标签:工作 传输层 默认 更换 encode 其他应用 绑定 bsp 如何
socket(套接字):
是一个抽象层,应用程序可以通过它发送或接收数据,可对其进行像对文件一样的打开、读写
和关闭等操作。套接字允许应用程序将I/O插入到网络中,并与网络中的其他应用程序进行通信。网络套接字是IP地址与端口的组。
传输层实现端到端的通信,因此,每一个传输层连接有两个端点。那么,传输层连接的端点是什么呢?不是主
机,不是主机的ip地址,不是应用进程,也不是传输层的协议端口。传输层连接的端点叫做套接字(socket)。
所谓套接字,实际上是一个通信端点,每个套接字都有一个套接字序号,包括主机的IP地址与一个16位的主机端
口号,即形如(主机IP地址:端口号)。例如,如果IP地址是210.37.145.1,而端口号是23,那么得到套接字就是(210.37.145.1:23)。
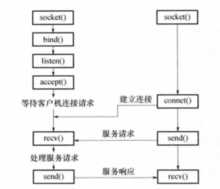
代码实现:
# 服务端.py文件
import socket
server = socket.socket() # 买手机 不传参数默认用的就是TCP协议
server.bind((‘127.0.0.1‘,8080)) # bind((host,port)) 插电话卡 绑定ip和端口
server.listen(5) # 开机 半连接池
conn, addr = server.accept() # 接听电话 等着别人给你打电话 阻塞
data = conn.recv(1024) # 听别人说话 接收1024个字节数据 阻塞
print(data)
conn.send(b‘hello baby~‘) # 给别人回话
conn.close() # 挂电话
server.close() # 关机
# 客户端.py文件
import socket
client = socket.socket() # 拿电话
client.connect((‘127.0.0.1‘,8080)) # 拨号 写的是对方的ip和port
client.send(b‘hello world!‘) # 对别人说话
data = client.recv(1024) # 听别人说话
print(data)
client.close() # 挂电话
TCP黏包问题:
TCP为了保证可靠传输,尽量减少额外开销(每次发包都要验证),因此采用了流式传输,面向流的传输,相
对于面向消息的传输,可以减少发送包的数量,从而减少了额外开销。但是,对于数据传输频繁的程序来讲,
使用TCP可能会容易粘包。当然,对接收端的程序来讲,如果机器负荷很重,也会在接收缓冲里粘包。这样,
就需要接收端额外拆包,增加了工作量。因此,这个特别适合的是数据要求可靠传输,但是不需要太频繁传输
的场合(两次操作间隔100ms,具体是由TCP等待发送间隔决定的,取决于内核中的socket的写法)
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前
一包数据的尾。出现粘包现象的原因是多方面的,它既可能由发送方造成,也可能由接收方造成。
TCP黏包问题演示:
# 服务端.py代码演示:
import socket
server = socket.socket() # 买手机 不传参数默认用的就是TCP协议
server.bind((‘127.0.0.1‘,8080)) # bind((host,port)) 插电话卡 绑定ip和端口
server.listen(5) # 开机 半连接池
conn, addr = server.accept() # 接听电话 等着别人给你打电话 阻塞
data = conn.recv(5) # 听别人说话 接收1024个字节数据 阻塞
print(data)
data = conn.recv(5) # 听别人说话 接收1024个字节数据 阻塞
print(data)
data = conn.recv(4) # 听别人说话 接收1024个字节数据 阻塞
print(data)
# 客户端.py代码演示:
import socket
client = socket.socket() # 拿电话
client.connect((‘127.0.0.1‘,8080)) # 拨号 写的是对方的ip和port
client.send(b‘hello‘)
client.send(b‘world‘)
client.send(b‘baby‘)
解决黏包问题:
对于发送方引起的粘包现象,用户可通过编程设置来避免,TCP提供了强制数据立即传送的操作指令push,
TCP软件收到该操作指令后,就立即将本段数据发送出去,而不必等待发送缓冲区满。这种编程设置方法虽然
可以避免发送方引起的粘包,但它关闭了优化算法,降低了网络发送效率,影响应用程序的性能,一般不建议
使用。
对于接收方引起的粘包,则可通过优化程序设计、精简接收进程工作量、提高接收进程优先级等措施,使其
及时接收数据,从而尽量避免出现粘包现象。这种方法只能减少出现粘包的可能性,但并不能完全避免粘包,
当发送频率较高时,或由于网络突发可能使某个时间段数据包到达接收方较快,接收方还是有可能来不及接
收,从而导致粘包。
由接收方控制,将一包数据按结构字段,人为控制分多次接收,然后合并,通过这种手段来避免粘包。这种
方法虽然避免了粘包,但应用程序的效率较低,对实时应用的场合不适合。
一种比较周全的对策是:接收方创建一预处理线程,对接收到的数据包进行预处理,将粘连的包分开;具体操
作为:
服务端
1.先制作一个发送给客户端的字典
2.制作字典的报头
3.发送字典的报头
4.发送字典
5.再发真实数据
客户端
1.先接受字典的报头
2.解析拿到字典的数据长度
3.接受字典
4.从字典中获取真实数据的长度
5.接受真实数据
代码演示实现:
# 服务端代.py码演示:
import socket
import subprocess
import struct
import json
server = socket.socket()
server.bind((‘127.0.0.1‘,8080))
server.listen(5)
while True:
conn, addr = server.accept()
while True:
try:
cmd = conn.recv(1024)
