标签:mct 导出 lis 同步 top 过滤器 属性 types 过滤
为什么要使用Elasticsearch?
? 因为在我们中的数据,会随着时间变的非常多,若采用以往的模糊查询,模糊查询前置通配符,如:"%aa%",会放弃索引,导致数据表查询将变成全表扫描,在百万级别的数据库中,效率非常低下,而我们使用ES做一个全文索引,我们就可以将经常查询的数据字段,比如说商品名,描述、价格还有id等,这些字段放入我们索引库里,这样就可以大大提高查询速度。
Elasticsearch
PV: 页面浏览量:一个页面中可能有多个页框,假如:一个页面有100个页框,那么打开一个页面,就会
产生100个请求页面,但统计PV时,这个100个页面就是一个PV.
UV:用户访问量
UV < PV
对于大型Web站点,每秒产生的日志量都是非常惊人的,假如并发1W,每个页面产生100条日志事件,
1秒就是1百万条日志事件.将这些日志写入存储系统,对日志存储系统的压力是非常大的,而且日志存储
下来后还需要能实时对日志做分析的,这就对存储日志的系统有更加高的要求。
搜索引擎:必须包含以下两个组件
索引链:将数据收集,存储,并建立索引的系统,就称为索引链。
搜索组件:即面对用户的数据搜索组件,它是我们开发的程序工具。
搜索引擎的索引称为:倒序索引
所谓倒序,是因为搜索引擎首先对词条,做切词,然后存储在一个表中,这个表只有两列,一列词,一列文档编号,
这样就将词和文档做了关联,在搜索时,搜索引擎会根据词来匹配出符合条件的文档,比如: Linux 培训,那么搜索引擎
会先找Linux,再找培训,最后做并集,同时包含Linux和培训两个关键字的,排列越靠前,这是比较理想的,Google
的搜索引擎算法更加复杂,它可以根据互联网上引用该网页文档,以及网页文档的点击量,等综合来定权重,权重越大的
排列会越靠前。
Lucene和Elasticsearch工作流程图:
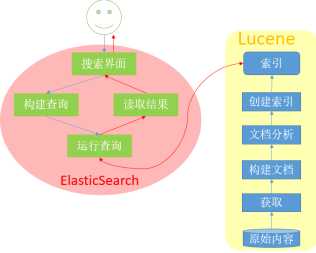
Lucene:
文档:Document
它是包含了一个或多个域的容器,在Lucene将文档中每个词组都称为域
field: value
域:一个域它包含很多选项
索引选项,存储选项,每一项的域向量使用选项。可单个或组合使用。
索引选项:用于通过倒排索引来控制文本是否可被搜索。
Index:ANYLYZED: 分析(切词)并单独作为索引项.
Index:Not_ANYLYZED: 不分析(不切词),把整个内容当一个索引项
Index.ANYLYZED_NORMS: 类似于Index:ANALYZED,但不存储token的Norms(加权基准)信息。
Index.Not_ANYLYZED_NORMS:类似于Index:Not_ANALYZED,但不存储值的Norms(加权基准)信息。
Index.NO: 不对此域的值进行索引:因此不能被搜索。
存储选项:是否需要存储域的真实值
例如: 一个网页的title: This is a Notebook。
对于上面这个句子,在切词后就是 This 和 Notebook.
store.YES: 存储真实值, 此选项则会将This和Notebook统一转换为小写或大写用于索引,
同时还会存储This 和 Notebook这两个原始值。
store.NO:不存储真实值. 而它则是表示不存储This和Notebook的原始值,以便节省空间。
域向量选项用于在搜索期间该文档所有的唯一项都能完全从文档中检索时使用。
文档和域的加权操作:
加权计算标准:
搜索:
查询Lucene索引时,它返回的是一个有序的scoreDOC对象,查询时,Lucene会为每个文档计算
出其score,并根据分值进行排序。
API:
IndexSearcher: 搜索索引入口
Query及其子类:
QueryParser: 查询分析器
TopDocs: 将排名前十的文档保存在其中,它是一个数组。
ScoreDoc:查询的结果文档。
Lucene的多样化查询:
IndexSearcher中的search方法:
TermQuery: 对索引中特定项进行搜索,Term是索引中的最小索引片段,每个Term包含了一个域名和一个文本值。
示例:
文档1:
title: This is a Desk.
owner: Tom Blair.
description: this is a desk, it‘s belong to Tom.
文档2:
title: This is a table.
owner: Clinton
description: this is a desk, it‘s belong to Clinton.
对于以上两个文档,对它们做索引:
现在对这个两个文档做索引如下:
this: 1, 2 #这表示this这个词在,1号和2号文档中都包含.
desk: 1, 2
Tom: 1
Blair: 1
belong: 1, 2
table: 2
Clinton: 2
....
现在TermQuery查询,指定仅查询title域,中包含desk的文档,那么搜索的结果就只有
1号文档。
TermRangeQuery: 在索引中的多个特定项中进行搜索,能搜索指定的多个域。
NumericRangeQuery:做数值范围搜索.
