在1.1节中我们知道,分类标签 ,设
为模型的预测值。作者使用的是l2损失:
第二个分支是bounding box回归损失,即计算图2中像素点分别到Ground Truth和到预测值之间的l2损失:
在1.1节的最后我们讲到,DenseBox可被视为3600个样本的密集采样,其中每个像素点都可以看做是一个样本。在算法中并不是所有样本都会参与到训练中,且为了平衡正负样本,提高模型精度,DenseBox采用了以下策略。
所谓灰色区域,是指正负样本边界部分的像素点,因为在这些区域由于标注的样本是很难区分的,让其参与训练反而会降低模型的精度,因此这一部分不会参与训练,在论文中,长度小于2的边界部分视为灰色区域。DenseBox使用 对灰色样本进行标注,
表示为灰色区域样本。
DenseBox使用的Hard Negative Mining的策略和SVM类似,具体策略是:
使用上面策略得到的144个样本参与训练,DensoBox使用掩码 对参与训练的样本点进行标注:样本被选中
,否则
。
损失函数使用掩码来控制哪些样本参与训练,其掩码 是由1.4.1节的
和1.4.2节的
共同决定的:
使用掩码后,得到的损失函数如下
其中 为卷积网络的参数,
表示只有正样本参与bounding box的训练,其数学表达式为
是平衡两个任务的参数,论文中值为3。位置
使用的是归一化的值。
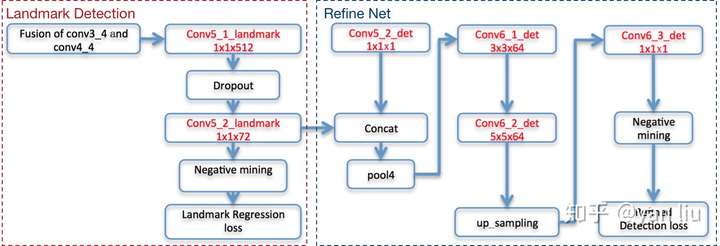
论文中指出当DenseBox加入关键点检测的任务分支时模型的精度会进一步提升,这时只需要在图3的conv3_4和conv4_4融合之后的结果上添加一个用于关键点检测的分支即可,分支的详细结构如图4所示。
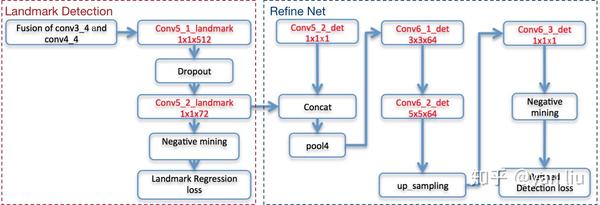
假设样本有 个关键点(在MALF中
),DenseBox的关键点检测的输出是
个热图,热图中的每个像素点表示改点为对应位置关键点的置信度。
关键点的标签值的生成方式也很简单,对于标签集中的第i个关键点 ,在第i个feature map在
处的值是1,其它位置为0,有时也可以以
为圆心将值为1的区域扩展成一个圆,半径为
。
Landmark使用了1.4节中介绍的灰色区域和Hard Negative Mining方法进行采样,损失函数则是使用了采样样本之间的l2损失函数 。整个关键点检测如图4中红色虚线部分所示。
加入关键点检测分支之后,DenseBox根据关键点的置信度图和boudning box的置信度图构成了新的检测损失,并将其命名为Refine Network,如图4的蓝色虚线部分。更详细的讲,Refine Net通过拼接的方式融合了关键点检测的Conv5_2_landmark层和图2中bounding box的Conv5_2_det层,之后接了Max Pooling层,卷积层,上采样层最后生成新的预测值 。Refine Network也是使用了相同的l2损失函数,表示为
。
最终得到的损失函数 是1.4节中的
,关键点检测任务和Refine之后的分类任务的加权和,表示为:
注意 是由检测任务和bounding box定位任务共两个任务组成,因此
本质上是个四任务模型。
和
是平衡各任务的权值,论文中的值分别是1和0.5,更好的策略是根据收敛情况进行调整。
DenseBox的检测过程如图5所示,先考虑不带关键点检测的流程:
DenseBox在今天看来技术性依旧非常强,虽然作为一个人脸检测的论文被发表,但是其思想也可以迁移到通用的物体检测中。而且得到的效果几乎和Faster R-CNN旗鼓相当。由于采用了FCN的架构,DenseBox本身的速度应该不会太慢,唯一的性能瓶颈应该是图像金字塔的引入。在之后的研究中,DenseBox通过SPP-Net中的金字塔池化的方式将检测时间优化到了GPU的实时。本来DenseBox在物体检测中能有更大的价值的,但是由于其仅限于百度内部使用,并没有开源,论文投稿也比较晚造成了R-CNN系列的一统天下。当然R-CNN系列凭借其代码的规范性,算法的通用性等优点一统天下也不意外。
[1] Qin H, Yan J, Li X, et al. Joint training of cascaded cnn for face detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 3456-3465.
标签:数学 线性 检测 int fast big 上采样 mini 产生
原文地址:https://www.cnblogs.com/leebxo/p/11244040.html