标签:hashcode object void 优先 axel 特点 size 排列 删除
关于HashMap的数据结构:采用散列表的数据结构,链表+数组,数组Array,所存储的元素并非基本数据类型,而是Entry(内含键值对),包括的数据域(键,值,next),
其计算方法:
key.hashcode()%Array[].length
HashMap虽然是一个很好用的集合,但是而有一个问题,那就是在对HashMap进行迭代访问的过程中,添加元素的顺序可能会和访问的数据不一样,这个时候我们可以选择LinkedHashMap
LinkedHashMap继承了HashMap,是其子类,但与之不同的是,增加了一个双向链表来实现元素迭代的顺序,但是肯定会增加时间和空间的消耗
既然继承了HashMap,那么也是非线程安全的
LinkedHashMap的特点:
1.LinkedHashMap的输入和输出顺序一致
2.key和value可以同时为空
3.key可以重复,但是新的key对应的value值会覆盖掉旧value值(这点和HashMap的哈希桶下元素存放规则相似)
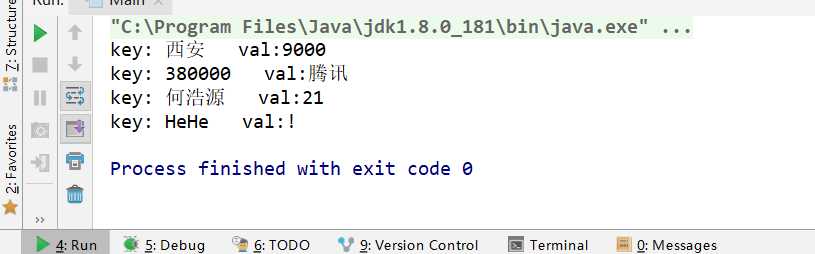
import java.util.LinkedHashMap; import java.util.Map; class Main { public static void main(String[] args) { LinkedHashMap<String,Object> map = new LinkedHashMap<>(); map.put("西安",9000); map.put("380000","腾讯"); map.put("何浩源",21); map.put("HeHe",‘!‘); for (Map.Entry entry : map.entrySet()){ System.out.println("key: "+entry.getKey()+" val:"+ entry.getValue()); } } }
LinkedHashMap内部的数据结构也是Entry,它是LinkedHashMap的内部类,并在此基础之上添加了两个别的元素,before 和 after,用于维护链表中Entry的前一个元素和后一个元素
LinkedHashMap的实现就是 HashMap+LinkedList 的实现方式,用HashMap维护数据结构,用LinkedList的方式维护数据插入顺序
反向迭代:
import java.util.*; class Test8 { public static void main(String[] args) { Map<String,Object> linkedHashMap = new LinkedHashMap<>(16); for (int i = 0; i < 5; i++) { linkedHashMap.put(i + "", i); } for (Map.Entry entry : linkedHashMap.entrySet()) { System.out.println("key:" + entry.getKey() + ",value:" + entry.getValue()); } System.out.println("============================"); // 使用的是迭代器 ListIterator ListIterator<Map.Entry> i= new ArrayList<Map.Entry>( linkedHashMap.entrySet()).listIterator(linkedHashMap.size()); while(i.hasPrevious()) { Map.Entry entry=i.previous(); System.out.println("key:" + entry.getKey() + ",value:" + entry.getValue()); } } }
http://www.cnblogs.com/xrq730/p/5030920.html
解释一下LRU:LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。
要实现这个功能,就是要记录那些元素被访问了,访问的元素应该向前排列,当然这个功能LinkedHashMap已经帮我们实现了,
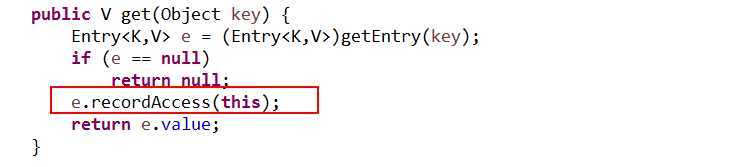
注意红框的部分, recordAccess,就是将当前entry移动到链表的最前面。
前面说了,LinkedHashMap添加新的元素时会执行删除eldest entry,虽然LinkedHashMap没有实现,但是我们可以重写removeEldestEntry的方法来实现这个功能。
public class LRUCache extends LinkedHashMap { public LRUCache(int maxSize) { super(maxSize, 0.75F, true); maxElements = maxSize; } protected boolean removeEldestEntry(java.util.Map.Entry eldest) { return size() > maxElements; } private static final long serialVersionUID = 1L; protected int maxElements; }
当元素的个数大于指定的值时,就会有原始数据被删除掉,也就是链表最后的元素。
标签:hashcode object void 优先 axel 特点 size 排列 删除
原文地址:https://www.cnblogs.com/hetaoyuan/p/11291472.html