如: 现在有以下文本:
30
34abc
abc093
44a
90
若使用NumericRangeQuery去搜索20-100的值的话,就会搜索出30,90,因为他们是数值.
PrefixQuery: 用于搜索以指定字符串开头的项。这就类似与SQL中"abc%"查询以abc开头的内容.
BooleanQuery:它不是搜索布尔型,而是用于实现组合查询的;组合逻辑有: AND,OR,NOT.
PhraseQuery:它根据搜索关键字在文档中的位置信息来确定那个更加匹配。
如: 我喜欢吃苹果; 平安夜苹果是平安果; 苹果又大又红很好吃。
若使用PhraseQuery搜索苹果,则第三个文档中苹果是在首位的,那它就最匹配,其次
是第二个文档,最后是第一个文档。
WildcardQuery: 进行通配符查询.
FuzzyQuery:模糊查询,根据与关键字的相似度来查询,即相似99%,相似80%,60%...,
越相似就排的越靠前。它是根据Levenshtein算法(距离算法)来做计算的。
Lucene的索引文件,就是它的数据物理文件,在Lucene中称为索引,此索引文件有N多文档组成,每一个文档都称为一行,这些行通常会归类存放,但这并不是必须的,Lucene中文档可以是任意的内容,如一个是关于动物种类的文档,而另一个可能是描述房子建筑的,这些可以为相邻行,但是我们通常不会这么做,通常会归类存储,如:关于动物的文档,关于人类的,关于飞禽类等放一个索引中等。
Elasticsearch:
它借助于Lucene的搜索功能,但它并不仅仅是简单使用,它还在Lucene的基础上,对其功能做了更强大的实现,让Lucene可以支持分布式存储,Elasticsearch通过将Lucene的索引物理文件切分成片,每一个片称为 一个 Sharding ,对每个分片,做所有节点上做冗余备份,并且这些冗余分片,是主从结构的(即:主:能读能写,从:仅读),通过对索引文件分片,可以分担写压力,因为多数情况下,写仅会针对一个分片进行,而读则可能会因为数据量很大,而从每个节点都读。
对于Elasticsearch来说,它可以:
1.能自动对索引物理文件进行分片,并随机分布与Elasticsearch集群中的每台主机上。
2.它可以自动管理每个分片的冗余数量,一旦发现一个分片的冗余数量不足,就会自动为其创建分片,并随机存储在一个节点上.
3.它会自动管理分片的读写,并为用户请求做代理。即:Elasticsearch中每个节点都知道全局的分片存储信息,用户发来一个请求,
如: 一个读请求,它会先看本地是否有要读的这个分片,没有就帮用户将这个读请求转发给有该分片的节点,由该节点负责查询,
该节点查询完成后,会将结果返回给接收用户请求的节点,然后接收用户请求的节点在将结果返回给用户。对于写请求也是一样,
先查本地,若有则看其是主还是从,若没有则转发给有该主分片的节点上,执行写入操作,完成后,再告诉接收用户请求的节点,
写入完成了,接收用户请求的节点在返回用户写入完成。
4.对于Elasticsearch,它首先是一个分布式存储系统,若要对分布式系统进行访问,一则通过其API接口,写程序访问,二则通过其专用客户端接口来访问。
所以宗上所述,Elasticsearch它更像一个分布式的集群实时搜索管理引擎。
Elasticsearch的定义:
ES是一个基于Lucene实现的开源,分布式、基于Restful风格的全文本搜索引擎,此外,它还是一个分布式实时文档存储,其中每个文档的每个field均是被索引的数据,且可被搜索,它也是一个带实时分析功能的分布式搜索引擎,能够扩展至数以百计的节点,实时处理PB级数据的搜索引擎。
基本组件:
索引(index): 它其实就是一个文档容器,或者说是类似属性的文档的集合,它类似于表.
注: 索引名必须使用全小写字母,而且ES中可以创建N多个索引,根据需要创建.
类型(type):类型是索引内部的逻辑分区,其意义完全取决于用户需求,一个索引内部可定义一个或多个类型.一般来说,
类型就是拥有相同的域的文档的预定义,不过每种类型之间无任何约束,如:一个索引中可以有日志类型,
评论类型,文章类型等,不过建议一个索引中尽量只有一个类型。
文档(document):文档是Lucene索引和搜索的原子单位,它包含了一个或多个域(即:字段),它是域的容器。但文档要基于
JSON格式进行表示。每个域的组成部分,一是名字,二是值,值可以是一个或多个.甚至是一个文档。
通常将拥有多个值的域,称为多值域。
映射(mapping):原始内容存储为文档之前需要事先进行分析,如:切词、过滤掉某词等,而映射就是用于定义这种分析机制
该如何实现的,除此之外,ES还为映射提供了诸如将域中的内容排序等功能。可以这样理解: 在ES中,映射实际
是索引外部的一个文件,它定义了一个文档要怎么分析,比如:
This is a disk.
