标签:tick tst generate int login ESS ping 更改 inf

以为最多10亿就算不错的了。没想过仅过了几天就破了10亿。接着头条又突破20亿--------目前11天27亿,势头增长依然很猛!那笔者就很好奇人们是怎么看待这一步电影的呢?
陪伴过不少人成长的一部动画片吧,也是记忆中算得上最好看的动画片之一了。里面的哪吒、小猪熊、申公豹、石鸡娘娘令人历历在目。我们或许都被哪吒的敢打敢为、勇敢和天真所感动!

哪吒动画电影的评价状况。那么就选择猫眼票房或者豆瓣的短评爬下来分析了。哪吒短评的界面。F12打开调试点击页面下一页会发现有ajax数据交互。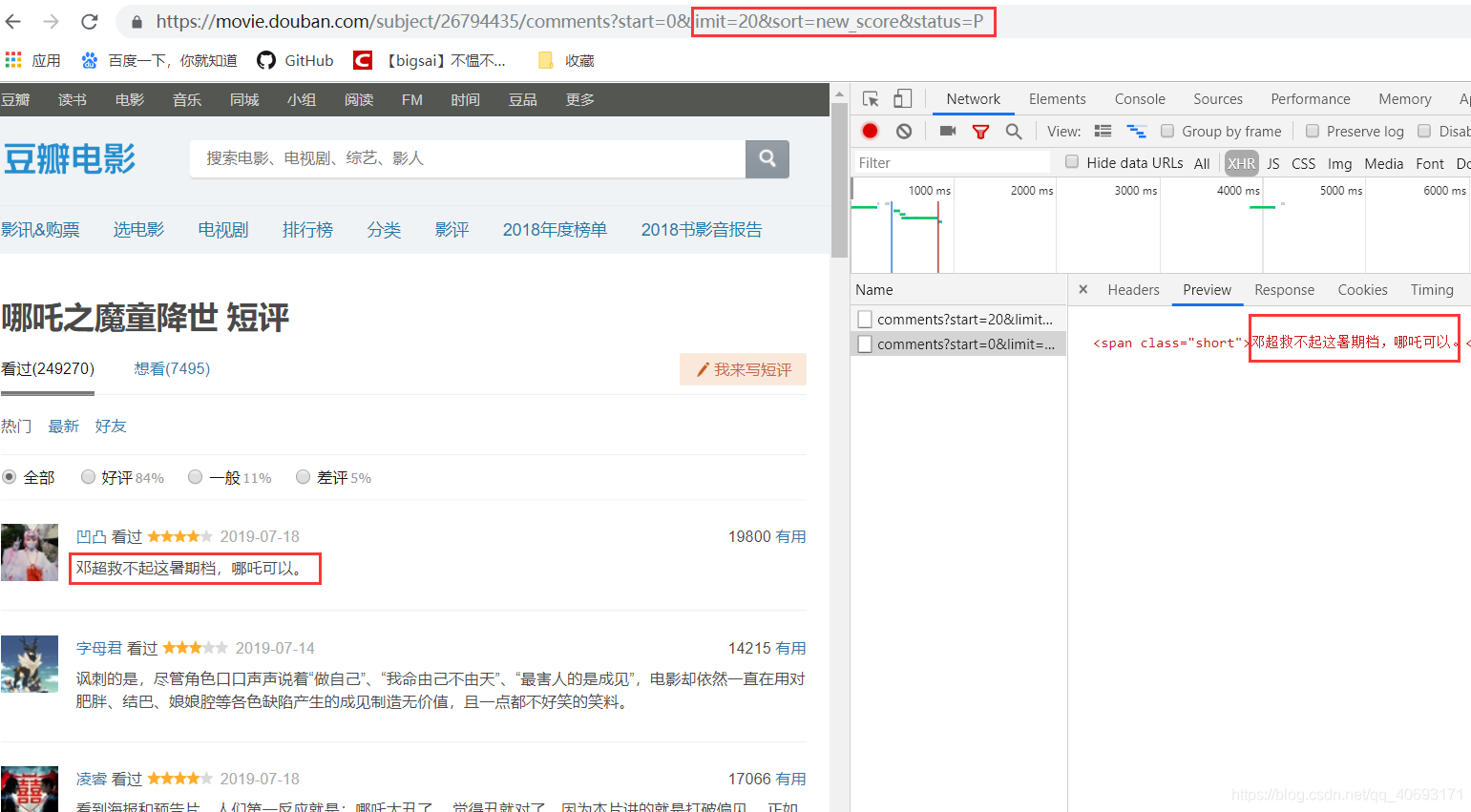
无加密。返回的是json套html需要解析处理一下。用网页访问这个接口。但是你会发现一旦你访问页面靠后它就拒绝访问了。提示你要登录再访问。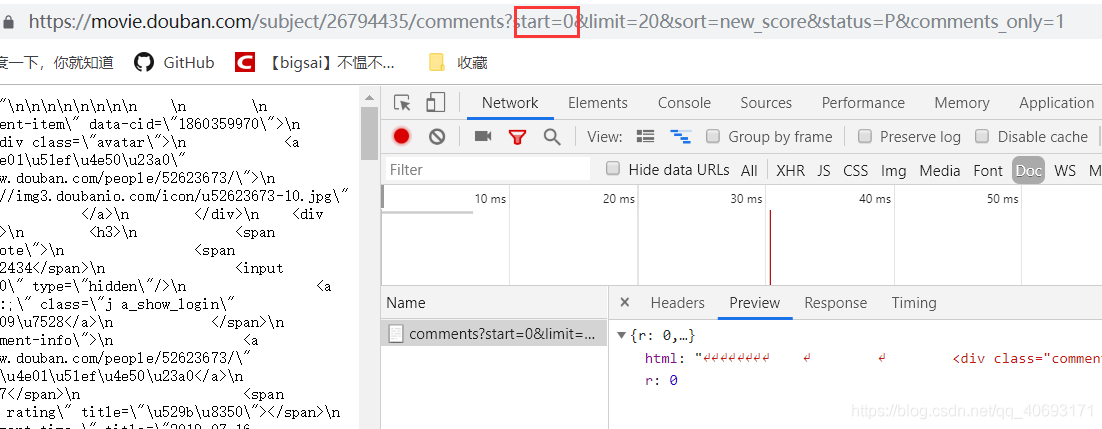
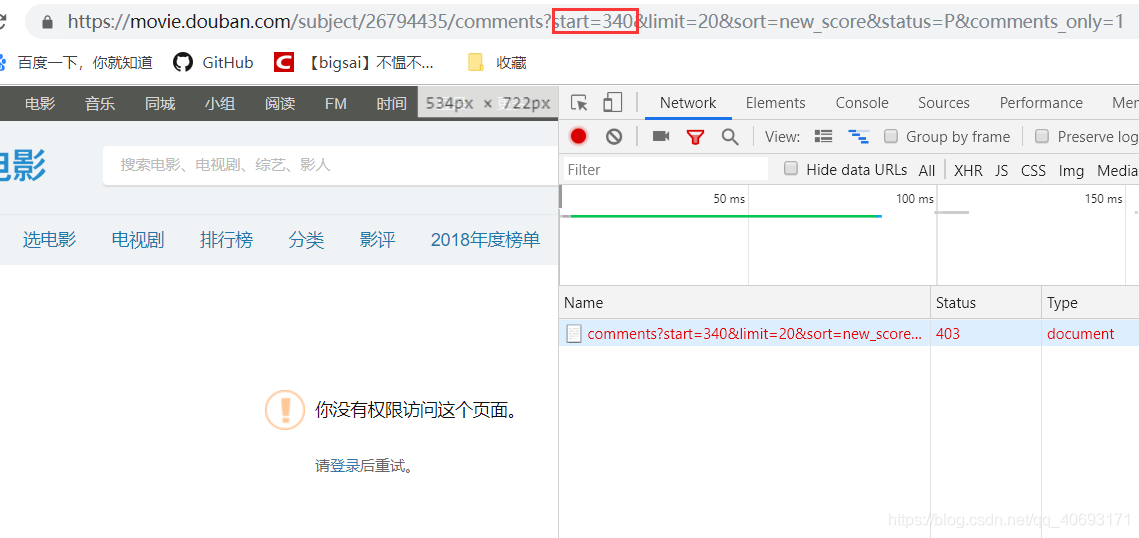
直接发送请求登录。大胆猜测没有cookie限制。登陆后即可访问接口!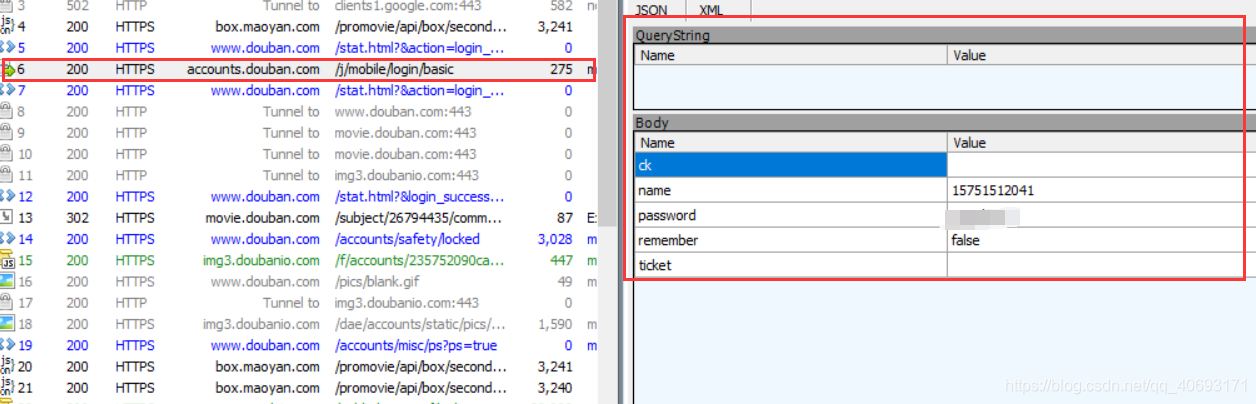
登录部分代码为:
import requests
import urllib.parse
from http import cookiejar
url=‘https://accounts.douban.com/j/mobile/login/basic‘
header={‘user-agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36‘,
‘Referer‘: ‘https://accounts.douban.com/passport/login_popup?login_source=anony‘,
‘Origin‘: ‘https://accounts.douban.com‘,
