标签:evel strong clust 自动部署 授权 overwrite red bin gre
环境说明:| 主机名 | 操作系统版本 | ip | docker version | kubelet version | 配置 | 备注 |
|---|---|---|---|---|---|---|
| master | Centos 7.6.1810 | 172.27.9.131 | Docker 18.09.6 | V1.14.2 | 2C2G | 备注 |
| node01 | Centos 7.6.1810 | 172.27.9.135 | Docker 18.09.6 | V1.14.2 | 2C2G | 备注 |
| node02 | Centos 7.6.1810 | 172.27.9.136 | Docker 18.09.6 | V1.14.2 | 2C2G | 备注 |
k8s集群部署详见:Centos7.6部署k8s(v1.14.2)集群
k8s学习资料详见:基本概念、kubectl命令和资料分享
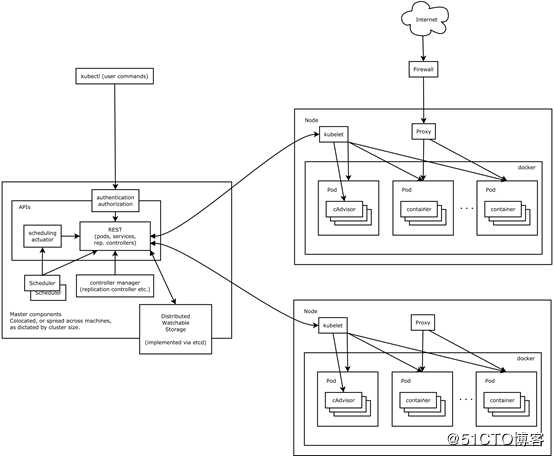

Kubelet是唯一一直作为常规系统组件来运行的组件,它把其他组件作为pod来运行。
master和node节点都可查看
[root@master ~]# systemctl status kubelet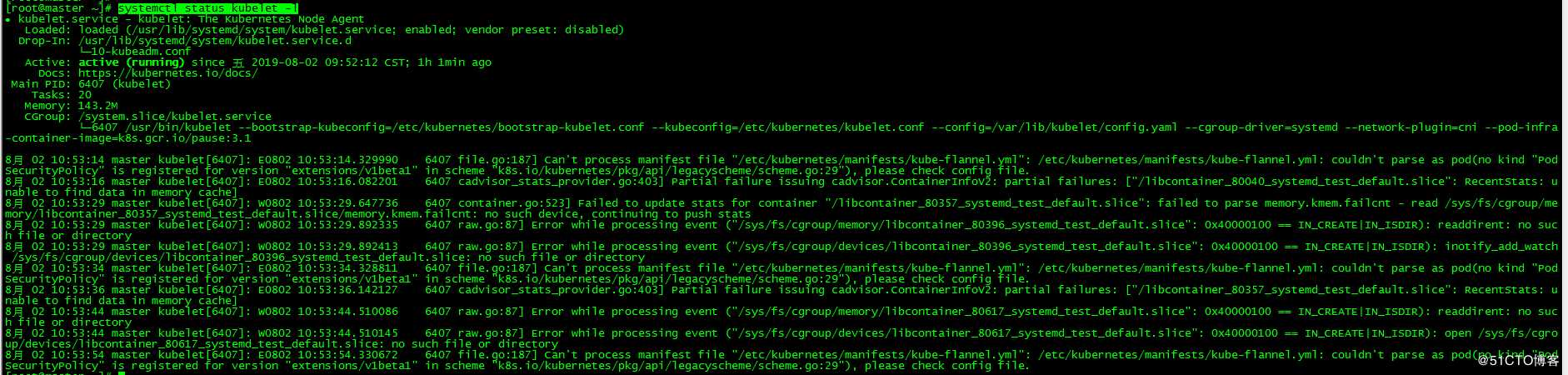
[root@master ~]# kubectl get po -o custom-columns=POD:metadata.name,NODE:spec.nodeName --sort-by spec.nodeName -n kube-system!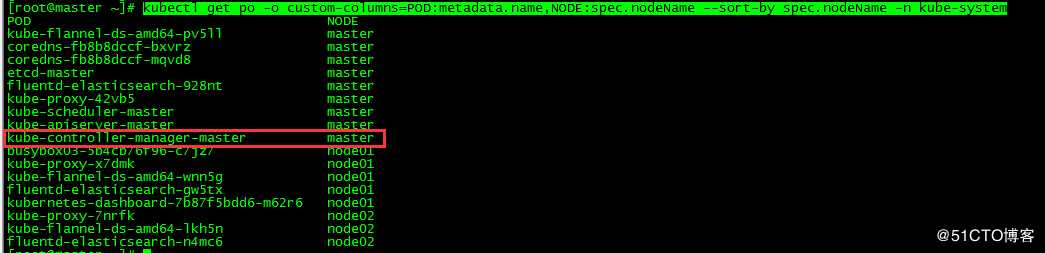
本文重点介绍核心组件controller manager
?