对于这个文档,映射中规定,This,is,a,这些都是助词,可以忽略,只有disk是关键词,需要将其切出来,这就是映射的作用。
Elasticsearch的集群组件:
Cluster:ES的集群是根据集群标识来组建的,默认标识为‘elasticsearch‘,若需要定义多个集群,就必须手动修改集群标识了,
注: 节点是根据集群标识来决定加入到那个集群,而且一个节点只能属于一个集群。
Node:即运行ES实例的主机,它用于存储索引分片数据,参与集群索引及搜索操作。节点的标识靠节点名,此节点名非主机名,
它仅是此节点在集群中的标识,默认会生成随机字符串做为其名字,建议手动定义可容易识别的节点名称。
Shard: 即分片,它就是将索引切割成物理存储组件,但每一个shard都是一个独立且完整的索引,但在ES层面来看,它们是一个
大索引的分片。创建索引时,ES默认会将其分割为5个shard,但可根据集群数量自定义分片个数。
shard有两种类型:
Primary shard: 即主分片,一个大索引物理文件,默认ES将其分成5个主shard.需要注意,大索引被分成几个主shard只能在分割前设定,
分割后,就不能修改了,若你想将其分成6个,那就只能将5个分片组合成一个大索引后,在重新分成6个主shard.
replica shared: 即副本分片,它主要用于数据冗余及查询时的负载均衡,它是主分片的副本,它可以随时动态调整数量。
ES Cluster的工作过程:
启动时,ES集群通过多播(默认) 或 单播方式在TCP的9300端口上,查找同一集群中的其它节点,并与之建立通信。集群中的所有节点会选举出一个主节点负责管理整个集群状态,以及在集群范围内决定各shards的分布方式,所以站在用户角度看,ES集群中的每个节点均可接收并响应用户的各类请求。当一个节点宕机了,主节点会协调各节点进入维护模式,此时主节点会先查询所有现存节点上,主分片是否缺失,副本分片是否够数,来报告集群目前的状态,ES集群有三种状态:
green: 正常状态.
red: 不可用状态.
yellow:修复状态.此状态下,所有副本shard都将进入维护模式,并都将不可用,仅主shard可用,因此此时读将无法负载均衡,
吞吐能力将下降。ES在这种状态下,主节点会检查所有主分片是否都在,若有一个丢失,则从现存的副本shard中找一个,
并将其提升为主shard,接着在检查副本shard是否均达到配额,若有副本数量缺少的,则ES重新复制一个副本shard到
一个节点上,并让所有副本shard都达到配额副本shard后,再将集群从yellow状态转为green状态。
ES集群在运行过程中,主节点会周期性检查集群中各节点是否宕机,是否可提供服务等,一旦发现有节点不可用,就会将集群转为yellow状态,并重新进入集群的重新均衡。
Elasticsearch是如何实现Master选举的?
Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;对所有可以成为master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
补充:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能。
安装ES2.0.0: 任何集群在配置前,一定要确定时间同步。 node1: 1.准备Java环境 查看当前系统是否安装了 JDK1.7以上版本,以及其JDK1.7的 devel包。 接着导出JAVA_HOME环境变量。 vim /etc/profile.d/java.sh export JAVA_HOME=/usr #默认rpm包安装会在/usr/bin/下创建一个java软连接. 此java软连接时连接到/etc/下面的,而etc下面还是一个软连接. 它是连接到正在的java,这样做是为了方便升级。 2.安装ES yum install elasticsearch 编辑配置文件: vim /etc/elasticsearch/elasticsearch.yml cluster.name: myes node.name: "node1" node.master: true #true:表示此节点参与主节点选举. node.data: true #true:表示此节点可用于存储数据. index.number_of_shards:5 #每个索引默认切成5个shard. index.number_of_replicas:1 #每个shard默认保存1个副本。 transport.tcp.port: 9300 #默认其集群选举的端口为9300 http.port: 9200 #默认接收并响应用户请求的端口为9200 discovery.zen.minimum_master_nodes: 1 #最少主节点的数量,1个. 注: 发现协议使用的是 ES的zen协议. discovery.zen.ping.timeout: 3s #心跳检查超时时间. discovery.zen.ping.multicast.enabled: false #false:表示使用单播做心跳检查. 启动ES: systemctl daemon-reload systemctl start elasticsearch.service systemctl status elasticsearch.service -Xms256m: 表示堆内存最小256M -Xmx1g: 表示最大堆内存1G node2: 1. 安装JDK1.7 和 JDK1.7 devel 2. 创建JAVA_HOME echo ‘export JAVA_HOME=/usr‘ > /etc/profile.d/java.sh 3. 安装Elasticsearch yum install elasticsearch 4. 编辑配置文件: vim /etc/elasticsearch/elasticsearch.yml cluster.name: myes node.name: "node2" 5. 启动ES: systemctl daemon-reload systemctl start elasticsearch.service 6. 此时就可以抓包查看ES集群传递的信息。 node3: 1. 安装JDK1.7 和 JDK1.7 devel 2. 创建JAVA_HOME echo ‘export JAVA_HOME=/usr‘ > /etc/profile.d/java.sh 3. 安装Elasticsearch yum install elasticsearch 4. 编辑配置文件: vim /etc/elasticsearch/elasticsearch.yml cluster.name: myes node.name: "node3" 5. 