标签:map hda als hadoop center com bin 缩进 unp
YAML 语言的设计目标,就是方便人类读写。它实质上是一种通用的数据串行化格式。
它的基本语法规则如下。
• 大小写敏感
• 使用缩进表示层级关系
• 缩进时不允许使用Tab键,只允许使用空格。
• 缩进的空格数目不重要,只要相同层级的元素左侧对齐即可
YAML支持的数据结构有三种。
• 对象(Object):键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
• 数组(Aarry):一组按次序排列的值,又称为序列(sequence) / 列表(list)
• 纯量(scalars):单个的、不可再分的值
以K8s中的示例来说明对象和数组:
apiVersion: apps/v1 #这是一个对象,key:value,这种形式的键值对,在yaml中就称为对象,也可以叫字典 或 映射(map).
kind: ReplicaSet #这也是对象
metadata: #对象可以是多个k:v 组合,这就是一个多k:v组合的对象。
name: myapp
namespace: default
spec: #它也是对象,它更复杂点,它是复合型的对象
replicas: 2
selector:
matchLabels:
app: myapp
release: canary
template:
metadata:
name: myapp-pod
labels:
app: myapp
release: canary
environment:qa
spec:
containers: #它的帮助信息中显示,它的类型为: <[]Object> ,但Yamy中,
#它实际上是一个对象类型,但这个对象的值是一个数组类型。
- name: myapp-container #这是一个多属性的数组,即一个数组有多个元素组成。
image: busybox
ports: #它和containers一样。也是一个对象类型,但值(value)是数组类型.
- name:http #注意: 数组是以"-"开头的.
containerPort: 80
- name: https
containerPort: 443
#对象数组类型比较容易混乱,我将其转化为单行形式的:【注意: YAML语法中,这种单行形式,称为流式(flow)语法】
ports: [ {name: http, containerPort: 80 }, {name:https, containerPort: 443} ]
这样看就可以很容易看到: ports: VALUE 个格式, 但这个VALUE是一个数组,
而数组内部,每一个元素又是一个对象,因为name:http 其实就是K:V,所有它就是一个对象。
和对象相对应的是值,即单个字符串: 如下面的数组的示例。
#这里需要注意,数组还有一种形式是:
ports:
-
name: http
containerPort: 80
-
name: https
containerPort: 443
这样写,也表示"-" 下面的是数组的组成元素。YAML语法是需要使用空格对齐的!
#在YAML中表示一个这样的数组: [Nginx, Hadoop, Apache]
#就可以这样写:
- Nginx
- Hadoop #像这样单个字符串Hadoop,就是一个值,对象是K:V组合,因此要区分开。
- Apache
还需要强调:
关于对齐,YAML要求,同级别要对齐,不同级别错位时,至少错开一个空格,产生上下级层次,即可,没有规定必须空出多少个空格。
对于数组对象,因为它是以"-"横线开头,因此横线可与上层持平,也不算错,当然错开也是可以的。
YAML语法中在同一个文件中写多个配置段的语法:
server:
address: 192.168.1.100
--- #在YAML格式中,使用三个横线("---")表示一个配置段的开始.
spring:
profiles: development
server:
address: 127.0.0.1
---
spring:
profiles: production
server:
address: 192.168.1.120
YAML中在同一个文件中,写两个YAML文件的语法
#yaml文档1
--- #三个横线表示文档开始
time: 20:03:20
player: Sammy Sosa
action: strike (miss)
... #三个点表示文档结束
#yaml文档2
---
time: 20:03:47
player: Sammy Sosa
action: grand slam
...
s1: ‘内容\n字符串‘
s2: "内容\n字符串"
用JavaScript表示:
{ s1: ‘内容\\n字符串‘, s2: ‘内容\n字符串‘ },可以看到,单引号会转义特殊字符,而双引号不会转义特殊字符.