‘content-Type‘:‘application/x-www-form-urlencoded‘,
‘x-requested-with‘:‘XMLHttpRequest‘,
‘accept‘:‘application/json‘,
‘accept-encoding‘:‘gzip, deflate, br‘,
‘accept-language‘:‘zh-CN,zh;q=0.9‘,
‘connection‘: ‘keep-alive‘
,‘Host‘: ‘accounts.douban.com‘
}
data={
‘ck‘:‘‘,
‘name‘:‘‘,
‘password‘:‘‘,
‘remember‘:‘false‘,
‘ticket‘:‘‘
}
##登录函数。post请求api。返回cookie。后面携带这个cookie访问接口
def login(username,password):
global data
data[‘name‘]=username
data[‘password‘]=password
data=urllib.parse.urlencode(data)
print(data)
req=requests.post(url,headers=header,data=data,verify=False)
cookies = requests.utils.dict_from_cookiejar(req.cookies)
print(cookies)
return cookies
评价星,和评论语句。xldr、xldw将数据写入excel文件中。一个页面20条。页面url增加直到出现异常为止停止。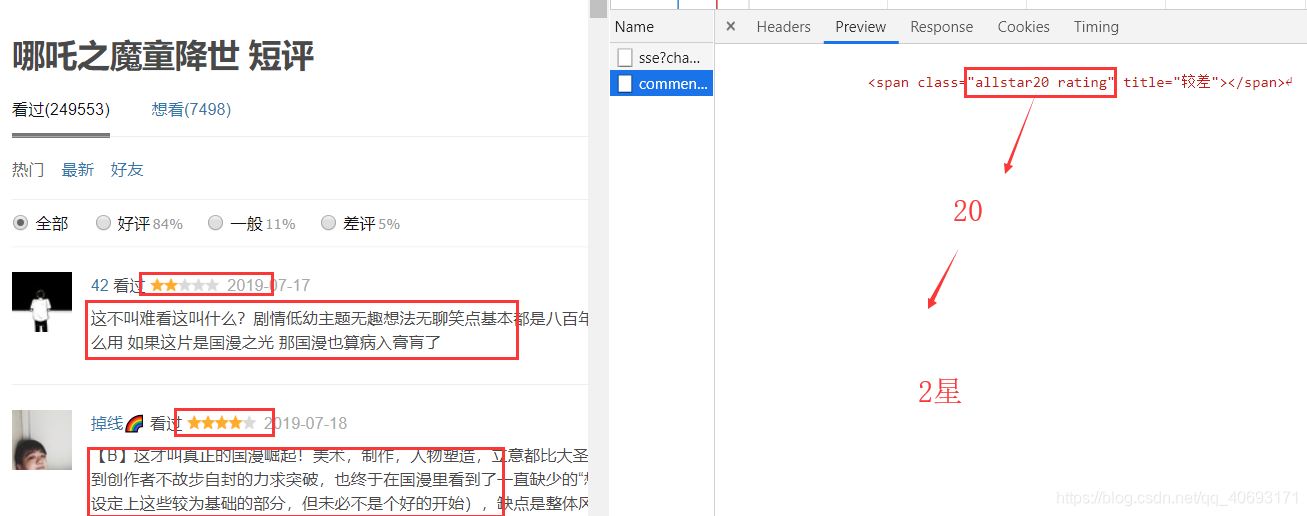
def getcomment(cookies):
start=0
w = xlwt.Workbook(encoding=‘ascii‘)
ws = w.add_sheet(‘sheet1‘)