启动ES: systemctl daemon-reload systemctl start elasticsearch.service ES的Restful API,共四类API: 1. 检查集群、节点、索引等健康与否,以及获取其相应状态。 2. 管理集群、节点、索引及元数据 3. 执行CRUB操作(即:增删查改) 4. 执行高级操作,如:paging,filtering等。 ES API的访问接口: TCP:9200,并且ES是基于HTTP协议工作的. curl -X <Verb> ‘<Protocol>://Host:Port/<Path>?<Query_String>‘ -d ‘<Body>‘ 注: Verb: 即HTTP的操作,GET, PUT, DELETE等. Protocol: http,https Path: 访问路径. Query_String:查询参数,如: ‘?pretty‘:表示使用容易读的JSON格式显示输出. Body:请求的主体。 如查看node1的状态: curl -X GET ‘http://1.1.1.1:9200/?pretty‘ ES的API接口: _cat API: 查看ES集群的状态: curl -X GET ‘http://1.1.1.1:9200/_cat/nodes?v‘ 注: _cat: 这是ES的API接口名,一般ES的API接口名使用下划线开头. 此接口的功能是输出显示的。 ?v: 问号v,是修饰符,v:是verbose,显示详情。 ?help: 可显示帮助信息。 ?h=name,ip,port,uptime,heap.current :可定义显示那些列. _cluster APIs: 查看ES集群健康状态详情: curl -X GET ‘http://1.1.1.1:9200/_cluster/health?pretty‘ 查看索引的健康状态: health curl -X GET ‘http://1.1.1.1:9200/_cluster/health/索引名1,索引名2,...‘ curl -X GET ‘http://1.1.1.1:9200/_cluster/health/索引名1?level=Level‘ 注: cluster:显示到集群级别 indices:显示到索引级别 shards:分片级别 查看集群的状态信息: state: curl -X GET ‘http://1.1.1.1:9200/_cluster/state/version‘ curl -X GET ‘http://1.1.1.1:9200/_cluster/state/master_node?pretty‘ curl -X GET ‘http://1.1.1.1:9200/_cluster/state/nodes?pretty‘ 查看集群的统计数据: stats: curl -X GET ‘http://1.1.1.1:9200/_cluster/stats?pretty‘ ES Plugins: 插件可扩展ES的功能: 可添加自定义的映射类型、自定义的词干分析器、本地脚本、自定义发现方式 安装插件: 1. 直接将插件放到插件目录中。 2. 使用/usr/share/elasticsearch/bin/plugin命令来安装插件。 此命令的参数说明: -u 插件URL #若能联网,可直接提供互联网插件URL即可安装. 若是下载到本地,则可: file:///path/插件.zip -i 插件名 #安装插件。 插件安装完,访问方式: http://1.1.1.1:9200/_plugin/插件名/ 常用监控和管理插件: bigdesk marvel kopf head #在ES6.x以上很多插件已经不在更新了,head插件在ES6.8.1中测试工作正常. 索引管理: 创建索引:[ES自动创建] 注: 若引用的索引不存在,则会自动创建。 若引用的类型(type)不存在时,也是自动创建。 id 是自定义的文档标识,可使用全局ID生成器来生成.若id冲突,则PUT时,默认是覆盖。 curl -X PUT ‘http://1.1.1.1:9200/students/class1/1‘ -H "content-type: application/json" -d ‘ { "first_name":"Guo", ‘last_name‘:‘Yang‘, ‘gender‘:"Male", ‘age‘:‘26‘, ‘courses‘:‘GuMu ShenGong‘ }‘ curl -XPUT ‘http://1.1.1.1:9200/students/class1/2‘ -H "content-type: application/json" -d ‘ { "first_name":"LongNv", "last_name":‘Xiao‘, ‘gender‘:"Female", ‘age‘:‘25‘, ‘courses‘:‘GuMu LiYing‘ }‘ 查看创建的索引: curl -XGET ‘http://1.1.1.1:9200/students/class1/1?pretty‘ 更新创建的文档: curl -XPOST ‘http://1.1.1.1:9200/students/class1/2/_update?pretty‘ -d ‘ { "doc":{ "age": 23 } }‘ 删除文档: curl -XDELETE ‘http://1.1.1.1:9200/students/class1/2‘ 删除索引: curl -XDELETE ‘http://1.1.1.1:9200/students‘ curl -XGET ‘http://1.1.1.1:9200/_cat/indices?v‘ 查询数据; Query API: 查询使用的DSL(Domain Search Language):基于JSON的语言去构建复杂查询。 它用于实现诸多类型的查询操作,如:简单查询,phrase,range,boolean, fuzzy(模糊查询)等查询。 ES的查询操作执行分为两个阶段: 1.分散阶段:将用户请求转发到拥有该shared的节点上,执行操作。 2.合并阶段:执行操作的节点返回执行结果给,接收用户请求的节点,由该节点合并结果返回用户。 查询方式: 向ES发起查询请求的方式有两种: 1.通过Restful request API查询,也称为query string. 2.通过发送REST request body进行. 查询一个索引下的所有文档: 1.简单的查询字符串(Query String): curl -XGET ‘localhost:9200/students/_search?pretty‘ 注: took: 表示请求响应时间. hits:使用了一个数组来记录搜索到的文档. hits下面的_id: 文档ID. _score: 这是文档成绩,若有加权,就由它记录。 