标签:总计 pagerduty 查看 定位 预测 代理服务器 规则组 直接 instr
DevOps工程师或SRE工程师,可能都知道Prometheus普罗米修斯。Prometheus于2012年由SoundCloud创建,目前已经已发展为最热门的分布式监控系统。Prometheus完全开源的,被很多云厂商(架构)内置,在这些厂商(架构)中,可以简单部署Prometheus,用来监控整个云基础架构设施。比如DigitalOcean或Docker都是普罗米修斯作为基础监控。
希腊神话中,普罗米修斯是最具智慧的神明之一,是泰坦巨神后代,其名字意思为"先见之明",那么以该名字命名的监控系统究竟怎么样呢?今天虫虫给大家讲讲这个以神之名命名的监控系统。
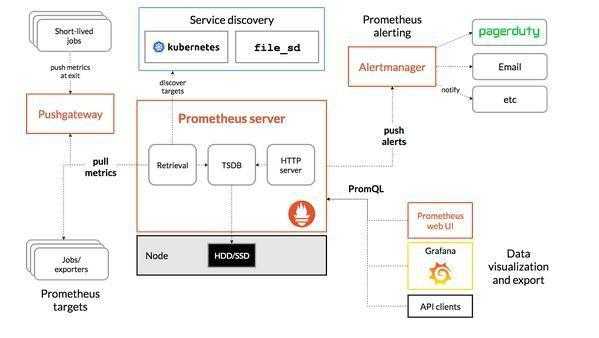

普罗米修斯(Prometheus)介绍
Prometheus是一个时间序列数据库。但是,它不仅仅是一个时间序列数据库。
它涵盖了可以绑定的整个生态系统工具集及其功能。
Prometheus主要用于对基础设施的监控。包括服务器,数据库,VPS,几乎所有东西都可以通过Prometheus进行监控。Prometheus希望通过对Prometheus配置中定义的某些端点执行的HTTP调用来检索度量标准。
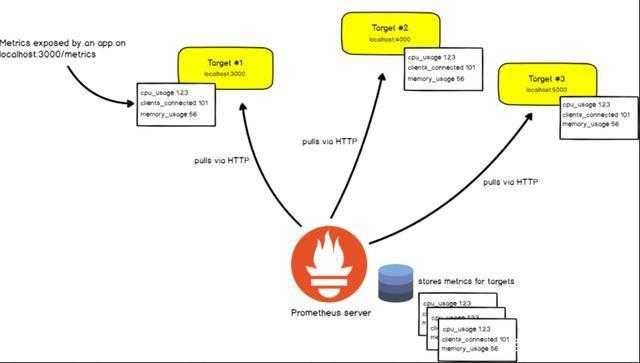

例如,如果我们以localhost:3000的Web应用程序为例,你的应用程序将在特定URL(例如localhost:3000/metrics)中将指标公开为纯文本。以该URL为起点,,在给定的有效期间隔期间,Prometheus将从该目标中提取数据。
工作原理?
如前所述,Prometheus由各种不同的组件组成。其监控指标可以从系统中提取到,可以通过不同的方式做到:
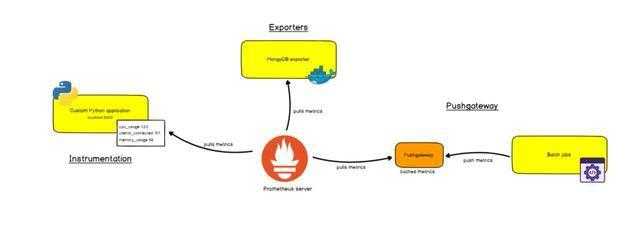
通过应用程序给定监控项,对给定的公开URL上Prometheus兼容的指标。Prometheus将其定义为目标并加入监控系统。
通过使用云厂商内置Prometheus程序,会定义好整个监控项和监控工具集拥。例如,可以 Linux机器监控模版(节点导出器),数据库的模版(SQL导出器或MongoDB导出器),以及HTTP代理或者负载程序的模版(例如HAProxy导出器)等这些模版直接就可以加入监控并使用。
通过使用Pushgateway:应用程序或作业不会直接公开指标。某些应用程序要么没有合适的监控模版(例如批处理作业),对他们选择不能直接通过应用程序公开这些指标。如果我们忽略您可能使用Pushgateway的极少数情况,Prometheus是一个基于主动请求pull的监控系统。

