标签:html https app 世界 文件存储 之一 停止 文件的 成功
声明:本文档所有内容均在本人的学习和理解上整理,仅供参考,欢迎讨论。不具有权威性,甚至不具有精确性,也会在以后的学习中对不合理之处进行修改。
在上一篇“浅谈Hadoop inFusionInsight—华为大数据解决方案的理解”中,我重点提到了大数据的两个相较于传统数据所不同的特点——数量大和种类多。在Hadoop的底层有个非常重要的部分,我们一般称之为“核心”——分布式文件存储系统,即HDFS。我之前说过,单个服务器的内存和磁盘空间是有上限的,不可能无限支持线性增加。面对海量的大数据,单个服务器是存不下的,这辈子都不可能存的下的。面对传统存储的技术瓶颈,“分布式”的概念就很好的解决了问题。
一、什么是HDFS
HDFS的中文名叫“分布式文件系统”,是山寨来源于Google的文件系统GFS。2003年Google发表了几篇撼动世界级别的论文,GFS就是其中之一。最早作为Google的文件存储系统,它可以稳定的运行在几千台甚至上万台设备上,足以证明其优越之处。GFS的设计理念有两个很重要的假设:只存储大文件、不能修改(update)只能追加(append)。在这两个假设的基础上,又提出了一个划时代的理念:将大文件分成若干个小文件。后来有一天资聪颖的哥们看了古哥的这篇论文,一拍脑门(也可能是一跺脚):“艾玛有搞头!”于是就山寨抄袭借鉴copy开发出了HDFS。HDFS主要解决了Hadoop的大数据存储问题,所以我们一般都称之为“分布式文件存储系统”。作为大数据的存储系统,他有几个显著的特性:
①高容错性
②高吞吐量
③支持大文件(TB、PB)的存储
二、HDFS的重要角色和概念
1、NameNode(NN节点)
HDFS的管理者。负责监控DataNode,记录文件的存储信息,协调客户端的读写请求,等。相当于目录。
2、DataNode(DN节点)
HDFS的执行者。负责文件的存储,以块为存储单位,数据分散在不同DN节点,支持一次写入多次读取,等。相当于正文。
3、SecondaryNameNode
NameNode的冷备份,同步NameNode的日志(EditLog)和镜像文件(FsImage),并将日志和镜像合并成新的镜像文件回传给NameNode
4、Editlog
日志文件,记录每次元数据的变化
5、FsImage
镜像文件,内存中元数据在本地磁盘的映射
PS:NameNode的内存中是FsImage+EditLog
6、热备份
NameNode停止工作后,热备份NameNode马上接替NameNode的工作
7、冷备份
同SecondaryNmaeNode
三、HDFS的读写流程
这个我们可以类比图书馆,写就是新书入馆,读就是客户借书。大家应该听过一个问题:把大象装进冰箱分几步?我们就以3大步来看这个问题。
先看看写流程。有一批新书要入馆,我们要走哪些流程?
1、员工先找到馆长,告诉他你要的货……你要的书我带来了:打开了冰箱门。
2、馆长看到书来了先是喜上眉梢,紧接着眉头一皱,发现事情并不简单:大象怎么塞进冰箱?
