标签:ima 索引 模仿 技术 baidu 贵阳大数据 gen 通过 image
1.网络爬虫:抓取网络数据的程序
用python程序模仿人去访问网站,逼真度越真越好
可以用来爬取有价值的数据
2.企业获取数据的方式
1 自有数据 比如 自家职员信息表格等
2 第三方数据平台购买 数据堂、贵阳大数据交易所
3 爬虫爬取数据
3.其他语言也可以做爬虫
如PHP,JAVA,C、C++
4、爬虫分类
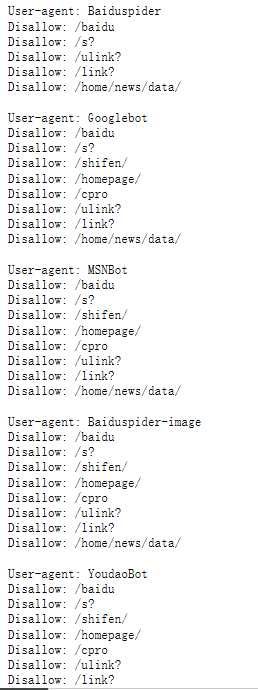
1、通用网络爬虫 搜索引擎使用,需要遵守 robots协议。
如何查看一个搜索引擎的robots协议?
输入 网站/robots.txt,如:www.baidu.com/robots.txt 、www.taobao.com/robots.txt
这是百度的
至于到底是什么,咱也不知道,咱也不敢问
Allow:允许爬取的内容
Disallow:不允许爬取的内容
User-agent:后面是各大佬的爬虫
搜索引擎如何获取一个新网站的URL?
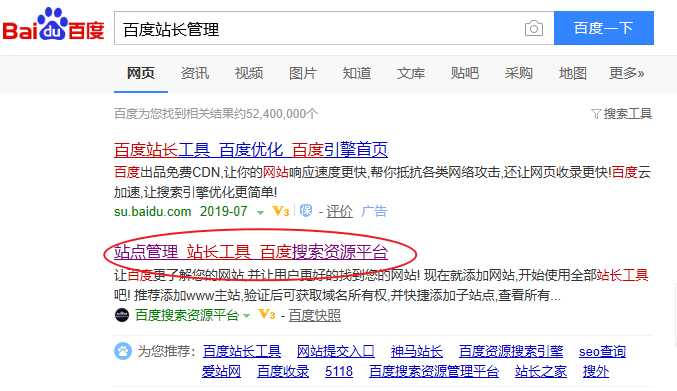
1.由新网站自己提供(百度站长平台)
在有一个新网站后,搜索“百度站长管理”
登录账号后面一通操作,最终会让百度爬虫知道网站。
2.百度和DNS服务商(万网)合作,快速收录
2.聚焦网络爬虫
自己写的爬虫程序:面向需求的爬虫
很多网站很反感爬虫程序,因为会增大服务器的压力,所以很多网站会反爬虫。所以要反反爬虫,让它觉得你是个人。一般是反反爬虫的一方胜利,反爬虫的一般是一些网站运维,还有很多其他的事情要做。一般做到 “以后此ip没法再访问这个网站” 就差不多了。
5 爬取数据的步骤
1.确定要爬取的URL地址
2.通过HTTP/HTTPS协议获取相应的HTML页面
3.提取HTML页面有用的数据
1.所需数据,保存
2.页面还有其他URL,继续 第二步
查看 搜索引擎的robots协议 及其他 爬虫基础-2
标签:ima 索引 模仿 技术 baidu 贵阳大数据 gen 通过 image
原文地址:https://www.cnblogs.com/Gaber/p/11263236.html