推方式和拉方式
Prometheus与其他时间序列数据库之间存在明显差异:Prometheus主动筛选目标,以便从中检索指标。这与InfluxDB非常不同,InfluxDB是需要直接推送数据给它。
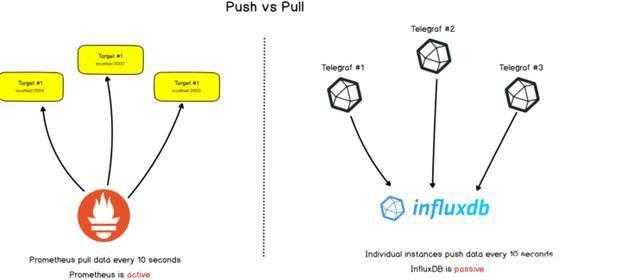

基于推和基于拉方式各有其优劣之处。Prometheus使用主动拉方式主要的基于以下考虑:
实现集中控制:如果Prometheus向其目标发起查询,则整个配置在Prometheus服务器端完成,而不是在各个目标上完成。Prometheus决定取值,以及取值的的频率。
使用基于推的系统,可能会导致向服务器发送过多数据的风险,这时会使其服务器崩溃。基于拉的系统能够实现速率控制,具有多级过期配置的灵活性,因此可以针对不同目标实现多种速率。
存储汇总的指标
Prometheus不是基于事件的系统,这与其他时间序列数据库不同。Prometheus并非旨在及时捕获单个和时间事件(例如服务中断),但它旨在收集有关的服务的预先汇总的指标。具体而言,它不会从Web服务发送404错误消息以及错误的消息的具体内容,而是对这些消息做处理、聚合过的指标。这与其他在收集"原始消息"的时间序列数据库之间的基本差异
生态系统
Prometheus的主要功能仍然是时间序列数据库。但是,在使用时间序列数据库时,对它们实现了可视化、数据分析并通过自定义方式进行告警。
Prometheus生态系统有功能丰富工具集:
Alertmanager:Prometheus通过配置文件中定义的自定义规则将告警信息推送到Alertmanager。Alertmanager可以将其导出到多个端点,例如Pagerduty或Slack等。
数据可视化:与Grafana、Kibana等类似,可以直接在Web UI中可视化时间序列数据。轻松过滤查看了不通监控目标的信息。
服务发现:Prometheus可以动态发现监控目标,并根据需要自动废弃目标。这在云架构中使用动态变更地址的容器时,尤为方便。
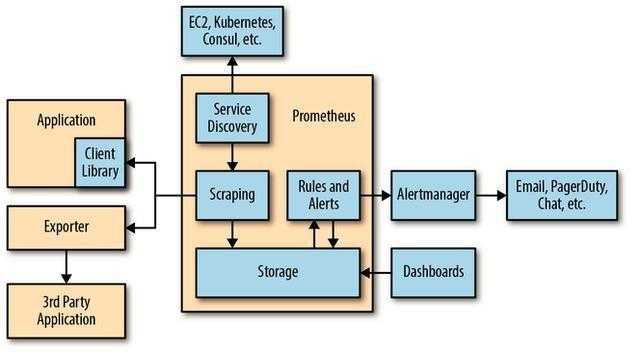

普罗米修斯技术原理和构成
关键值数据模型
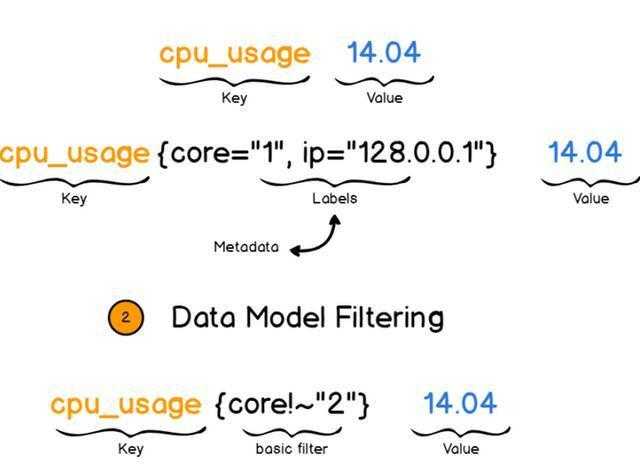
在开始使用Prometheus工具之前,了解数据模型非常重要。Prometheus使用键值对。键描述了测量值时将实际测量值存储为数字的值。