index=1
while True:##存入ws.write(hang,lie,value)
try:
url = ‘https://movie.douban.com/subject/26794435/comments?start=‘+str(start)+‘&limit=20&sort=new_score&status=P&comments_only=1‘
start+=20
req = requests.get(url,cookies=cookies)
res = req.json()
res=res[‘html‘]
soup = BeautifulSoup(res, ‘lxml‘)
node = soup.select(‘.comment-item‘)
#print(node[0])
for va in node:
name = va.a.get(‘title‘)
star = va.select_one(‘.comment-info‘).select(‘span‘)[1].get(‘class‘)[0][-2]
comment = va.select_one(‘.short‘).text
print(name, star, comment)
ws.write(index,0,index)
ws.write(index, 1, name)
ws.write(index, 2, star)
ws.write(index, 3, comment)
index+=1
except Exception as e:
print(e)
break
w.save(‘nezha.xls‘)

matplotlib、WordCloud库。评分统计:
1,2,3,4,5,五个分数段读取时候写入,根据数据画出饼状图分析即可。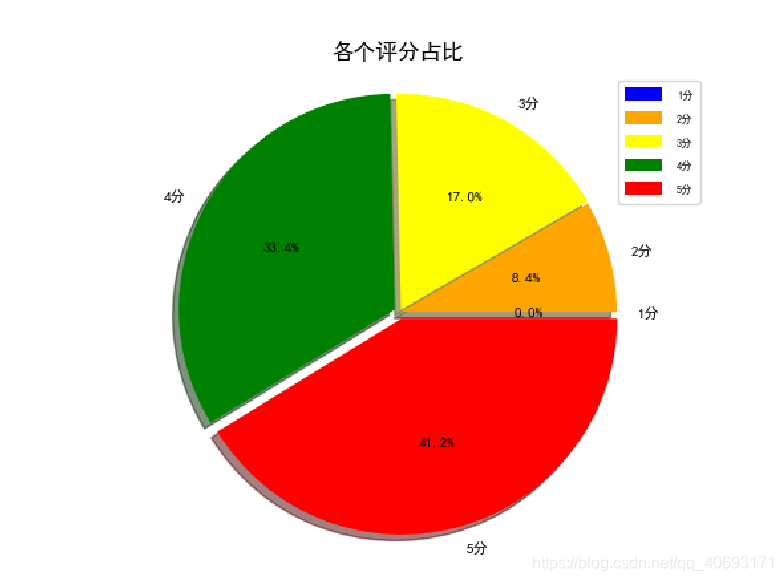