各资源简写查看:
[root@master ~]# kubectl api-resources 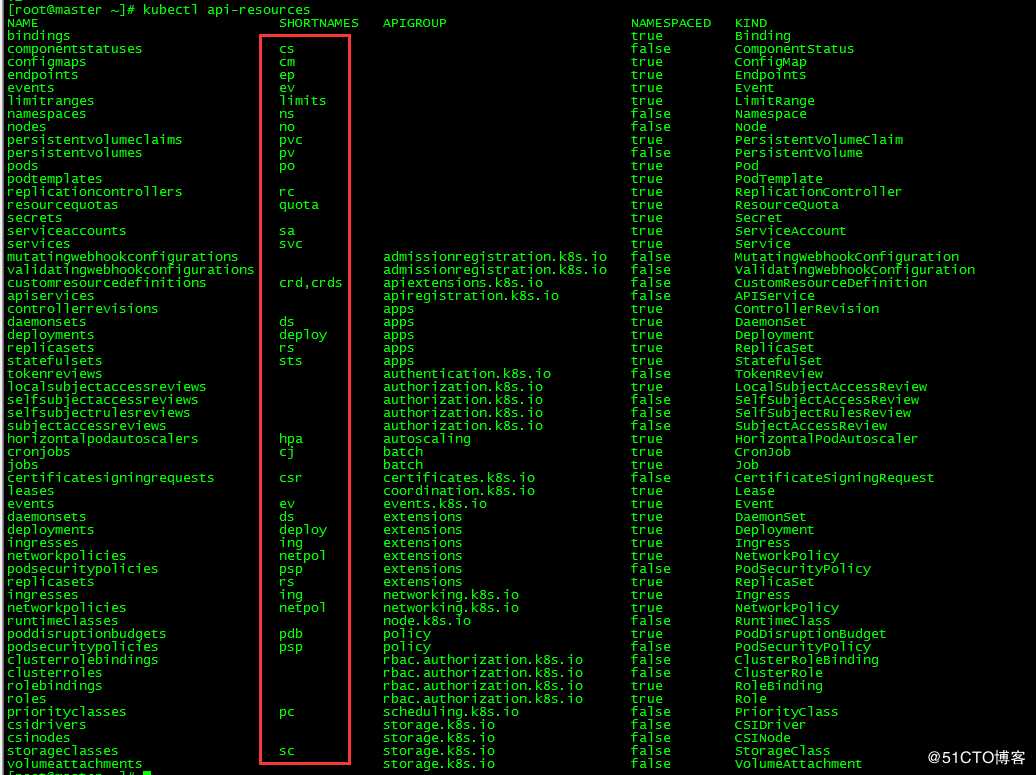
? ? Controller Manager由kube-controller-manager和cloud-controller-manager组成,是Kubernetes的大脑,它通过apiserver监控维护整个集群的状态,比如故障检测、自动扩展、滚动更新等并确保集群处于预期的工作状态。
? ? cloud-controller-manager 在 Kubernetes 启用 Cloud Provider 的时候才需要,用来配合云服务提供商的控制,如:Node Controller、Route Controller、Service Controller。
? ? Controller Manager是Kubernetes集群内部的管理控制中心, 负责Kubernetes集群内的Node、 Pod、服务端点、 服务、 资源配额、 命名空间 、服务账号等资源的管理 、 自动化部署、健康监测, 并对异常资源执行自动化修复, 确保集群各资源始终处于预期的工作状态 。 比如, 当某个Node意外若机时,Controller Manager会根据资源调度策略选择集群内其他节点自动部署原右机节点上的Pod副本 。
? ? Controller Manager是 一 个控制器集合, 包含Replication Controller、Deployment Controller、RelicaSet、StatefulSet Controller、Daemon Controller、CronJob Controller、Node Controller、Resourcequota Controller 、Namespace Controller 、ServiceAccount Controller 、Token Controller、Service Controller及Endpoint Controller等多个控制器,Controller Manager是这些控制器的核心管理者。 一般来说, 智能系统和自动系统通常会通过一个操纵系统来不断修正系统的状态。 在Kubernetes集群中, 每个控制器的核心工作原理就是:每个控制器通过API服务器来查看系统的运行状态, 并尝试着将系统状态从“ 现有状态 ”修正到“期望状态”。
ReplicationController会持续监控正在运行的pod列表,确保pod的数量始终与其标签选择器匹配,ReplicationController由三部分组成:
