纵观业界的电商网站,我站在一个用户的角度来看,商品推荐有很多种:
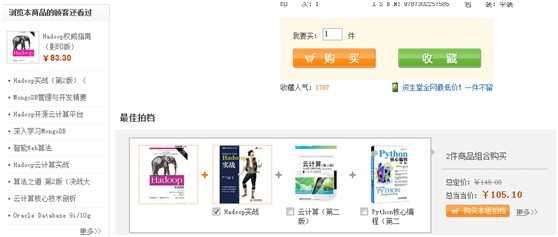
一种是通过我搜索、查看的那件商品的,系统统计出搜索、查看该商品的其他用户搜索、查看其他商品的次数,把排名靠前的推荐给我,当当的一个栗子:
我查看了《Hadoop 权威指南》,系统给我推荐了一堆其他的书:
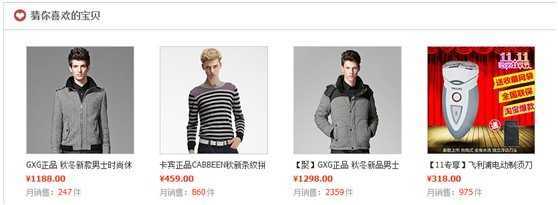
一种是通过我最近的搜索、查看过商品,系统给我推荐一些它认为我感兴趣的商品,淘宝的一个栗子:
还有几种,感觉挺有意思的:

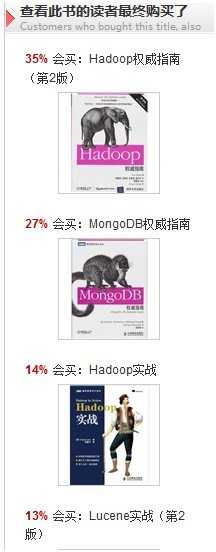

特别是这个,搜索Hadoop 的用户,最终很多人都买了羽绒服,这是为什么呢?学习hadoop 的筒子们都很怕冷么?还是说,北方人居多?

- 五花八门哈,别的不管了。只讨论下第一种,个人YY设计下:基于Hbase的一个简单的商品推荐系统。
- 撇开其他的流程不说,单就这个推荐而言,基于Hbase的设计,两张表就OK了。一张表user_item记录每个用户查看了的所有商品,item_user记录查看了某个商品的所有用户。
- user_item:userid作为行健,列簇和列为item:itemid,数据如下:
- user1 item:itemid timestamp=1234567891, value=item1
- user1 item:itemid timestamp=1234567892, value=item2
- user1 item:itemid timestamp=1234567893, value=item3
- user2 item:itemid timestamp=1234567894, value=item4
- user2 item:itemid timestamp=1234567895, value=item5
- user3 item:itemid timestamp=1234567881, value=item1
- user3 item:itemid timestamp=1234567832, value=item2
- user4 item:itemid timestamp=1234567843, value=item3
- user4 item:itemid timestamp=1234567854, value=item4
- user4 item:itemid timestamp=1234567895, value=item5
- ......
- item_user:itemid作为行健,列簇和列为:user:userid,数据如下:
- item1 user:userid timestamp=1234567891, value=user1
- item1 user:userid timestamp=1234567892, value=user2
- item1 user:userid timestamp=1234567893, value=user4
- item2 user:userid timestamp=1234567894, value=user3
- item3 user:userid timestamp=1234567895, value=user2
- item3 user:userid timestamp=1234567881, value=user4
- item6 user:userid timestamp=1234567832, value=user5
- item6 user:userid timestamp=1234567843, value=user6
- item8 user:userid timestamp=1234567854, value=user5
- item8 user:userid timestamp=1234567895, value=user4
- ......
- 大概的业务是:我查看《Hadoop权威指南》(item1)时,系统从item_user表中以item1作为行健查询出所有查看过item1的用户,再分别以各userid为行健,从user_item表中查询出所有查看过的商品,最后去重、统计、排序并显示。
http://f.dataguru.cn/thread-33415-1-1.html