3、馆长终于想起来“目录”这么个玩意,费了老半天劲指挥员工把书存好,然后把目录放好:关上冰箱门。
根据图书馆的例子,运用到HDFS上:
Round1 写流程
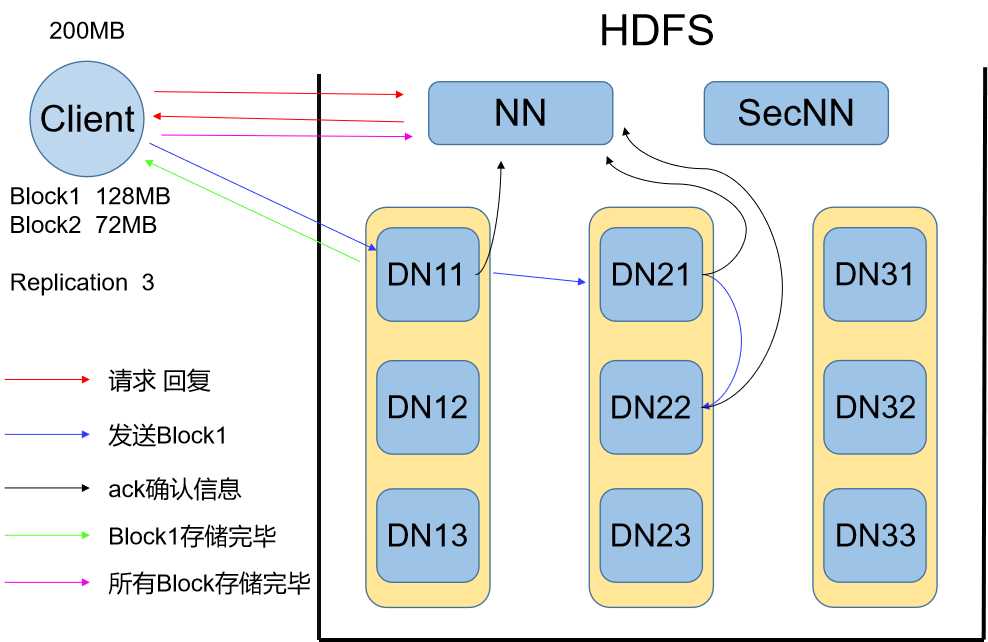
A:打开冰箱门
1、用户在客户端(Client)发起写命令,存入一个文件
①用户需先将文件分块,一般块大小为128MB
②还需要制定文件的副本参数,一般为3
2、客户端向NN节点发起写请求
①请求信息中包含但不限于文件大小(块)、副本参数
3、NN节点收到请求,给Client发送一个回复信息
①NN从自己管理的(DN)节点信息中找出适合的3个(与副本参数一致)DN节点
②将选中的DN节点地址和路径参数的等信息发送给Client
B:把大象塞进去
1、Client收到回复信息,开始发送第一个数据块(Block)
①Client通过NN的回复信息找到第一个DN节点,开始发送数据块,以及备份副本DN地址列表
②第一个DN开始按数据包分批接受Block存盘,每存盘一个数据包同时将相同的数据包再转发给的二个DN节点,以此类推直到最后一个DN节点存盘后不在转发
③所有DN都接受到了完整的Block后,向NN节点发送确认信息,第一个DN节点还要向Client发送确认信息
2、Client收到第一个Block存盘完毕的信息后开始执行第二个Block的操作,重新向NN节点发送请求
C:关闭冰箱门
1、Client收到DN节点最后一个Block存盘成功的确认信息后,向NN节点发送结束信息
2、NN节点收到Client发来的结束信息,关闭目录文件,此时存储文件的元数据信息已经记录在了目录文件中
小结:在写流程中,Client负责发起命令,将文件分块和设置副本参数;NN节点负责协调Client和DN节点的交互,包括为每个文件的多个数据块分配存储地址及记录元数据;DN负责干活,存储从Client发来的数据,同时多副本机制保障了数据的高可靠性。
Round2 读流程
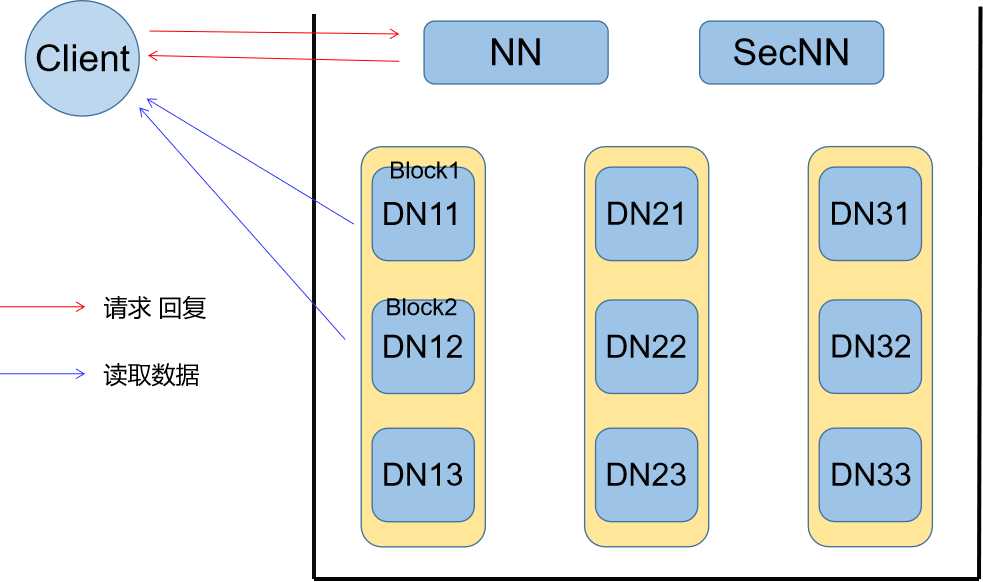
