标签:可用性 策略 集群 案例 命名 观察 默认 不同 状态
1、Kubernetes代码托管在GitHub上:https://github.com/kubernetes/kubernetes/。
2、Kubernetes是一个开源的,容器集群管理系统,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。通过Kubernetes你可以:
3、Kubernetes一个核心的特点就是能够自主的管理容器来保证云平台中的容器按照用户的期望状态运行着(比如用户想让apache一直运行,用户不需要关心怎么去做,Kubernetes会自动去监控,然后去重启,新建,总之,让apache一直提供服务),管理员可以加载一个微型服务,让规划器来找到合适的位置,同时,Kubernetes也系统提升工具以及人性化方面,让用户能够方便的部署自己的应用(就像canary deployments)。
4、现在Kubernetes着重于不间断的服务状态(比如web服务器或者缓存服务器)和原生云平台应用(Nosql),在不久的将来会支持各种生产云平台中的各种服务,例如,分批,工作流,以及传统数据库。
5、在Kubenetes中,所有的容器均在Pod中运行,一个Pod可以承载一个或者多个相关的容器,在后边的案例中,同一个Pod中的容器会部署在同一个物理机器上并且能够共享资源。一个Pod也可以包含O个或者多个磁盘卷组(volumes),这些卷组将会以目录的形式提供给一个容器,或者被所有Pod中的容器共享,对于用户创建的每个Pod,系统会自动选择那个健康并且有足够容量的机器,然后创建类似容器的容器,当容器创建失败的时候,容器会被node agent自动的重启,这个node agent叫kubelet,但是,如果是Pod失败或者机器,它不会自动的转移并且启动,除非用户定义了 replication controller。
6、用户可以自己创建并管理Pod,Kubernetes将这些操作简化为两个操作:基于相同的Pod配置文件部署多个Pod复制品;创建可替代的Pod当一个Pod挂了或者机器挂了的时候。而Kubernetes API中负责来重新启动,迁移等行为的部分叫做“replication controller”,它根据一个模板生成了一个Pod,然后系统就根据用户的需求创建了许多冗余,这些冗余的Pod组成了一个整个应用,或者服务,或者服务中的一层。一旦一个Pod被创建,系统就会不停的监控Pod的健康情况以及Pod所在主机的健康情况,如果这个Pod因为软件原因挂掉了或者所在的机器挂掉了,replication controller 会自动在一个健康的机器上创建一个一摸一样的Pod,来维持原来的Pod冗余状态不变,一个应用的多个Pod可以共享一个机器。
7、我们经常需要选中一组Pod,例如,我们要限制一组Pod的某些操作,或者查询某组Pod的状态,作为Kubernetes的基本机制,用户可以给Kubernetes Api中的任何对象贴上一组 key:value的标签,然后,我们就可以通过标签来选择一组相关的Kubernetes Api 对象,然后去执行一些特定的操作,每个资源额外拥有一组(很多) keys 和 values,然后外部的工具可以使用这些keys和vlues值进行对象的检索,这些Map叫做annotations(注释)。
8、Kubernetes支持一种特殊的网络模型,Kubernetes创建了一个地址空间,并且不动态的分配端口,它可以允许用户选择任何想使用的端口,为了实现这个功能,它为每个Pod分配IP地址。
9、现代互联网应用一般都会包含多层服务构成,比如web前台空间与用来存储键值对的内存服务器以及对应的存储服务,为了更好的服务于这样的架构,Kubernetes提供了服务的抽象,并提供了固定的IP地址和DNS名称,而这些与一系列Pod进行动态关联,这些都通过之前提到的标签进行关联,所以我们可以关联任何我们想关联的Pod,当一个Pod中的容器访问这个地址的时候,这个请求会被转发到本地代理(kube proxy),每台机器上均有一个本地代理,然后被转发到相应的后端容器。Kubernetes通过一种轮训机制选择相应的后端容器,这些动态的Pod被替换的时候,Kube proxy时刻追踪着,所以,服务的 IP地址(dns名称),从来不变。