注意:Prometheus并不会存储原始信息,如日志文本,它存储的是随时间汇总的指标。
一般来说键也就监控度量。比如CPU使用百分比或内存使用量等。但是,如果想要获得有关指标的更多详细信息,该怎么办?比如服务器CPU有四个核心,我们要想给它们分别设置指标怎么做?对此,Prometheus有一个标签的概念。标签旨在通过向其添加其他字段来为指标提供更详细信息。你不需要简单地描述CPU速率,你可以指定位于某个IP的核心CPU的CPU速率。也能通过标签过滤指标并准确检索查找的内容。
度量类型
Prometheus的监控指标有四种基本的类型来描述:
计数器Counter
计数器可能是我们可以使用的最简单的度量标准形式。就想它字面意思一样,计数器是随着时间的增长的计算元素。
比如,要计算服务器上的HTTP错误数或网站上的访问次数,这时候就使用计数器。
计数器的值只能增加或重置为0。计数器特别适合计算某个时段上某个事件的发生次数,即指标随时间演变的速率。
Gauges
Gauges用于处理可能随时间减少的值。比如温度本华,内存变化等。Gauge类型的值可以上升和下降,可以是正值或负值。
如果系统每5秒发送一次指标,Prometheus每15秒抓取一次目标,那么这期间可能会丢失一些指标。如果对这些指分析计算,则结果的准确性会越来越低。
而使用计数器,每个值都会被汇总计算。
直方图Histogram
直方图是一种更复杂的度量标准类型。它为我们的指标提供了额外信息,例如观察值的总和及其数量,常用于跟踪事件发生的规模。其值在具有可配置上限的存储对象中聚合。使用直方图可以用来:
计算平均值:因为它们表示值的总和除以记录的值的数量。
计算值的小数测量:这是一个非常强大的工具,可以让我们知道给定的集合中有多少值遵循给定的标准。在用于监控比例或建立质量指标时,这非常有用。
比如,为了监控性能指标,我们希望得到在有20%的服务器请求响应时间超过300毫秒发送警告。对于涉及比例的指标就可以考虑使用直方图。
摘要Summary
摘要是对直方图的扩展。除了提供观察的总和和计数之外,它们还提供滑动窗口上的分位数度量。分位数是将概率密度划分为相等概率范围的方法。
对比直方图:
直方图随时间汇总值,给出总和和计数函数,使得易于查看给定度量的变化趋势。
而摘要则给出了滑动窗口上的分位数(即随时间不断变化)。
这对于获得代表随时间记录的值的95%的值尤其方便。
实例计算
随着分布式架构的不会发展完善和云解决方案的普及,现在的架构不再是孤零零几台配置很高的IBM小机就可以搞定一起的时代了。
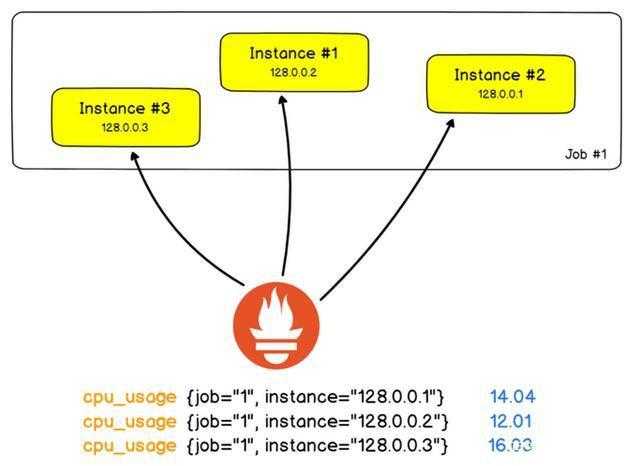
分布式的服务器复制和分发成了日常架构的必备组件。我们举一个经典的Web架构,该架构由2个HAProxy代理服务器,在3个后端Web服务器。在该实例中,我们要监视Web服务器返回的HTTP错误的数量。
使用Prometheus语言,单个Web服务器单元称为实例。该任务是计算所有实例的HTTP错误数量。

PromQL
如果使用过基于InfluxDB的数据库,你可能会熟悉InfluxQL。或者使用TimescaleDB过的SQL语句。Prometheus也内置了自己的SQL查询语言,用于便捷和熟悉的方式从Prometheus查询和检索数据,这个内置的语言就是PromQL。
我们前面说过,Prometheus数据是用键值对表示的。PromQL也用相同的语法查询和返回结果集。
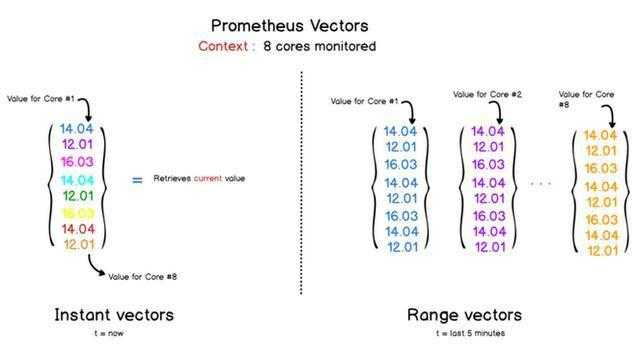
使用Prometheus和PromQL,会处理两种向量:
即时向量:表示在最近时间戳中跟踪的指标。
时间范围向量:用于查看度量随时间的演变,可以使用自定义时间范围查询Prometheus。结果是一个向量聚合所选期间记录的值。