读流程相较于写流程基本一致,且实现更加简单,我就简单描述一下:
1、Client向NN节点发出读请求,包含文件名等信息
2、NN收到请求,根据文件名查找该文件所对应的所有块信息
3、NN根据块信息找到相对应的DN节点,将所有DN节点的位置及路径开销回复给Client
4、Client根据收到的DN节点信息,选取每个块所在路径开销最小的DN节点执行读取操作。
四、HDFS的高可靠性
1、NN的高可靠性
NN节点作为HDFS的管理者,里面存储了所有文件数据的元数据和节点的状态信息。一旦NN节点宕机那么所有文件的元数据将会丢失,海量的文件数据被存放在不同的DN节点上,元数据的丢失意味着丢失了查找数据的能力。为防止由于NN节点的宕机而导致的元数据丢失,我们采用NN节点的冗余备份机制。NN节点的备份分为冷备份和热备份,在第二部分也将这两个备份的概念简单说了一下,现在详细介绍一下。
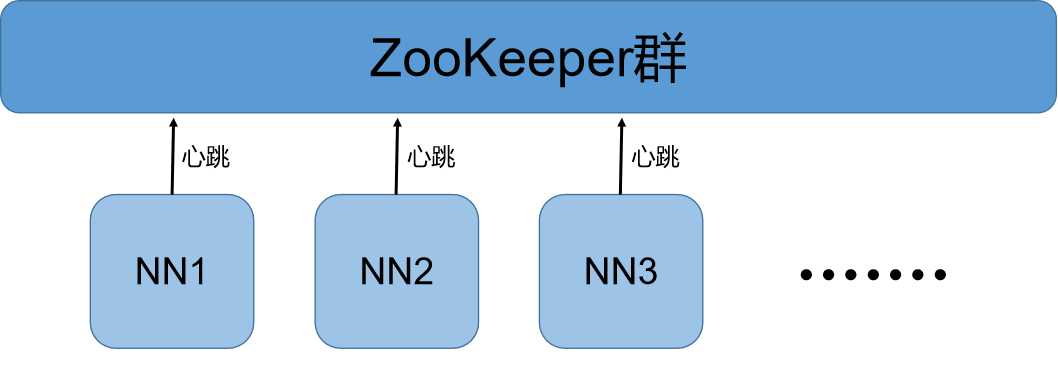
上一篇随笔简单讲到Hadoop分为三个层次,中间层负责资源协调。ZooKeeper就是协调机制,在HDFS中主要就是协调选举主备NameNode节点。每个NN节点都会通过“心跳”与ZooKeeper保持联系,报告自己的状态信息。ZooKeeper通过这些状态信息选举出主NN节点作为整个HDFS的管理节点,其他作为备份。备份NN一般不工作,但数据会与主NN节点同步更新。当主NN节点宕机后,其与ZooKeeper的联系就会中断,ZooKeeper接受不到主NN发来的心跳信息就默认主NN节点损坏,会在备选NN节点中重新选举主NN节点。虽然备NN节点不工作,但它里面的元数据信息和DN节点状态信息跟主NN节点是同步更新的,所以一旦备NN被选为主NN节点,会立刻接替主NN节点的工作。当然,这是热备份。
冷备份,即SecondaryNameNode。它与主NN节点之间有个“元数据持久化”机制
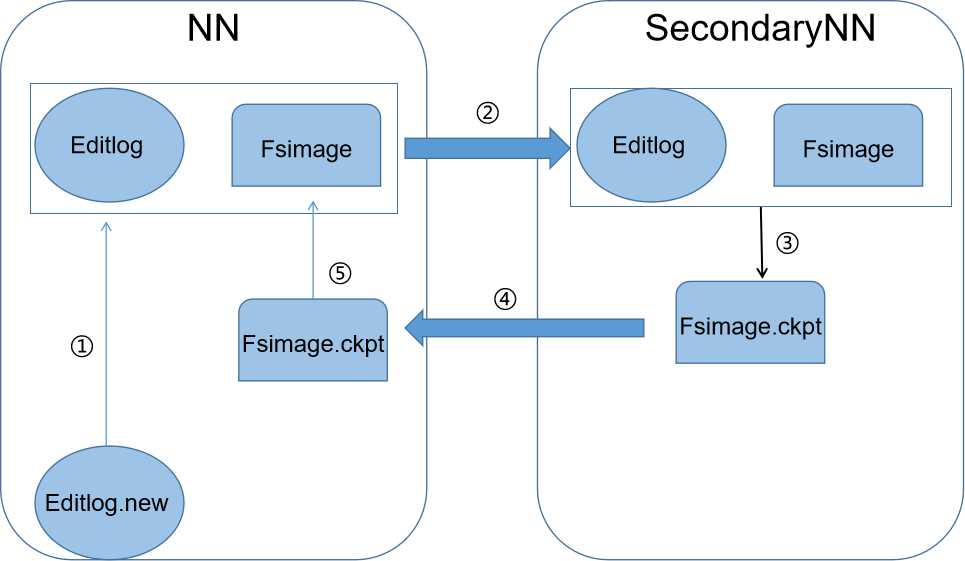