41.2%和33.4%.而2分和1分时非常少!这足以说明这部片绝对不是烂片或者争议不是很大。一部片不可能满足所有人。存在不满意的都在三分但依然能够接受。所以从评分分布来看哪吒还是广受支持的!词频统计:
共鸣点。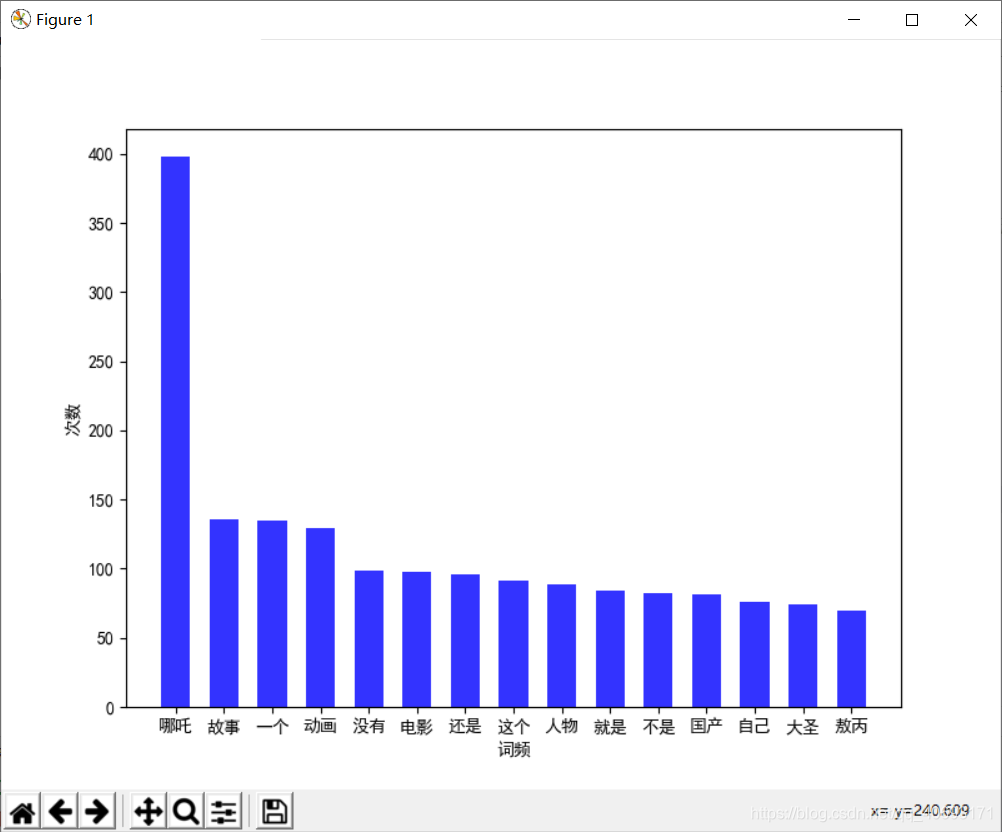
词云展示:
前300个词展示在2个词云上。这些词语的出现频率均大于10.所以还是有所参考价值额。

封神色彩、动画风格、不屈的争斗、国产的激动!在票房直逼30亿的情况下!我、要去看了。代码
import matplotlib.pyplot as plt
import matplotlib
import jieba
import xlwt
import xlrd
from wordcloud import WordCloud
import numpy as np
from collections import Counter
matplotlib.rcParams[‘font.sans-serif‘] = [‘SimHei‘]
matplotlib.rcParams[‘axes.unicode_minus‘] = False
##获取分数的饼图。用数组获取1-5分出现的次数
def anylasescore(comment):
score=[0,0,0,0,0,0]
count=0
for va in comment:
try:
score[int(va[2])]+=1
count+=1
except Exception as e:
continue
print(score)
label=‘1分‘,‘2分‘,‘3分‘,‘4分‘,‘5分‘
color = ‘blue‘, ‘orange‘, ‘yellow‘, ‘green‘, ‘red‘ # 各类别颜色
size=[0,0,0,0,0]
explode=[0,0,0,0,0]
for i in range(1,5):
size[i]=score[i]*100/count
explode[i]=score[i]/count/10