if len(cmd) == 0:break
cmd = cmd.decode(‘utf-8‘)
obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
res = obj.stdout.read() + obj.stderr.read()
d = {‘name‘:‘jason‘,‘file_size‘:len(res),‘info‘:‘asdhjkshasdad‘}
json_d = json.dumps(d)
# 1.先制作一个字典的报头
header = struct.pack(‘i‘,len(json_d))
# 2.发送字典报头
conn.send(header)
# 3.发送字典
conn.send(json_d.encode(‘utf-8‘))
# 4.再发真实数据
conn.send(res)
# conn.send(obj.stdout.read())
# conn.send(obj.stderr.read())
except ConnectionResetError:
break
conn.close()
# 客户端.py代码演示:
import socket
import struct
import json
client = socket.socket()
client.connect((‘127.0.0.1‘,8080))
while True:
msg = input(‘>>>:‘).encode(‘utf-8‘)
if len(msg) == 0:continue
client.send(msg)
# 1.先接受字典报头
header_dict = client.recv(4)
# 2.解析报头 获取字典的长度
dict_size = struct.unpack(‘i‘,header_dict)[0] # 解包的时候一定要加上索引0
# 3.接收字典数据
dict_bytes = client.recv(dict_size)
dict_json = json.loads(dict_bytes.decode(‘utf-8‘))
# 4.从字典中获取信息
print(dict_json)
recv_size = 0
real_data = b‘‘
while recv_size < dict_json.get(‘file_size‘): # real_size = 102400
data = client.recv(1024)
real_data += data
recv_size += len(data)
print(real_data.decode(‘gbk‘))
连接循环+通讯循环:
# 服务端.py代码演示:
import socket
"""
服务端
固定的ip和port
24小时不间断提供服务
"""
server = socket.socket() # 生成一个对象
server.bind((‘127.0.0.1‘,8080)) # 绑定ip和port
server.listen(5) # 半连接池
while True:
conn, addr = server.accept() # 等到别人来 conn就类似于是双向通道
print(addr) # (‘127.0.0.1‘, 51323) 客户端的地址
while True:
try:
data = conn.recv(1024)
print(data) # b‘‘ 针对mac与linux 客户端异常退出之后 服务端不会报错 只会一直收b‘‘
if len(data) == 0:break
conn.send(data.upper())
except ConnectionResetError as e:
print(e)
break
conn.close()
# 客户端.py代码演示
import socket
client = socket.socket()
client.connect((‘127.0.0.1‘,8080))
while True:
msg = input(‘>>>:‘).encode(‘utf-8‘)
if len(msg) == 0:continue
client.send(msg)
data = client.recv(1024)
print(data)
struct模块:
struct会按照指定格式讲python数据转换为字符串,该字符串为字节流,比如网络传输时不能传输int,因此先将int转换
为字节流,然后再发送;但是它会按照指定格式将字节流转换为python指定的数据类型,处理二进制数据,如
果使用struct来处理文件的话,需要用“wb”;“rb”以二进制读写的方式来处理文件。
该对象可以根据格式化字符串的格式来读写二进制数据。第一个参数(格式化字符串)可以指定字节的顺序。
默认是根据系统来确定,也提供自定义的方式,只需要在前面加上特定字符即可。首先将数据对象放在了一个
元组中,然后创建一个Struct对象,并使用pack()方法打包该元组;最后解包返回该元组。
当打包或者解包是,需要按照特定的方式来打包或者解包,该方式就是格式化字符串,它指定了数据类型,除
此之外还用于控制字节顺序、大小和对其方式的特殊字符。
import struct
res = ‘akdjsladlkjafkldjfgsdafhjksdfhfdgfdsgdfgssgddklsajkldsa‘
print(‘最原始的‘,len(res))
# 当原始数据特别大的时候 i模式打包不了 需要更换模式?
# 如果遇到数据量特别大的情况 该如何解决?
d = {
‘name‘:‘jason‘,
‘file_size‘:345543543534535452453453245654654656543455,
‘info‘:‘为大家的骄傲‘
}
import json
json_d = json.dumps(d)
print(len(json_d))
res1 = struct.pack(‘i‘,len(json_d))
print(len(res1))
res2 = struct.unpack(‘i‘,res1)[0]
print(‘解包之后的‘,res2)
标签:工作 传输层 默认 更换 encode 其他应用 绑定 bsp 如何
原文地址:https://www.cnblogs.com/sweet-i/p/11317965.html