[root@master ~]# more nginx-rc.yaml
apiVersion: v1
kind: ReplicationController #类型为ReplicationController
metadata:
name: nginx #ReplicationController名字
spec:
replicas: 3 #pod实例数目
selector: #pod选择器
app: nginx
template: #pod模板
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
[root@master ~]# kubectl get rc
[root@master ~]# kubectl describe rc nginx 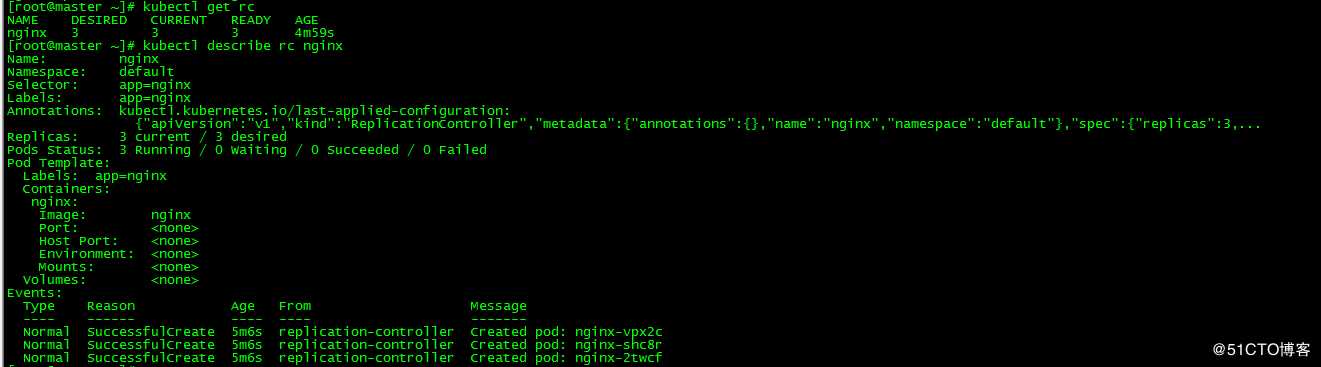
扩缩容可以采用修改pod模板和直接命令方式
[root@master ~]# kubectl edit rc nginx 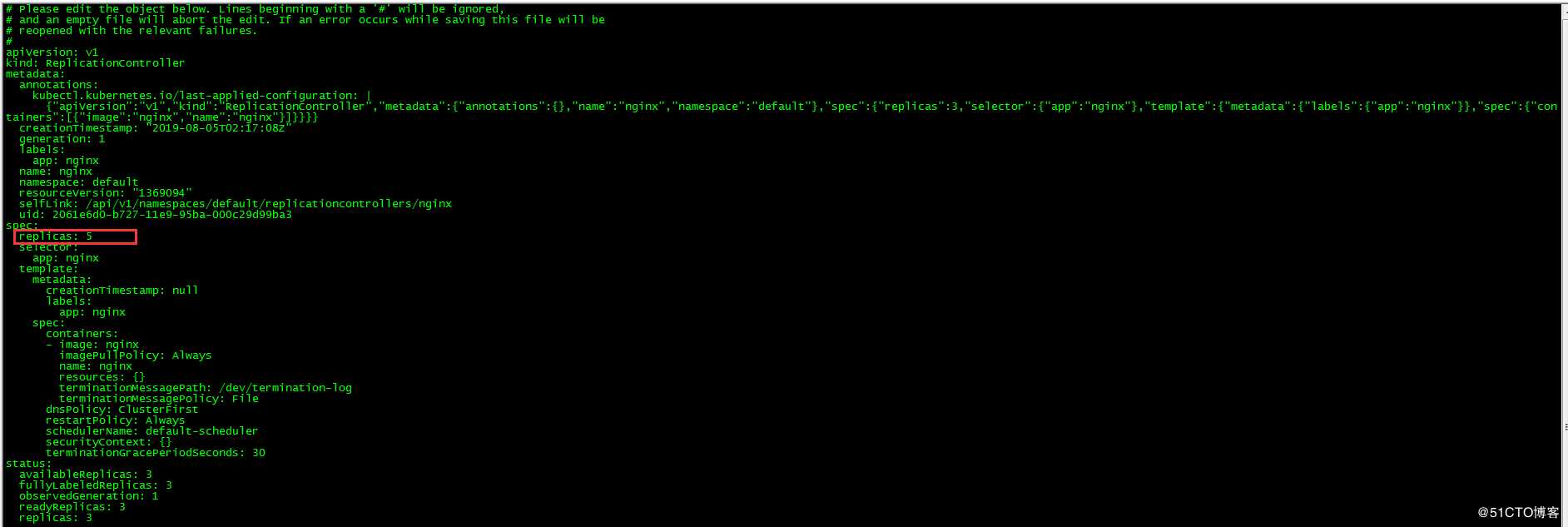

[root@master ~]# kubectl scale rc nginx --replicas=4
[root@master ~]# kubectl delete po nginx-2twcf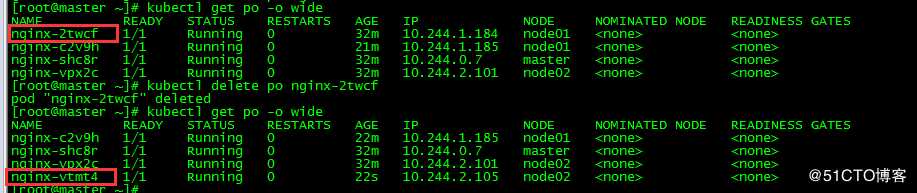
删除pod nginx-2twcf,发现该pod被删除的同时k8s自动新增一个pod nginx-vtmt4,这也印证了之前简介中讲的"ReplicationController会持续监控正在运行的pod列表,确保pod的数量始终与其标签选择器匹配"
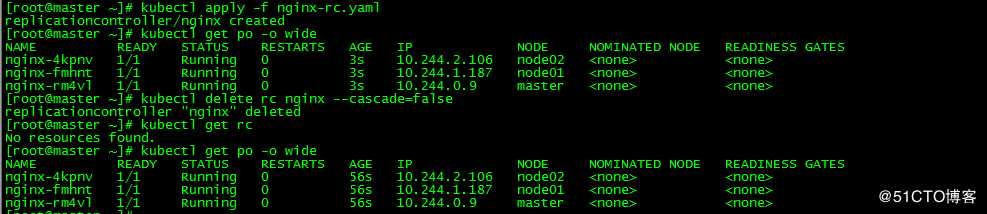
[root@master ~]# kubectl delete rc nginx 
删除ReplicationController会将其管理的pod一并删除,如果想保留pod,可以添加参数"--cascade = false"
[root@master ~]# kubectl label po nginx-28d4k env=prod[root@master ~]# kubectl get po --show-labels [root@master ~]# kubectl label po nginx-28d4k app=test --overwrite更改app=nginx的标签,这将使该pod不再与ReplicationController的标签选择器匹配,只剩两个匹配的pod,ReplicationController会启动一个新的pod nginx-64w44将总数量恢复为3个。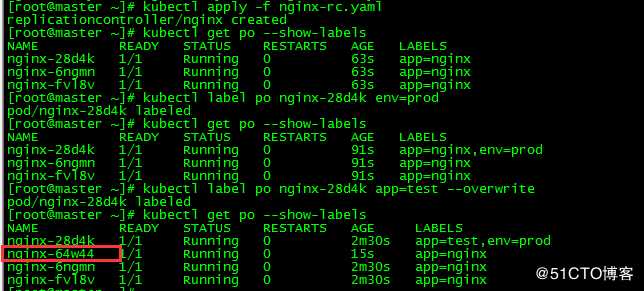
