标签:zook out 数据 hone 影响 over ima 形式 ESS
这里小编介绍两种导入数据的方式,一种是基于hive,一种是基本文件生成HFile。这种方式需要一个jar包支持:
下载地址:https://down.51cto.com/data/2464129
将其放入$HBASE_HOME/lib 并将原有的jar包复制。
其次修改hive-site.xml:
#加入:
<property>
<name>hive.aux.jars.path</name>
<value>file:///applications/hive-2.3.2/lib/hive-hbase-handler.jar,file:///applications/hive-2.3.2/lib/guava-14.0.1.jar,file:///ap plications/hbase-2.0.5/lib/hbase-common-2.0.5.jar,file:///applications/hbase-2.0.5/lib/hbase-client-2.0.5.jar,file:///application s/hive-2.3.2/lib/zookeeper-3.4.6.jar</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>将hive数据导入到hbase中:
① 创建hive表:
create table hive_hbase_test(id int,name string,age int);② 插入数据到hive表中
insert into hive_hbae_test(id,name,age) values(1,"xiaozhang","18");
insert into hive_hbase_test(id,name,age) values(2,"xiaowang","19");这里测试环境可以这样插入数据,真实环境最好使用外表。
③ 映射 Hbase 的表
create table hive_hbase_pro(row_key string,id bigint,name string,age int) STORED BY "org.apache.hadoop.hive.hbase.HBaseStorageHandler" WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:id,info:name,info:age") TBLPROPERTIES ("hbase.table.name"="hive_hbase_pro");此时在hbase中就会创建一个名为hive_hbase_pro表。
④ 插入到映射 Hbase 表中的数据
#在hive中配置如下参数:
set hive.hbase.wal.enabled=false;
set hive.hbase.bulk=true;
set hbase.client.scanner.caching=1000000;⑤导入数据:
insert overwrite table hive_hbase_pro select id as row_key,id,name,age from hive_hbase_test;此时在hive表中就有hive中的数据: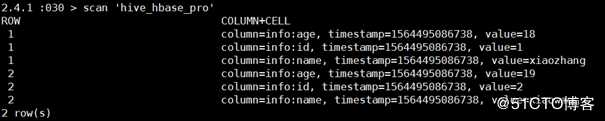
补充:如果hbase中表已经存在,此时hive中只能建立外表:
create external table hive_hbase_xiaoxu(row_key string,id bigint,name string,age int) STORED BY "org.apache.hadoop.hive.hbase.HBaseStorageHandler" WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:id,info:name,info:age") TBLPROPERTIES ("hbase.table.name"="hive_hbase_pro");这时建立的外表可以读取到hbase表中的数据。
??总结:这种方式中插入数据是按照一条一条的的形式插入的,速度是比较 慢的,如果数量级在百万千万级别机器比较好的情况下可以使用这种方式,执行的速度大概 在每秒 2-3W 之间。
其中还有Phoneix 和pig的导数,感觉和hive都大同小异,这里就不在介绍。
这种方式导入数据相当的快,因为跳过了WAL直接生产底层HFile文件。
优势:
过程中没有大量的接口调用消耗性能。
步骤:
① 将数据文件上传到HDFS中:
下载地址:https://down.51cto.com/data/2464129
这里文件内容是以逗号分隔。
$hadoop fs -put sp_address.txt /tmp/sp_addr_bulktable
② 利用 importtsv 命令生成 Hfile 文件
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator="," -Dimporttsv.bulk.output=/tmpbulkdata/sp_addr_data -Dimporttsv.columns=HBASE_ROW_KEY,sp_address:ID,sp_address:PLACE_TYPE,sp_address:PLACE_CODE,sp_address:PLACE_NAME,sp_address:UP_PLACE_CODE sp_address_bulkload "/tmp/sp_addr_bulktable"参数介绍:
-Dimporttsv.separator :指定文件的分隔符
Dimporttsv.bulk.output:生成的HFile的目录(此目录一定不存在)
Dimporttsv.columns:hbase表的关系映射
sp_address_bulkload :hbase表名(这里一定要在生成hfile之前创建hbase表)
"/tmp/sp_addr_bulktable":源数据目录
**建表语句:**create ‘sp_address_bulkload’,’ sp_address’③ 把 Hfile 文件导入到 Hbase 中
$hadoop jar /applications/hbase-2.0.5/lib/hbase-mapreduce-2.0.5.jar completebulkload /tmpbulkdata/sp_addr_data/ sp_address_bulkload这里有一个坑,网上说是在hbase-server-VRESION-hadoop2.jar 这里小编用的是2.0.5版本的,这个completebulkload 主类在hbase-mapreduce-2.0.5.jar 这个jar包下。
好处:运行该命令的本质是一个hdfs的mv操作,并不会启动MapReduce。
④ 查看hbase表
$scan ‘sp_address_bulkload‘
到此数据就被装载进入hbase中。
??当然还可以使用API的方式,但是学习成本就会翻倍,如果场景不是特别复杂的情况下,使用shell基本可以解决。
??总结:这种方式是最快的,原理是按照 Hfile 进行的,一次性处理多条数据,建议使用这种方式。在真是环境中会 相当快的快,我们测试的是 4 亿多条的数据,20 分钟搞定。可能这里看不出什么快不快,这里小编可以提供一个真实情况,256G内存的机器中,用sqoop导入5000W数据需要27分钟。
标签:zook out 数据 hone 影响 over ima 形式 ESS
原文地址:https://blog.51cto.com/14048416/2426750