2.REST Request Body curl -XGET ‘localhost:9200/students/_search?pretty‘ -d ‘ { "query": { "match_all":{} }}‘ 多索引,多类型查询: curl -XGET ‘http://1ocalhost:9200/_search/‘ #所有索引 curl -XGET ‘http:/.../IndexName/_search/‘ #单索引 curl -XGET ‘http://../Index1,Index2,../_search‘ #多索引 curl -XGET ‘http://../t*,sh*/_search‘ #通配符索引. curl -XGET ‘http://.../tests/class1/_search‘ #单类型搜索 curl -XGET ‘http://.../tests/class1,class2/_search‘ #多类型搜索。 Mapping和Analysis: ES对每一个文档,取得其所有域的所有值,并生成一个名为"_all"的域,执行查询时,若在Query_String时,未指定查询的域,则在_all域上执行查询操作: #指定了查询域,则表示在courses域中做精确查询: #模糊: curl -XGET ‘URL/_search?q=courses:"GuMu"‘ #精确: curl -XGET ‘URL/_search?q=courses:"GuMu%20ShenGong"‘ #%20是空格的转义 #下面是没有指定查询域,则在_all域上执行查询: curl -XGET ‘http://localhost:9200/students/_search?q="Yang"&pretty‘ curl -XGET ‘http://localhost:9200/students/_search?q="Yang%20Guo"&pretty‘ #创建age:25 和 desc:"total 25"两个文档,当不指定域,在_all域中搜索时,做以下测试: curl -XGET ‘http://localhost:9200/students/_search?q=25‘ ES中的数据类型: string, numbers, boolean, dates 查看指定类型(type)的mapping: curl ‘URL/students/_mapping/class1?pretty‘ #查看class1这个type的mapping. ES中搜索的数据广义可被理解为两类: types: exact #精确搜索 full-text #全文搜索 精确值:指未经加工的原始值,在搜索时进行精确匹配. 如:Apple, 则Apple不能被转换为apple再去查询,必须是查询Apple full-text:用于引用文本中数据,判断文档在多大程度上匹配查询请求,即评估文档与用户 请求查询的相关度. 为了完成full-text搜索,ES必须首先分析文本,并创建出 倒排索引,在倒排索引中的数据还需要进行“正规化”为标准格式: 即:先分词,后正规化,这个过程叫“分析”,由analyzer完成。 分析需要由分析器进行: analyzer 一个分析器由三个部分组成: 字符过滤器,分词器,分词过滤器 ES内置的分析器: Standard Analyzer: 它比较通用,ES默认使用它做分析,它使用Unicode标准做分词. Simple analyzer:它是根据非字母字符做单词边界,来分词分析。 Whitespace analyzer:它是根据空白字符作为单词边界,来分词分析。 Language analyzer:使用于不同语言的专用语言单词分析器 分析器不仅在创建索引时用,在构建查询时也需要用到. 简单理解: 构建索引时使用了Standard analyzer,但在构建查询时使用了 simple analyzer,则二者的构建的结构可能存在差异,因而查询结果 也会带来很大影响。所以不建议这样使用。 Query DSL: 请求主体部分分成两类查询: Query DSL: 执行full-text查询时,基于相关度来评判其匹配结果: 因此其查询执行过程复杂,且不会被缓存。但使用基于倒排索引的机制,也可以实现 接近于实时的查询。 Filter DSL:执行exact(精确)查询时,基于其结果为“yes"或“no”进行评判: 因此其查询执行简单,速度快,且结果容易被缓存。 查询语句的结构: { QUERY_NAME:{ ARGUMENT:VALUE, ARGUMENT:VALUE,... } } { QUERY_NAME:{ FIELD_NAME:{ ARGUMENT:VALUE,.. } } } filter DSL: term filter:精确匹配指定项(term)的文档。 如: "Guo", "Jing" , "Guo%20Jing" 这三个都是一个term. 示例: { "term": {"name":"Guo"}} #判断name中是否包含Guo这个字符串的term filter。 查询格式: curl -XGET ‘URL/students/_search?pretty‘ -d ‘{ "query": { "term": { #单值匹配 "name":"Guo" } } }‘ terms filter: 用于多值精确匹配: 查询格式: curl -XGET ‘URL/students/_search?pretty‘ -d ‘{ "query": { "terms": { #多值匹配 "age":[20,22,18,30,27] } } }‘ range filters: 用于在指定的范围内查找数值或时间.【仅能查询数值和时间】 查询格式: curl -XGET ‘URL/students/_search?pretty‘ -H "content-type: application/json" -d ‘{ "range": { "age": { #测试失败,"Unknown key for a START_OBJECT in [range]." 没有找到原因 "gte":15, "lte":25 } } }‘ 注: gt:大于,lt:小于, gte:大于等于,lte:小于等于 exists 和 missing filters: 用于判断指定查询内容是存在 或 不存在. 