①当有对元数据执行操作时,NN节点会生成新的对应日志文件(Editlog.new)
②NN节点内存里存放的是日志文件(Editlog)和元数据镜像文件(Fsimage),SecondaryNN通过NN节点同步获取得到
③SecondaryNN中将二者合并成新的镜像文件Fsimage.ckpt文件
④SecondaryNN将新生成的镜像文件上传到主节点上
⑤Fsimage.ckpt在主节点上回滚成Fsimage文件,其实就是将原来的镜像文件更新NN
⑥此时在之前过程中新的日志文件(Editlog.new)已经变成Editlog,不在是新日志,与更新后的镜像文件重新同步到SecondaryNN上,重复以上操作
NN和SecondaryNN的工作目录存储结构完全相同,所以,当NN故障退出需要重新恢复时,可以从SecondaryNN的工作目录中将Fsimage拷贝到NN的工作目录,以恢复NN中的元数据。
2、DN的高可靠性
DN节点作为实际存储数据的执行者,其高可靠性主要就是数据的副本机制,即数据冗余存储。当数据写入HDFS时,Client有个”副本参数“设置,这就是我们对数据的备份。而且我们在备份时选择的时不同的DN节点来进行存储,一次来保证在一台DN损坏的情况下,依靠其他DN节点依然可以恢复数据。
DN节点受NN节点的监控,它们之间也有”心跳“联系的机制。DN节点定时向NN节点发送自己的状态信息,NN节点通过这些信息监控DN节点。当NN节点在一段时间内没有接受到某台DN节点的心跳信息,则认为该DN节点损坏。此时NN节点会根据自己的元数据信息确定其所存放数据的副本的DN节点,重新找一带DN节点,根据副本数据进行备份。同时修改元数据信息和DN节点状态信息。这样,通过NN节点的调控备份,始终使数据保持一定数量的副本,保证了数据的完整性。
五、总结
不总结了,睡觉了!!!
标签:html https app 世界 文件存储 之一 停止 文件的 成功
原文地址:https://www.cnblogs.com/newbiesdy/p/11295309.html