pie = plt.pie(size, colors=color, explode=explode, labels=label, shadow=True, autopct=‘%1.1f%%‘)
for font in pie[1]:
font.set_size(8)
for digit in pie[2]:
digit.set_size(8)
plt.axis(‘equal‘)
plt.title(u‘各个评分占比‘, fontsize=12)
plt.legend(loc=0, bbox_to_anchor=(0.82, 1)) # 图例
# 设置legend的字体大小
leg = plt.gca().get_legend()
ltext = leg.get_texts()
plt.setp(ltext, fontsize=6)
plt.savefig("score.png")
# 显示图
plt.show()
def getzhifang(map):##词频的直方图
x=[]##词语
y=[]##词语出现数量
for k,v in map.most_common(15):
x.append(k)
y.append(v)
Xi = np.array(x)
Yi = np.array(y)
x = np.arange(0, 15, 1)
width = 0.6
plt.rcParams[‘font.sans-serif‘] = [‘SimHei‘] # 用来正常显示中文标签
plt.figure(figsize=(8, 6)) ##指定图像比例: 8:6
plt.bar(Xi, Yi, width, color=‘blue‘, label=‘热门词频统计‘, alpha=0.8,)
plt.xlabel("词频")##标签
plt.ylabel("次数")
plt.show()
return
def getciyun_most(map):##获取词云
x = []
y = []
