标签:plot 创建 http dtree print ref dea for 矩阵
K临近分类是一种监督式的分类方法,首先根据已标记的数据对模型进行训练,根据模型对新的数据点进行预测,预测新数据的标签(label),也就是该数据所属的分类。
使用KNeighborsClassifier创建K临近分类器:
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30,
p=2, metric=’minkowski’, metric_params=None, n_jobs=None, **kwargs)
参数注释:
1,n_neighbors
临近的节点数量,默认值是5
2,weights
权重,默认值是uniform,
3,algorithm
4,leaf_size
leaf_size传递给BallTree或者KDTree,表示构造树的大小,用于影响模型构建的速度和树需要的内存数量,最佳值是根据数据来确定的,默认值是30。
5,p,metric,metric_paras
6,n_jobs
并发执行的job数量,用于查找邻近的数据点。默认值1,选取-1占据CPU比重会减小,但运行速度也会变慢,所有的core都会运行。
7,举个例子
下面的代码是最简单的knn分类器,可以看出,knn分类模型是由两部分构成的:第一部分是训练数据(fit),第二部分是预测数据(predict)
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
x_train = [[0], [1], [2], [3]]
y_train = [0, 0, 1, 1]
knn.fit(x_train,y_train)
x_new=[[1.1]]
pred=knn.predict(x_new)
print(‘pred:{0}‘.format(pred))
由于knn分类是监督式的分类方法之前,在构建一个复杂的分类模型之前,首先需要已标记的数据集。我们可以从sklearn的数据集中加载已有的数据进行学习:
from sklearn.datasets import load_iris iris_dataset=load_iris()
查看iris_dataset的数据,该对象的结构和字典非常类型:
>>> iris_dataset.keys() dict_keys([‘data‘, ‘target‘, ‘target_names‘, ‘DESCR‘, ‘feature_names‘, ‘filename‘])
1,样本数据
data 是样本数据,共4列150行,列名是由feature_names来确定的,每一列都叫做矩阵的一个特征(属性),前4行的数据是:
>>> iris_dataset.data[0:4] array([[5.1, 3.5, 1.4, 0.2], [4.9, 3. , 1.4, 0.2], [4.7, 3.2, 1.3, 0.2], [4.6, 3.1, 1.5, 0.2]])
2,标签
target是标签,用数字表示,target_names是标签的文本表示
>>> iris_dataset.target[0:4] array([0, 0, 0, 0]) >>> iris_dataset.target_names array([‘setosa‘, ‘versicolor‘, ‘virginica‘], dtype=‘<U10‘)
3,查看数据的散点图
查看数据的散点图矩阵,按照数据的类别进行着色,观察数据的分布:
import pandas as pd import mglearn iris_df=pd.DataFrame(x_train,columns=iris_dataset.feature_names) pd.plotting.scatter_matrix(iris_df,c=y_train,figsize=(15,15),marker=‘o‘,hist_kwds={‘bins‘:20} ,s=60,alpha=.8,cmap=mglearn.cm3)
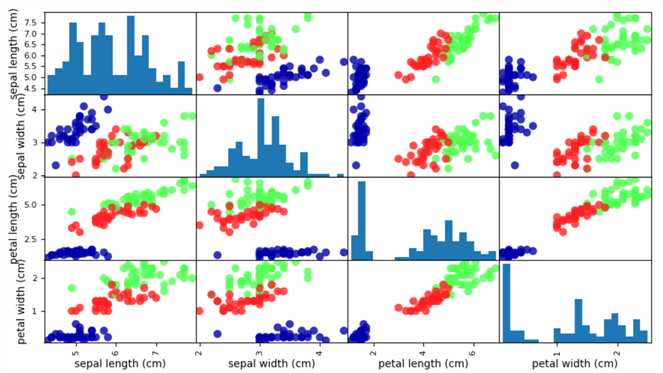
我们使用sklearn数据集中的鸢尾花测量数据来构建一个复杂的分类模型,并根据输入的数据点来预测鸢尾花的类别。
1,拆分数据
把鸢尾花数据拆分为训练集和测试集:
from sklearn.model_selection import train_test_split x_train,x_test,y_train,y_test=train_test_split(iris_dataset[‘data‘],iris_dataset[‘target‘],random_state=0)
2,创建分类器
使用KNeighborsClassifier创建分类器,设置参数n_neighbors为1:
from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier(n_neighbors=1)
3,使用训练集来构建模型
对于监督学习,训练数据集包括两部分:输入和结果(Lable),每一行输入都对应一行结果,结果是输入的正确分类(标签)。
通常,记X_train是训练的输入数据集,X_train对应的结果是y_train,是训练数据集的输出,通过fit()函数来训练模型,构建模型:
knn.fit(x_train, y_train)
4,预测新数据
对于训练之后的模型,使用predict()函数来预测数据的结果。
x_new=np.array([[5, 2.9, 1, 0.2]]) prediction= knn.predict(x_new) print("prediction :{0} ,classifier:{1}".format(prediction,iris_dataset["target_names"][prediction]))
5,评估模型
使用训练集和测试集来评估模型:
y_pred=knn.predict(x_test) assess_model_socre=knn.score(x_test,y_test) print(‘Test set score:{:2f}‘.format(assess_model_socre))
参考文档:
sklearn.neighbors.KNeighborsClassifier
标签:plot 创建 http dtree print ref dea for 矩阵
原文地址:https://www.cnblogs.com/ljhdo/p/10600613.html