查询格式: curl -XGET ‘URL/students/_search?pretty‘ -d ‘{ "exists": { "age": 28 } }‘ boolean filter:基于boolean的逻辑来合并多个filter子句: must: 其内部所有的子句条件必须同时匹配,即and: 格式: must: { "term":{ "age": 25 } "term":{ "gender": "Female"} } #查询年龄在25岁的女人 must_not: 其所有子句必须不匹配,即not 格式: must_not: { "term":{ "age": 25 } } should: 至少有一个子句匹配,即:or 格式: should: { "term":{ "age": 25 } "term":{ "gender": "Female"} } #查询年龄是25岁的 或 是女人的 Query DSL: match_all Query: 用于匹配所有文档,若没有指定任何query,默认即为 match_all查询. 如: { "match_all": {} } match Query: 在几乎所有域上执行full-text 或 exact-value查询: full-text:会先做语句分析再查询。 如: { "match": {"students":"Guo"}} #这是在students索引中查询所有包含"Guo"的内容 exact-value:精确值匹配时,不需要分析.但它不会缓存,所以此时建议使用过滤,而非查询. 如: { "match":{"name":"Guo"}} multi_match Query: 用于在多个域上执行相同查询: 格式: { "multi_match": "query":{ ‘索引 | 类型 ‘: "QueryString"} "field":{ ‘field1‘, ‘field2‘} } 如: { "multi_match": "query":{ "students":"Yang" } "field":{ "name", "description" } } #这就是在students索引内部的name和description域上查询包含"Yang"的内容 bool query: 基于boolean逻辑合并多个查询语句,与bool filter不同的是,查询子句不返回 yes/no, 而是计算出匹配度分值,因此,boolean Query会为各子句合并其score值: 使用格式: must: must_not: should: 合并filter和Query: 通常会将filter嵌套在query中组合使用,但很少将query嵌套在filter中过滤。 { "filterd":{ query:{ "match":{"gender":"Female"} } filter:{ "term":{"age":25} } } } 查询语句的语法检查: curl -XGET ‘URL/INDEX_NAME/_validate/query?pretty‘ -H "content-type: application/json" -d ‘{ ... }‘ 示例: curl -XGET ‘localhost:9200/students/_validate/query?pretty‘ -H "content-type: application/json" -d ‘{ "query":{"term":{ "name": "Guo" }} }‘ #注:前面提到索引构建的分析器有,存储原值和不存原值的选项,若创建索引时, 分析器使用的是不存储原值,则分析器会自动会将所有数据都转换为小写索引 并存储,所以这里做精确值匹配时,是没有‘Guo‘这样的字符串的。也就是说 索引存储的分析器和查询分析器不一样导致的问题。 分析语法时显示错误信息: curl -XGET ‘URL/INDEX_NAME/_validate/query?explain&pretty‘ -d ‘{ ... }‘
ELK Stack的两个组件:
L: Logstash
K: Kibian
Logstash:
支持多种数据获取机制,通过TCP/UDP协议、文件、syslog、Windows EventLogs及STDIN等,获取到数据后,它支持对数据执行过滤、修改等操作。另外Logstash它本身不仅有日志收集功能,它还支持索引构建,不过它的索引和ES的索引构建不是一个量级的。
它使用JRuby语言研发,需要运行在JVM上,并且为Agent/Server模型。
工作原理:
WebNode1【L_Agent】--->【Broker:掮客(如:Redis)】<--->【L_Server】--->【ES集群】
Logstash如上图所示,它需要在每个日志收集端安装Agent,由Agent来收集目标节点上指定的日志信息,并将这些日志信息先发送给Broker(消息队列),接着Logstash再从
Broker中取出数据,在本地执行分析,再过滤,最后输出给ES集群。
Logstash Server:
它是一个严重插件式服务器,它除了核心功能外,主要部件都使用插件来完成工作,首先是INPUT Plugin,若有消息队列,则根据消息队列可选择对应的INPUT Plugin,若
直接从Agent接收数据,由Agent相关的插件; 接着是Codec Plugin,这是logstash的分析插件,可以根据数据来定义如何分析,此类插件也有十多种;再接着是filter plugin
这是它的过滤插件,主要完成数据过滤,仅将需要的数据过滤出来,并最终发给OUTPUT plugin,由它将最终数据发送给ES集群。
安装logstash
1.先准备JAVA运行环境,导出JAVA_HOME
2.安装logstash
logstash可以在ELK的官网直接下载。
3.安装好logstash后,默认RPM是安装在/opt/logstash/bin下面的。
vim /etc/profile.d/logstash.sh
export PATH=/opt/logstash/bin:$PATH
4.创建一个简单的从标准输入接收数据,从标准输出来输出数据的配置文件:
vim /etc/logstash/conf.d/smiple.conf
input {
stdin {}
}
output {
stdout {
codec => rubydebug
}
}
检测配置文件语法:
logstash -f /etc/logstash/conf.d/smiple.conf --configtest
直接运行:
logstash -f /etc/logstash/conf.d/smiple.conf
#当出现Logstash startup,则启动成功。
#这时就可以输入日志,做测试:
Hello Logstash
Logstash的配置文件框架格式:
input { .... }
filter { .... }
codec { .... }
output { .... }
它支持以下数据类型:
Array: [item1, item2,...]