ReplicaSet的行为与ReplicationController完全相同,但pod选择器的表达能力更强,是新一代的ReplicationController,并且将其完全替换掉(ReplicationController最终将被弃用).
[root@master ~]# more httpd-rs.yaml
apiVersion: apps/v1 #api版本
kind: ReplicaSet
metadata:
name: httpd
spec:
replicas: 3
selector:
matchExpressions:
- key: app #标签名为app
operator: In #In : Label的值必须与其中一个指定的values匹配
values:
- httpd #标签值为httpd
template: #replicaset模板
metadata:
labels:
app: httpd
spec:
containers:
- name: httpd
image: httpd ReplicaSet相对于ReplicationController的主要改进是它更具表达力的标签选择器,ReplicaSet的pod选择器的表达能力更强。

[root@master ~]# kubectl get rs
[root@master ~]# kubectl describe rs httpd 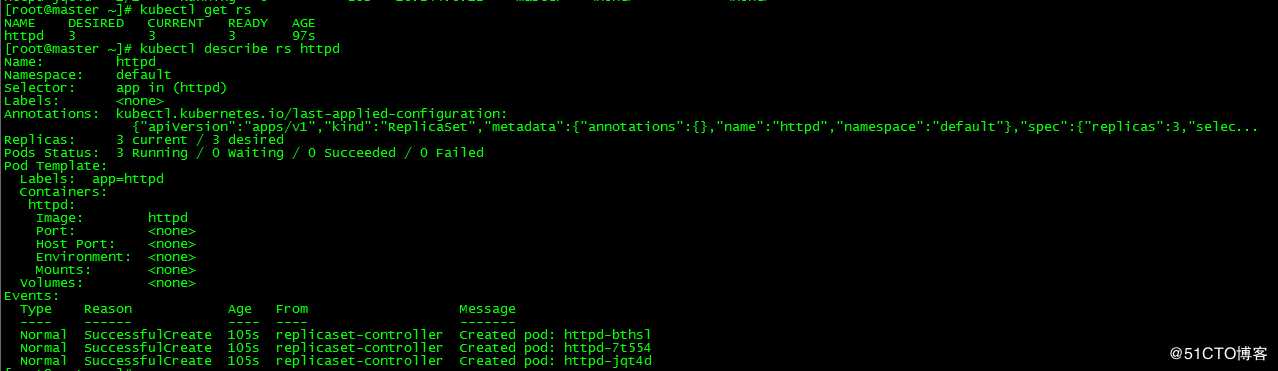
[root@master ~]# kubectl delete rs httpd同理,如需保留pod可以添加参数--cascade=false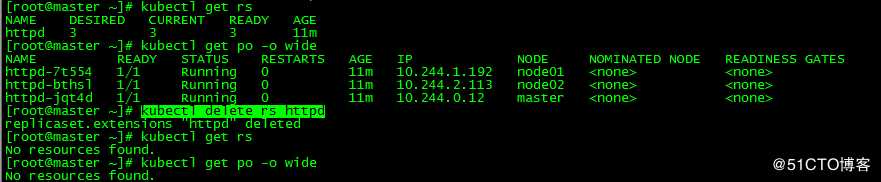
Deployment为Pod和Replica Set(下一代 Replication Controller)提供声明式更新。你只需要在Deployment中描述你想要的目标状态是什么,Deployment controller就会帮你将Pod和Replica Set的实际状态改变到你的目标状态。你可以定义一个全新的Deployment,也可以创建一个新的替换旧的Deployment。
?