10、所有Kubernetes中的资源,比如Pod,都通过一个叫URI的东西来区分,这个URI有一个UID,URI的重要组成部分是:对象的类型(比如pod),对象的名字,对象的命名空间,对于特殊的对象类型,在同一个命名空间内,所有的名字都是不同的,在对象只提供名称,不提供命名空间的情况下,这种情况是假定是默认的命名空间。UID是时间和空间上的唯一。
1、可移植:支持公有云,私有云,混合云,多重云(multi-cloud)
2、可扩展:模块化, 插件化, 可挂载, 可组合
3、自动化:自动部署,自动重启,自动复制,自动伸缩/扩展
Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc),一切都基于分布式的存储系统。下面这张图是Kubernetes的架构图。
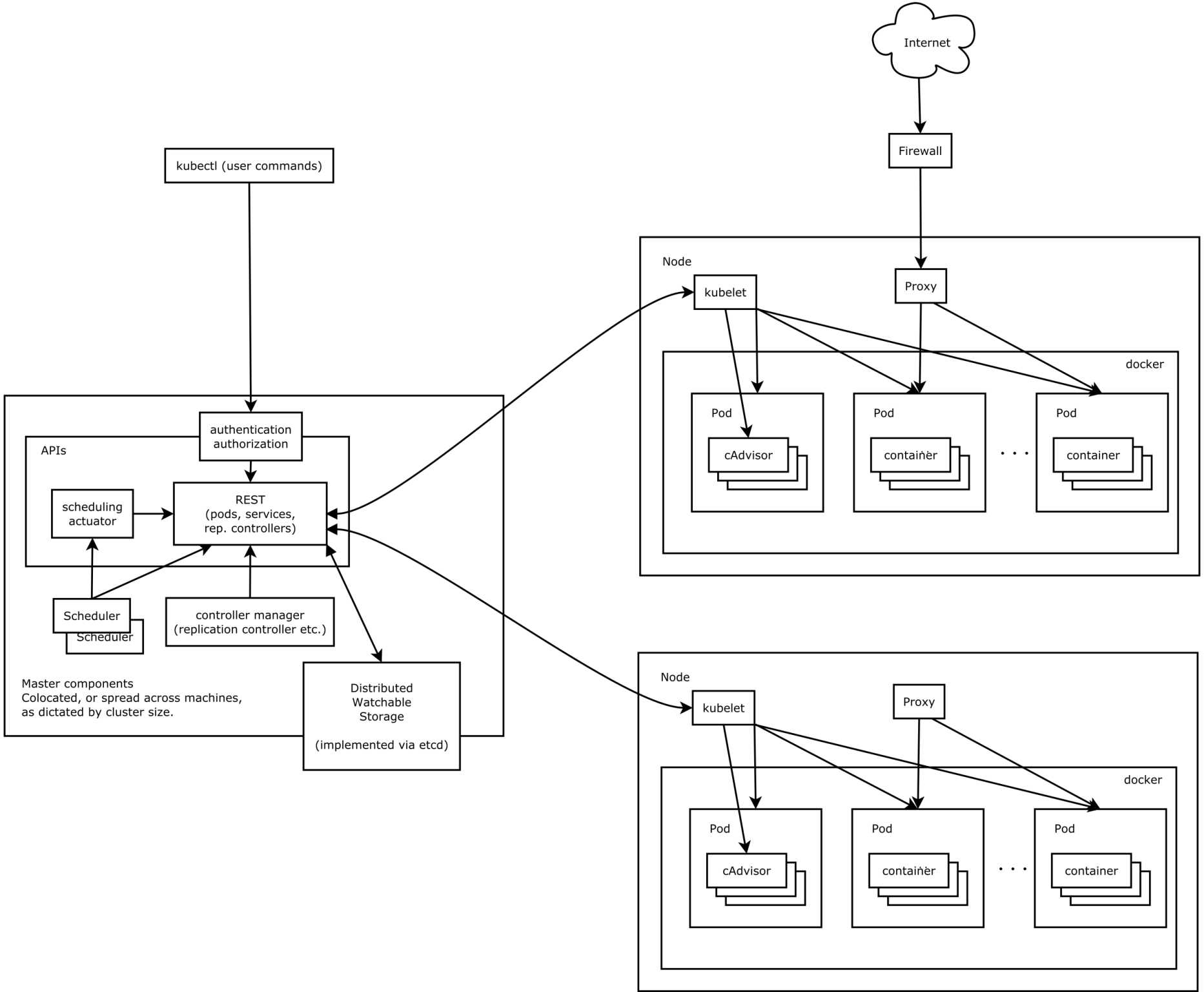
① 在这张系统架构图中,我们把服务分为运行在工作节点上的服务和组成集群级别控制板的服务。
② Kubernetes节点有运行应用容器必备的服务,而这些都是受Master的控制。
③ 每次个节点上当然都要运行Docker。Docker来负责所有具体的映像下载和容器运行。
④ Kubernetes主要由以下几个核心组件组成:
⑤ 除了核心组件,还有一些推荐的Add-ons:
(1)kubelet
kubelet负责管理pods和它们上面的容器,images镜像、volumes、etc。
(2)kube-proxy
每一个节点也运行一个简单的网络代理和负载均衡(详见services FAQ )(PS:官方 英文)。 正如Kubernetes API里面定义的这些服务(详见the services doc)(PS:官方 英文)也可以在各种终端中以轮询的方式做一些简单的TCP和UDP传输。
服务端点目前是通过DNS或者环境变量( Docker-links-compatible 和 Kubernetes{FOO}_SERVICE_HOST 及 {FOO}_SERVICE_PORT 变量都支持)。这些变量由服务代理所管理的端口来解析。
(3)Kubernetes控制面板
Kubernetes控制面板可以分为多个部分。目前它们都运行在一个master 节点,然而为了达到高可用性,这需要改变。不同部分一起协作提供一个统一的关于集群的视图。
(4)etcd
所有master的持续状态都存在etcd的一个实例中。这可以很好地存储配置数据。因为有watch(观察者)的支持,各部件协调中的改变可以很快被察觉。
(5)Kubernetes API Server
API服务提供Kubernetes API (PS:官方 英文)的服务。这个服务试图通过把所有或者大部分的业务逻辑放到不两只的部件中从而使其具有CRUD特性。它主要处理REST操作,在etcd中验证更新这些对象(并最终存储)。
(6)Scheduler
调度器把未调度的pod通过binding api绑定到节点上。调度器是可插拔的,并且我们期待支持多集群的调度,未来甚至希望可以支持用户自定义的调度器。
(7)Kubernetes控制管理服务器
所有其它的集群级别的功能目前都是由控制管理器所负责。例如,端点对象是被端点控制器来创建和更新。这些最终可以被分隔成不同的部件来让它们独自的可插拔。
replicationcontroller(PS:官方 英文)是一种建立于简单的 pod API之上的一种机制。一旦实现,我们最终计划把这变成一种通用的插件机制。
标签:可用性 策略 集群 案例 命名 观察 默认 不同 状态
原文地址:https://www.cnblogs.com/jinyuanliu/p/11272114.html