Boolean: true, false
Bytes: 字节值
Codec: 编码器类型
Hash:key => value, key => value, ...
Number: 数值型,浮点型
Password:不记录或记录为星号的密码串
Path:文件系统路径
String:字符串
字段引用: []
条件判断:
==, !=, <, <=, >, >=
=~, !~ : 匹配和不匹配
in, not in: 包含 或 不包含
and, or
()
Logstash的工作流程: input | filter | output #可以将Logstash看成一个管道,filter是可选的。 Logstash的插件: input插件: File: 从指定的文件中读取事件流,它从文件中获取日志最新变化的方式类似于tail -f, 叫做FileWatch,虽然FileWatch是文件系统的一个功能,但此插件是使用Ruby Gem 库实现了此功能,File插件每次读取完最新日志后,会记录读取信息,如读到哪一行:pos, 该日志文件的inode,以及该日志文件所在磁盘设备的major number,minor number等信息。 当然这些信息是存储在一个叫“.sincedb”中的,默认在运行logstash Agent的用户家目录中, 另外,File插件可自动识别日志滚动后的文件。 示例: vim /etc/logstash/conf.d/fromfile.conf input { file { path => ["/var/log/messages"] #定义为数组类型. type => "system" #类型是用来定义,在其它地方引用时的 的字符串标识,可为任意字符.例如: 可在过滤时,指定对哪些类型的信息做过滤. start_position => "beginning" #定义从哪里开始读取日志文件 } } output { stdout { codec => rubydebug } } udp插件:在logstash server端启动一个进程监听在指定端口上,接收远端主机发来的日志信息。 它主要需要定义:port 和 host,监听端口和地址。 示例: collectd: 这是一个用C语言开发的,服务性能监控程序,它可以将收集到的 服务器上的性能数据收集起来,通过不同的插件存储到不同的位置,它 有一个network插件,此次udp示例,就需要使用它的network插件, 来将收集到的服务器性能数据发送给logstash。 在collectd服务器端配置: 1. 安装collectd ,在epel源中有 2. 修改collectd的配置文件: vim /etc/collectd.conf Hostname ‘node1.a.com‘ Loadplugin network #启用监控主机的哪些数据,如:CPU,内存,磁盘,接口等.但,在这里要找到network插件,并启用它。 <Plugin network> #这是对network插件的功能定义.不同插件有不同的 #功能定义,也有的插件没有。 <Server "1.1.1.1" "25826"> #定义接收数据的服务器是谁,及其端口. ..若需要认证,可定义认证选项.. ResolveInterval 2000 #设置收集数据的时间间隔,此设置为每隔2秒发送一次 </Server> </Plugin> systemctl start collectd.service 在Logstash服务器端配置: 配置logstash来接收collectd发来的服务器性能数据 input { udp { port => 25826 codec => collectd {} #这是logstash专门对collectd提供的解析器 type => "collectd" } } output { stdout { codec => rubydebug } } redis插件: 从redis读取数据,支持redis channel 和 list的两种方式。 filter插件: 用于将收到的event通过output发出之前对其实现某些处理功能的. grok: 它是在处理Web服务日志时,必须使用的插件; grok是用于分析并结构化 文本数据,它是目前,logstash中将非结构化日志数据转化为结构化的可查询 数据的不二之选。 它的模式定义位置: rpm -ql logstash |grep ‘patterns‘ 其中有一个叫 ‘grok-patterns‘的文件,它就是模式匹配文件. #在ubuntu上位置: /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-patterns-core-4.1.2/patterns/ #说明: 在这个目录下有很多模式匹配文件,其中的关键字都可以直接使用. grok模式定义的语法格式: %{SYNTAX:SEMANTIC} SYNTAX:预定义模式名称,它可自定义,若没有相关预定义的配置,其语法就是: SYNTAX_NAME 正则表达式 SEMANTIC:匹配到的文本的自定义标识符 如: 1.1.1.1 GET /index.html 30 0.23 匹配此段日志信息的模式为: %{IP:clientip} \ #IP: 是grok.patterns文件中定义的SYNTAX, clientip:是IP这个预定义模式匹配到的值,存放的变量名。 %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration} 使用示例: vim /etc/logstash/conf.d/grok.conf input { stdin {} } filter { grok { match => { "message" => "%{IP:clientip} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" } } } output { stdout { codec => rubydebug } } 启动测试: 1. 检查配置文件语法 logstansh -f /etc/logstash/conf.d/grok.conf --configtest 2. 启动logstash logstansh -f /etc/logstash/conf.d/grok.conf 3. 测试输入: 1.1.1.1 GET /index.html 30 0.23 示例2: 测试读取httpd的access_log文件 vim /etc/logstash/conf.d/apachelog_grok.conf input { file { path => ["/var/log/httpd/access_log"] type => "ApacheLog" start_position => ‘beginning‘ } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } } output { stdout { codec => rubydebug } } 1. 