标签:str index 获取 市场 正则表达 sum port 导入 nbsp
一、需求:
对爬取的csv文件进行数据清洗
运用内容:pandas、正则表达式
二、简单分析:
 共176条数据
共176条数据
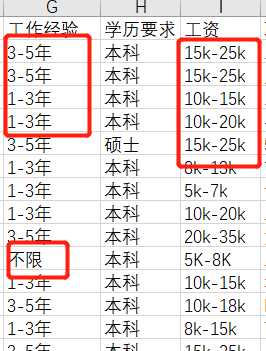
其中,分析目标以全职为准,但职位名称包含实习信息,需要删除掉。

数据方面:csv保存格式为str,运用正则表达式提取数值工作经验去平均值,工资按市场情况,取工资范围前25%。
三、代码:
import pandas as pd df = pd.read_csv(‘lagou8.4jobs.csv‘,encoding=‘utf-8-sig‘) #print(df.describe()) #共175条信息,其中包含了实习信息需要清洗掉 df.drop(df[df[‘职位名称‘].str.contains(‘实习‘)].index,inplace=True) #print(df.describe()) #67条 pattern = ‘\d+‘ #正则表达式 获取所有数字 df[‘工作经验‘] = df[‘工作经验‘].str.findall(pattern) #print(df[‘工作经验‘]) avg_work_year = [] for i in df[‘工作经验‘]: if len(i) == 0: avg_work_year.append(0) else: num = [int(j) for j in i] avg = sum(num)/2 avg_work_year.append(avg) #print(avg_work_year) df[‘工作经验‘] = avg_work_year df[‘工资‘] = df[‘工资‘].str.findall(pattern) #print(df[‘工资‘]) avg_salary = [] for i in df[‘工资‘]: num = [int(j) for j in i] #print(num) avg = num[0]+(num[1]-num[0])/4 print(avg) avg_salary.append(avg) df[‘工资‘] = avg_salary df.to_csv(‘clear_data.csv‘, index = False,encoding=‘utf-8-sig‘)
其间遇到问题:
一开始csv文件名为中文,导入期间遇到编码问题‘utf-8’无法解析,后查证修改文件名,以utf-8编码模式保存即可。
标签:str index 获取 市场 正则表达 sum port 导入 nbsp
原文地址:https://www.cnblogs.com/itljx/p/11297870.html