标签:图计算 gty 一站式 生态圈 amp ext ogg inf 发布
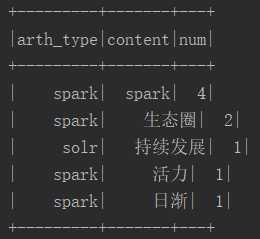
1 package big.data.analyse.tokenizer 2 3 import com.hankcs.hanlp.HanLP 4 import com.hankcs.hanlp.tokenizer.StandardTokenizer 5 import org.apache.log4j.{Level, Logger} 6 import org.apache.spark.sql.{SQLContext, Row} 7 import org.apache.spark.sql.catalyst.expressions.StringToMap 8 import org.apache.spark.sql.types.{IntegerType, StringType, StructType, StructField} 9 import org.apache.spark.{SparkContext, SparkConf} 10 11 /** 12 * spark中使用Hanlp分词器 13 * Created by zhen on 2019/5/30. 14 */ 15 object HanlpTokenizer { 16 /** 17 * 设置日志级别 18 */ 19 Logger.getLogger("org").setLevel(Level.WARN) 20 def main(args: Array[String]) { 21 val conf = new SparkConf() 22 .setAppName("HanlpTokenizer") 23 .setMaster("local[2]") 24 25 val sc = new SparkContext(conf) 26 27 val sqlContext = new SQLContext(sc) 28 val array : Array[String] = Array("spark-spark发布2.4版本,性能提升巨大,spark生态圈日渐完善", 29 "spark-sparkML机器学习是spark生态圈的重要组成部分,为spark一站式开发注入了强大的活力", 30 "机器学习-随着spark的快速发展,Hadoop的速度难以望其项背,特别是在机器学习和图计算方面,差距更少巨大", 31 "solr-搜索引擎老而弥坚,随着solrcloud的持续发展,在数据量不是特别巨大的情形下,还是具有很多先天优势的", 32 "solr-ES是对solr冲击最为严重的一种技术") 33 34 val termRdd = sc.parallelize(array).map(row => { // 标准分词,挂载Hanlp分词器 35 var result = "" 36 val type_content = row.split("-") 37 val termList = StandardTokenizer.segment(type_content(1)) 38 for(i <- 0 until termList.size()){ 39 val term = termList.get(i) 40 //if(!term.nature.name.contains("w") && !term.nature.name().contains("u") && term.nature.name().contains("m")){ 41 if(term.word.length > 1){ 42 result += term.word + " " 43 } 44 //} 45 } 46 Row(type_content(0),result) 47 }) 48 49 val structType = StructType(Array( 50 StructField("arth_type", StringType, true), 51 StructField("content", StringType, true) 52 )) 53 54 val termDF = sqlContext.createDataFrame(termRdd,structType) 55 56 /** 57 * 列转行 58 */ 59 val termCheckDF = termDF.rdd.flatMap(row =>{ 60 val arth_type = row.getAs[String]("arth_type") 61 val content = row.getAs[String]("content") 62 var res = Seq[Row]() 63 val content_array = content.split(" ") 64 for(con <- content_array){ 65 res = res :+ Row(arth_type,con, 1) 66 } 67 res 68 }).collect() 69 70 /** 71 * 重新转成df 72 */ 73 val structType2 = StructType(Array( 74 StructField("arth_type", StringType, true), 75 StructField("content", StringType, true), 76 StructField("num", IntegerType, true) 77 )) 78 79 val termListDF = sqlContext.createDataFrame(sc.parallelize(termCheckDF), structType2) 80 81 /** 82 * 注册临时视图 83 */ 84 termListDF.createOrReplaceTempView("termListDF") 85 86 /** 87 * 分组求和 88 */ 89 val result = sqlContext.sql("select arth_type,content,sum(num) num " + 90 "from termListDF group by arth_type,content order by num desc") 91 92 result.count() 93 result.show(5) 94 95 sc.stop() 96 } 97 }
标签:图计算 gty 一站式 生态圈 amp ext ogg inf 发布
原文地址:https://www.cnblogs.com/yszd/p/11266552.html