标签:get 均值 正则 训练 bsp std ams line copy
原文链接:https://blog.csdn.net/weixin_39175124/article/details/79463993
数据在前处理的时候,经常会涉及到数据标准化。将现有的数据通过某种关系,映射到某一空间内。常用的标准化方式是,减去平均值,然后通过标准差映射到均至为0的空间内。系统会记录每个输入参数的平均数和标准差,以便数据可以还原。
很多ML的算法要求训练的输入参数的平均值是0并且有相同阶数的方差例如:RBF核的SVM,L1和L2正则的线性回归
sklearn.preprocessing.StandardScaler能够轻松的实现上述功能。
调用方式为:
首先定义一个对象:
ss = sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
在这里
copy; with_mean;with_std
默认的值都是True.
copy 如果为false,就会用归一化的值替代原来的值;如果被标准化的数据不是np.array或scipy.sparse CSR matrix, 原来的数据还是被copy而不是被替代
with_mean 在处理sparse CSR或者 CSC matrices 一定要设置False不然会超内存
能够查询的属性:
scale_: 缩放比例,同时也是标准差
mean_: 每个特征的平均值
var_:每个特征的方差
n_sample_seen_:样本数量,可以通过patial_fit 增加
举个例子:
import numpy as np import matplotlib.pyplot as plt import pandas as pd from sklearn.preprocessing import StandardScaler #data = pd.read_csv("C:/学习/python/creditcard/creditcard.csv") x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]).reshape((3, 3)) ss = StandardScaler() print(x) ss.fit(X=x) print(ss.n_samples_seen_) print(ss.mean_) print(ss.var_) print(ss.scale_) y = ss.fit_transform(x) print(y) z = ss.inverse_transform(y) print(z)
运行结果为:
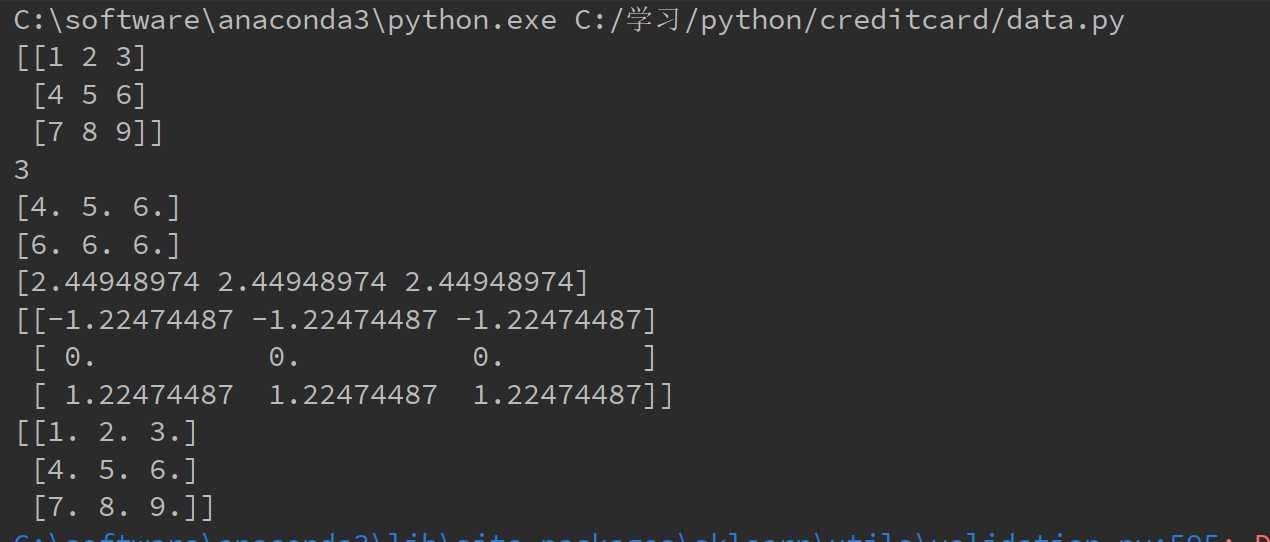
能够被调用的Methods:
fit(X,y=None):计算输入数据各特征的平均值,标准差以及之后的缩放系数 ,以后就可以按照这个数据调用transofrm()
X:训练集
y: 传入为了使得和Pipeline兼容
fit_transform(X,y=None,**fit_params): 通过fit_params调整数据X,y得到一个调整后的X ,使得每个特征的数据分布平均值为0,方差为1
X 为array:训练集
y 为标签
返回一个改变后的X
get_params(deep=True): 返回StandardScaler对象的设置参数,
inverse_transform(X,copy=None):顾名思义,就是按照缩放规律反向还原当前数据
transform(X, y=’deprecated’, copy=None):基于现有的对象规则,标准化新的参数
可以认为fit_transform()是fit()和transform()的合体。
sklearn.preprocessing.StandardScaler数据标准化
标签:get 均值 正则 训练 bsp std ams line copy
原文地址:https://www.cnblogs.com/loubin/p/11299116.html