str: ‘labor‘‘s day‘
用JavaScript表示:
{ str: ‘labor\‘s day‘ },从这个示例中,可以看到,双写单引号,可以起到转义后一个单引号的目的。
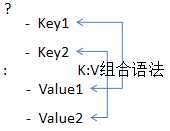
下面是一种数组的另一种写法
意思即对象的属性是一个数组[key1, key2],对应的值也是一个数组[Value1, Value2]
boolean:
- TRUE #true,True都可以
- FALSE #false,False都可以
float:
- 3.14
- 6.8523015e+5 #可以使用科学计数法
int:
- 123
- 0b1010_0111_0100_1010_1110 #二进制表示
null:
nodeName: ‘node‘
parent: ~ #使用~表示null
string:
- 哈哈
- ‘Hello world‘ #可以使用双引号或者单引号包裹特殊字符
- newline
newline2 #字符串可以拆成多行,每一行会被转化成一个空格
date:
- 2018-02-17 #日期必须使用ISO 8601格式,即yyyy-MM-dd
datetime:
- 2018-02-17T15:02:31+08:00 #时间使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区
picture: !!binary | # Base64 编码的图片数据. 这里的"|",是YAML语法中的表示保留换行符的符号.
R0lGODlhDAAMAIQAAP//9/X #与"|" 相对的是 ">", 它表示 折叠换行,即 不保留换行符, 换行符会被替换为空格.
17unp5WZmZgAAAOfn515eXv #关于是否保留换行符,还有"|+" 和 “|-”参考下面
Pz7Y6OjuDg4J+fn5OTk6enp #注意:Base64编码在书写时,每行的前面必须有一个空格!!
56enmleECcgggoBADs=
string:
- !!str 54321 #这种就是将int类型转换为字符串类型. 需要使用两个叹号,即可。
- !!str true
str: 这是一段
多行
字符串
用JavaScript表示: { str: ‘这是一段 多行 字符串‘ } ,换行符为替换为空格了。
this: |
Foo
Bar
用JavaScript表示: {this: ‘Foo\nBar\n‘} ,可以看到每个换行符都保留了。
s2: |+
Foo
abc
用JavaScript表示: {s2: ‘Foo\nabc\n\n‘}, 可看到,它保留了原始文本中的换号符,解析后还加入了一个换行符.
s3: |-
Foo
abc
用JavaScript表示: {s3: ‘Foo\nabc},减号,就表示删除文本块末尾的换行符.
that: >
Foo
Bar
用JavaScript表示: {that: ‘Foo Bar\n‘},这个可以看到,折叠换行就是,只保留文本块末尾的换行符.
注意: ">",也支持">-" 和 ">+" 以上和上面一样。
示例1
hr:
- Mark McGwire
- &SS Sammy Sosa #创建了一个锚点叫SS, 其值为:Sammy Sosa
rbi:
- *SS #引用一个已经定义的锚点SS,这样就引用了SS的值 Sammy Sosa。
- Ken Griffey
用JavaScript语法: {rbi: [Sammy Sosa, Ken Griffey], hr: [Mark McGwire, Sammy Sosa]}
另一种定义方法:
SS: &SS Sammy Sosa #先定义一个对象,Key是SS,Value是一个锚点
hr:
- Mark McGwire
- *SS #这里引用锚点SS.得到的结果和上面一样。
rbi:
- *SS
- Ken Griffey
示例2
defaults: &defaults #定义了一个锚点:叫defautls
adapter: postgres
host: localhost
development:
database: myapp_development
<<: *defaults #这里引用了defaults描点的值,并使用"<<"表示将其合并到当前对象(Object)或叫映射(map)中。
test:
database: myapp_test
<<: *defaults
合并后的结果,就相当于:
defaults:
adapter: postgres
host: localhost
development:
database: myapp_development
adapter: postgres
host: localhost
test:
database: myapp_test
adapter: postgres
host: localhost
示例3:
merge:
- &CENTER { x: 1, y: 2 }
- &LEFT { x: 0, y: 2 }
- &BIG { r: 10 }
- &SMALL { r: 1 }
sample1:
<<: *CENTER
r: 10
sample2:
<< : [ *CENTER, *BIG ]
other: haha
sample3:
<< : [ *LEFT, *BIG ]
r: 100
合并就相当于下面:
sample1:
x: 1
y: 2
r: 10
sample2:
x: 1
y: 2
r: 10
other: haha
sample3:
x: 0
y: 2
r: 100 #sample3还引入了BIG,它的值是r:10,但sample3中已经有r:100了,因此引入后,sample3原始值会覆盖引入的r:10.
标签:map hda als hadoop center com bin 缩进 unp
原文地址:https://www.cnblogs.com/wn1m/p/11286109.html