Deployment的典型应用场景 包括:
Deployment相关操作详见:k8s实践(三):pod常用操作
与Replicationcontroller和ReplicaSet在Kubemetes集群上运行部署特定数量的pod不同,DaemonSet每个Node上最多只能运行一个副本,如果节点下线,DaemonSet不会在其他地方重新创建pod,当将一个新节点添加到集群中时,DaemonSet会立刻部署一个新的pod实例。如果有人无意删除了一个pod,它也会从配置的pod模板中创建新的pod。
DaemonSet保证在每个Node上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。典型的应用包括:
本文以日志搜集工具filebeat为例实践
[root@master ~]# more filebeat-ds.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat-ds
labels:
app: filebeat
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
name: filebeat
spec:
containers:
- name: filebeat
image: ikubernetes/filebeat:5.6.5-alpine
env:
- name: REDIS_HOST
value: db.ilinux.io:6379
- name: LOG_LEVEL
value: info
[root@master ~]# kubectl apply -f filebeat-ds.yaml
daemonset.apps/filebeat-ds created[root@master ~]# kubectl get ds
[root@master ~]# kubectl describe ds filebeat-ds
[root@master ~]# kubectl get po -o wide 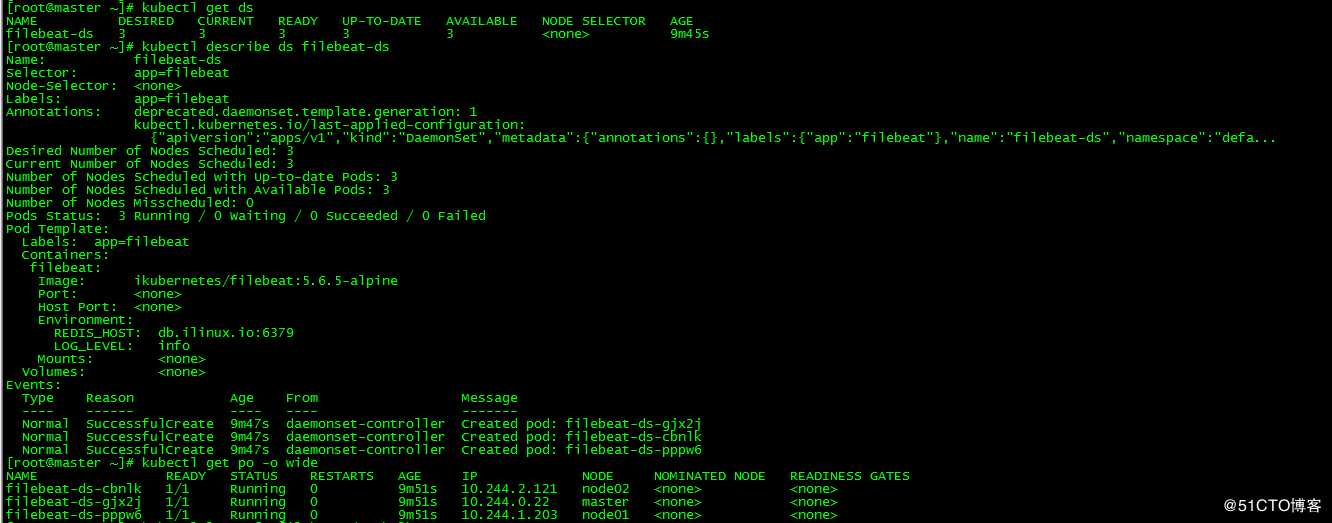
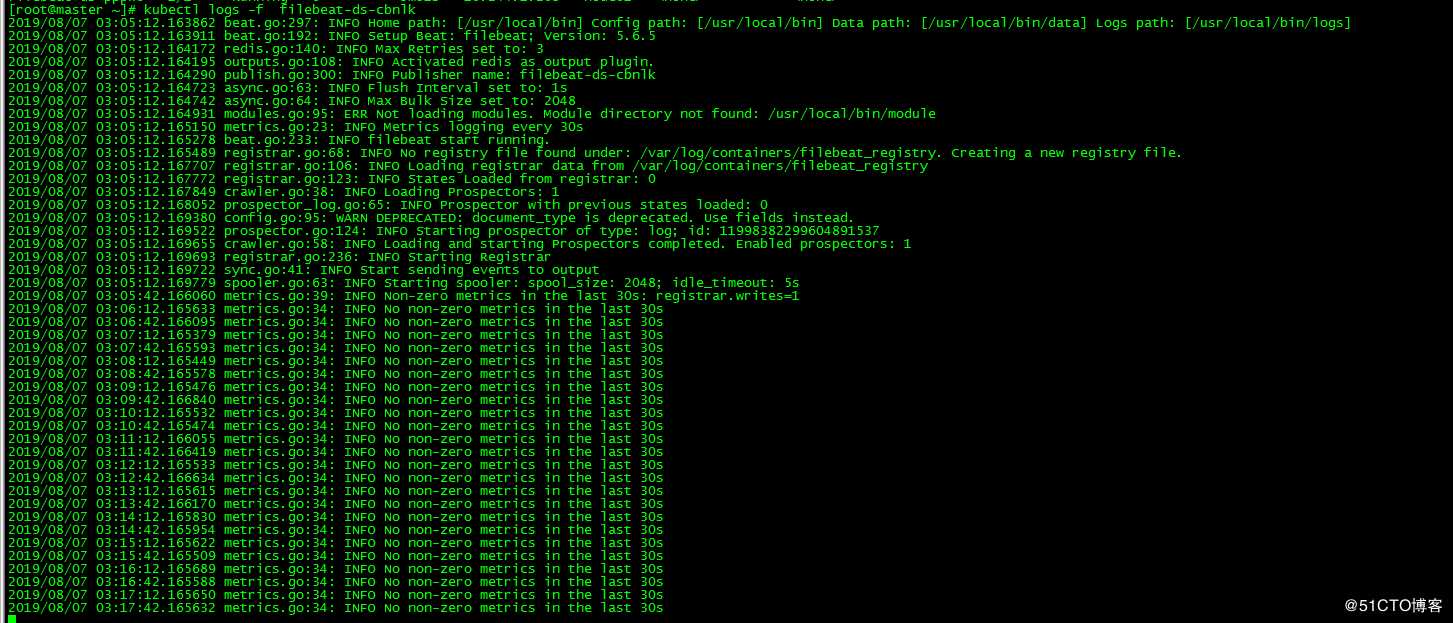
[root@master ~]# kubectl set image daemonsets filebeat-ds filebeat=ikubernetes/filebeat:5.6.6-alpineDaemonSet通过删除和新建方式更新image
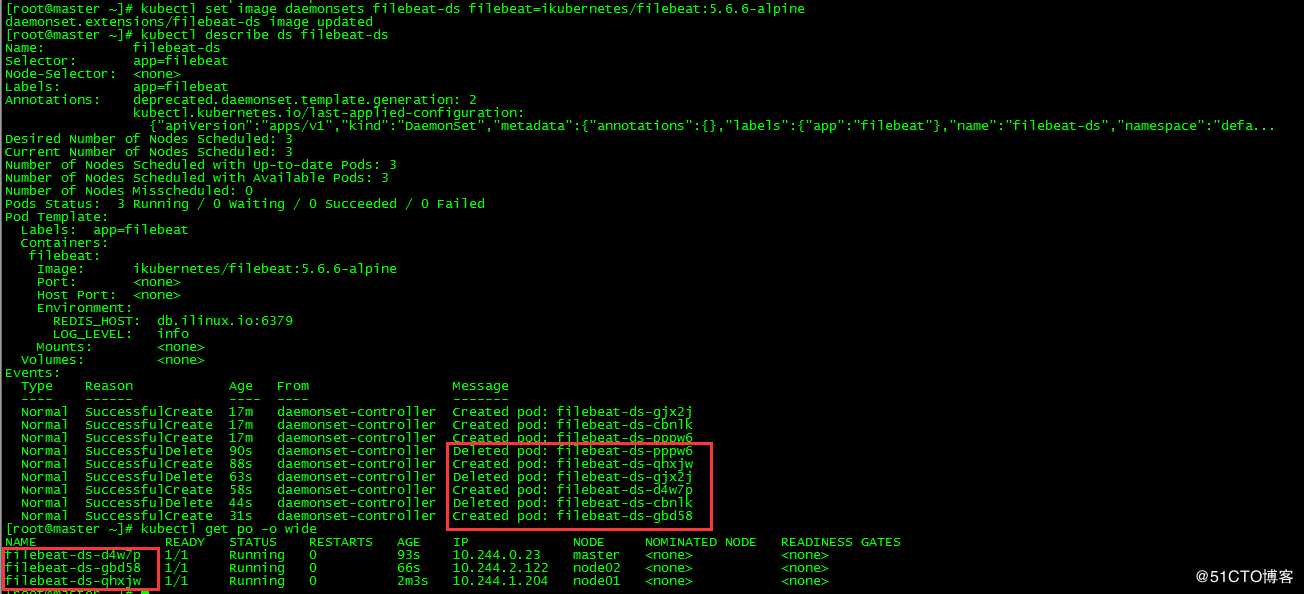
[root@master ~]# kubectl rollout history ds filebeat-ds [root@master ~]# kubectl rollout history ds filebeat-ds --revision=1
[root@master ~]# kubectl rollout history ds filebeat-ds --revision=2[root@master ~]# kubectl rollout undo ds filebeat-ds --to-revision=1[root@master ~]# kubectl rollout status ds/filebeat-ds
daemon set "filebeat-ds" successfully rolled out
[root@master ~]# kubectl describe ds filebeat-ds |grep Image
Image: ikubernetes/filebeat:5.6.5-alpine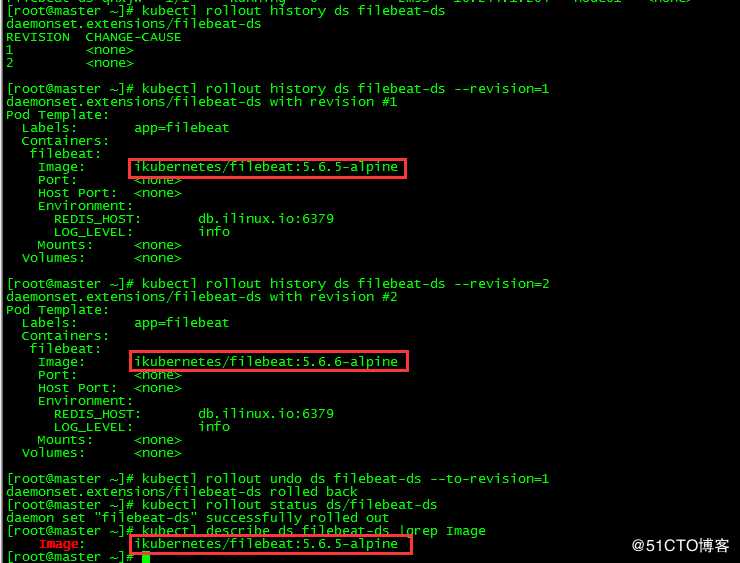