检查配置文件语法 logstansh -f /etc/logstash/conf.d/apachelog_grok.conf --configtest 2. 启动logstash logstansh -f /etc/logstash/conf.d/apachelog_grok.conf 3. 启动apached 并 尝试访问一次默认首页。 output插件: redis插件的使用示例: 1. 在epel源中安装redis 2. 配置redis vim /etc/redis.conf port 6396 host 0.0.0.0 3.启动redis systemctl start redis 4.编写配置文件 vim /etc/logstash/conf.d/redis_form_nginxlog.conf input { file { path => ["/var/log/nginx/access.log"] type => "NginxLog" start_position => "beginning" } } filter { grok { match => { "message" => "%{NGINXACCESS}"} } } output { redis { batch => false #若为true:则表示若有多个数据要发布时,redis可一次 性打包发布,使用RPUSH方式。 port => "6379" host => ["127.0.0.1"] #redis若安装在本机,可默认不写 data_type => "list" key => "logstash-%{type}" #type:是引用input中的type值。 } } 检测logstash的配置文件 启动logstash 尝试访问nginx页面 登录redis查看 redis-cli 127.0.0.1:6379> LLEN logstash-nginxlog #logstash-nginxlog:是output中定义key的值 127.0.0.1:6379>LINDEX logstash-nginxlog 0 #查看key中索引号为0的值 配置从redis中读数据,并存储到后端的ES集群中: node3: 作为Logstash Agent节点配置: 1. 在epel源中安装redis 配置redis vim /etc/redis.conf port 6396 host 0.0.0.0 启动redis systemctl start redis 2. 安装nginx,使用默认配置,直接启动nginx 3. 尝试访问nginx页面 4.安装java-openjdk-8.0以上,并配置JAVA_HOME 5.安装logstash 6.配置logstash vim /etc/logstash/conf.d/redis_form_nginxlog.conf input { file { path => ["/var/log/nginx/access.log"] type => "NginxLog" start_position => "beginning" } } filter { grok { match => { "message" => "%{NGINXACCESS}"} } } output { redis { port => "6379" host => ["127.0.0.1"] #redis若安装在本机,可默认不写 data_type => "list" key => "logstash-%{type}" #type:是引用input中的type值。 } } 7. 启动logstash logstash -f /etc/logstash/conf.d/redis_from_nginxlog.conf 8. 登录redis查看 redis-cli 127.0.0.1:6379> LLEN logstash-nginxlog #logstash-nginxlog:是output中定义key的值 127.0.0.1:6379>LINDEX logstash-nginxlog 0 #查看key中索引号为0的值 node2: 作为Logstash server节点配置: 1.安装java-openjdk-8.0以上,并配置JAVA_HOME 2.安装logstash 3.配置logstash vim /etc/logstash/conf.d/server.conf input { redis { #这里需要注意: logstash从Redis中读取logstash写进去的日志后,它会将其自动删除,此可通过Windows版的RedisClient工具查看最为清晰。 port => "6379" host => "1.1.1.3" data_type => "list" key => "logstash-nginxlog" } } output { elasticsearch { #cluster => "loges" hosts => ["http://1.1.1.1:9200"] index => "logstash-%{+YYYY.MM.dd}" #这里要注意:写到Elasticsearch中的index键必须是小写!!否则再向ES中写时会报错 } } 4.检查配置文件语法 5.启动logstash node1: 配置为ES集群的节点,此次测试做单节点 1. 安装openjdk1.7以上的, 完成后配置JAVA_HOME 2. 安装ES yum install elasticsearch 3. 编辑ES的配置文件 vim /etc/elasticsearch/elasticsearch.conf cluster.name loges node.name: "node1.a.com" 4.启动ES systemctl daemon-reload systemctl start elasticsearch.service 5.安装ES的插件 /usr/share/elasticsearch/bin/plugin -i bigdesk -u file:///path/bigdesk.zip 6.安装kibana 从ES官网下载kibana后 tar xf kibana.tar.gz -C /usr/local/ cd /usr/local/kibana/config/ vim kibana.yml 修改ES的访问URL为ES集群中的任意一个节点IP即可。 启动kibana /usr/local/kibana/bin/kibana & 访问kibana http://kibana_IP:5601/ 7. 先访问node3上的nginx,让其产生新日志信息 8. 尝试在ES集群上使用查询看看能否收到这些新日志信息 curl -XGET ‘http://1.1.1.1:9200/_cat/indices‘ #查看ES集群中所有的索引信息 curl -XGET ‘http://1.1.1.1:9200/logstash-2018xxx/_search?pretty‘
标签:mct 导出 lis 同步 top 过滤器 属性 types 过滤
原文地址:https://www.cnblogs.com/wn1m/p/11291430.html