PromQL API公开了一组方便查询数据操作的函数。用它可以实现排序,数学函计算(如导数或指数函数),统计预测计算(如Holt Winters函数)等。
Instrumentation仪表化
仪表化是Prometheus的一个重要组成部分。在从应用程序检索数据之前,必须要仪表化它们。Prometheus术语中的仪表化表示将客户端类库添加到应用程序,以便它们向Prometheus吐出指标。可以对大多数主流的编程语言(比如Python,Java,Ruby,Go甚至Node或C#应用程序)进行仪表化。
在仪表化操作时,需要创建内存对象(如仪表或计数器),可以在运行中增加或减少。然后选择指标公开的位置。Prometheus将从该位置获取并存储到时间序列数据库。

Exporters模版
对于自定义应用程序,仪表化非常方便,它允许自定义公开的指标以及其随时间的变化方式。
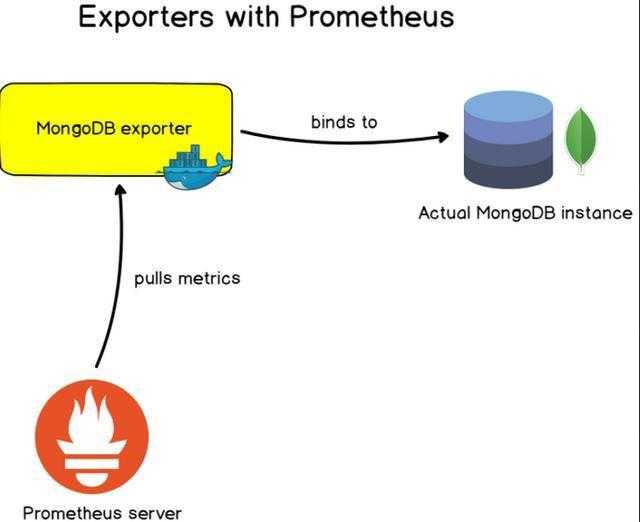
对于一些广泛使用的应用程序,服务器或数据库,Prometheus提供专门的应用模版,可以使用它们来监控目标。
这些模版很多都用Docker镜像,可以轻松配置以监控目标。他们会预设常用的的指标和面板,可以几分钟内就完成监控配置。
常见的Exporters模版有:
数据库模版:用于MongoDB数据库,SQL服务器和MySQL服务器的配置。
HTTP模版:用于HAProxy,Apache或NGINX等web服务器和代理的配置。
Unix模版:用来使用构建的节点导出程序监视系统性能,可以实现完整的系统指标的监控。

告警
在处理时间序列数据库时,我们希望对数据进行处理,并对结果给出反馈,而这部分工作有告警来实现。
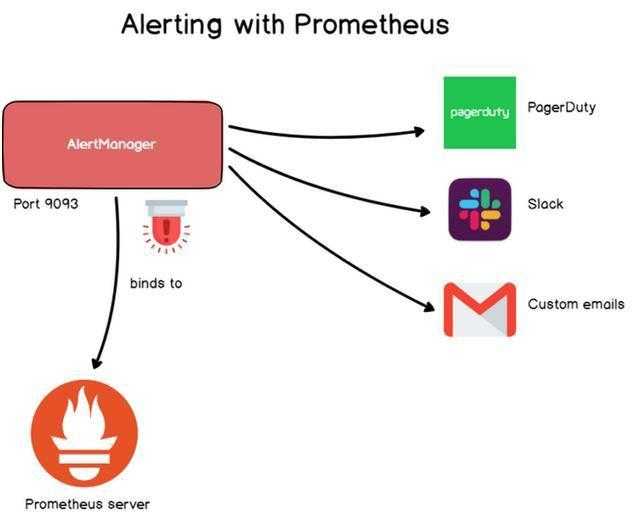
告警在Grafana中非常常见,Prometheus也通过Alertmanager实现完成的告警系统。Alertmanager是一个独立的工具,可以绑定到Prometheus并运行自定义Alertmanager。告警通过配置文件定义,定义有一组指标定义规则组成,如果数据命中这些规则,则会触发告警并将其发送到预定义的目标。与Grafana类似,Prometheus的告警,可以通过email,Slack webhooks,PagerDuty和自定义HTTP目标等。
原文:https://baijiahao.baidu.com/s?id=1634686679128300208&wfr=spider&for=pc&isFailFlag=1

标签:总计 pagerduty 查看 定位 预测 代理服务器 规则组 直接 instr
原文地址:https://www.cnblogs.com/yx88/p/11291681.html