[root@master ~]# kubectl delete ds filebeat-ds
daemonset.extensions "filebeat-ds" deleted从程序的运行形态上来区分,我们可以将Pod分为两类:长时运行服务(http server、daemon、mysql)和一次性任务(如并行数据计算、测试、批处理程序等)。ReplicationController、 ReplicaSet和DaemonSet创建的Pod都是长时运行服务,而Job创建的Pod都是一次性服务。
[root@master ~]# more job.yaml
apiVersion: batch/v1 #api版本为batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never #设置容器失败后不重启,即直接新建pod
backoffLimit: 4 #限制新建pod数目,默认为6
[root@master ~]# kubectl apply -f job.yaml
job.batch/pi created[root@master ~]# kubectl get job
[root@master ~]# kubectl get po -o wide [root@master ~]# kubectl logs pi-g2499 
该job为求圆周率精确至2000位
[root@master ~]# more multi-job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: multi-job
spec:
completions: 10 #设置Job成功完成Pod的总数
parallelism: 2 #pod并行执行数
template:
metadata:
labels:
app: multi-job
spec:
restartPolicy: OnFailure #设置容器失败后重启
containers:
- name: busybox
image: busybox
[root@master ~]# kubectl apply -f multi-job.yaml
job.batch/multi-job created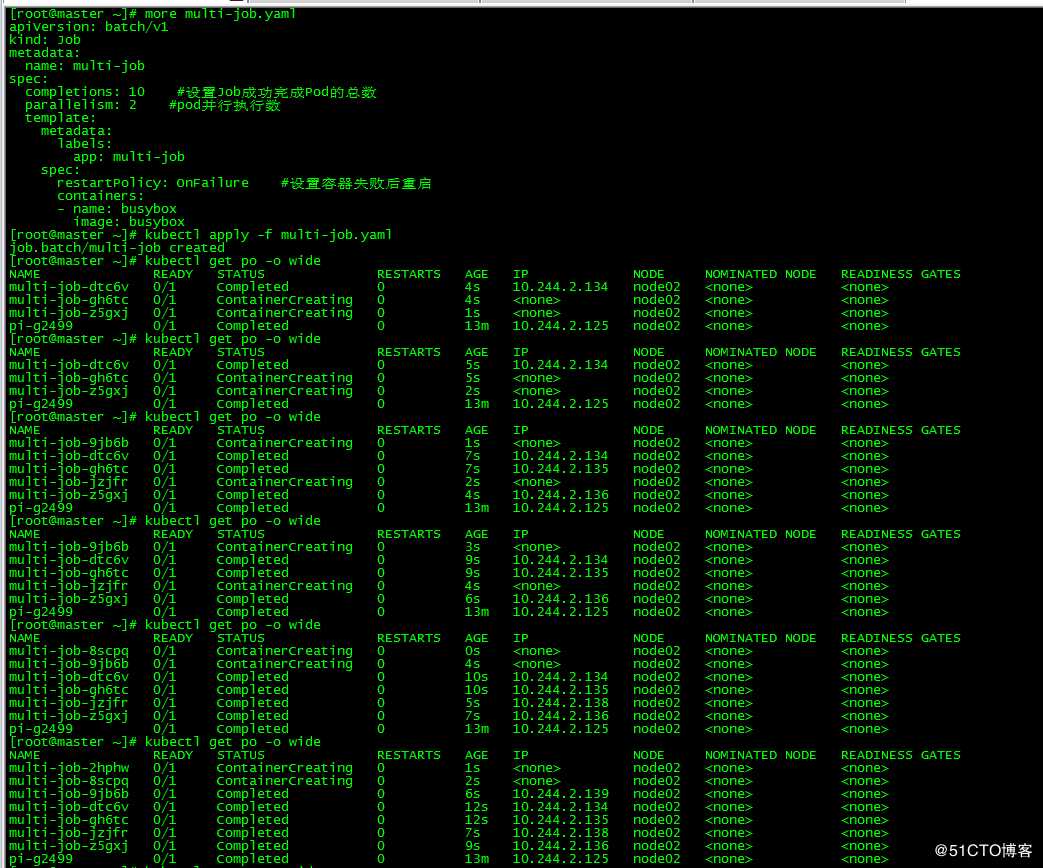

每次同时运行两个job,最终运行的pod数为10
[root@master ~]# more cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
[root@master ~]# kubectl apply -f cronjob.yaml
cronjob.batch/hello created[root@master ~]# kubectl get cronjobs
[root@master ~]# kubectl get job --watch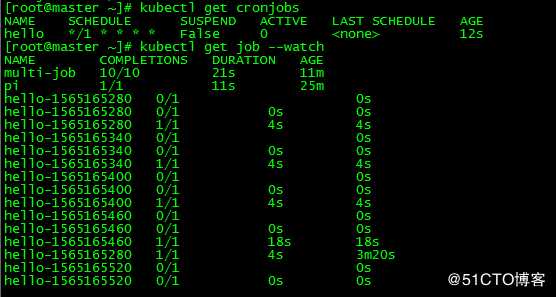
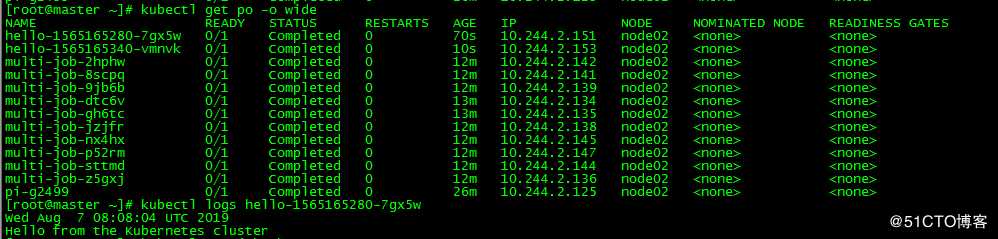
每隔一分钟就会生成一个job
[root@master ~]# kubectl delete job pi multi-job
[root@master ~]# kubectl delete cronjobs hello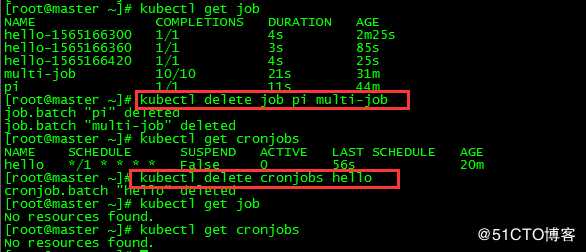
本文所有脚本和配置文件已上传github:https://github.com/loong576/k8s-Controller.git
标签:evel strong clust 自动部署 授权 overwrite red bin gre
原文地址:https://blog.51cto.com/3241766/2427471