for k, v in map.most_common(300):##300个词云分2个词云
x.append(k)
y.append(v)
xi=x[0:150]
xi=‘ ‘.join(xi)
print(xi)
backgroud_Image = plt.imread(‘nezha.jpg‘) # 如果需要个性化词云,哪吒背景图
wc = WordCloud(background_color="white",
width=1500, height=1200,
#min_font_size=40,
mask=backgroud_Image,
font_path="simhei.ttf",
max_font_size=150, # 设置字体最大值
random_state=50, # 设置有多少种随机生成状态,即有多少种配色方案
) # 字体这里有个坑,一定要设这个参数。否则会显示一堆小方框wc.font_path="simhei.ttf" # 黑体
# wc.font_path="simhei.ttf"
my_wordcloud = wc.generate(xi)
plt.imshow(my_wordcloud)
my_wordcloud.to_file("img.jpg")
xi=‘ ‘.join(x[150:300])
my_wordcloud = wc.generate(xi)
my_wordcloud.to_file("img2.jpg")
plt.axis("off")
def anylaseword(comment):## 分词,去掉符号、换行等垃圾数据
commnetstr=‘‘
c = Counter()
low=Counter()
index=0
for va in comment:
seg_list = jieba.cut(va[3],cut_all=False)
index+=1
for x in seg_list:
if len(x) > 1 and x != ‘\r\n‘:
try:
c[x]+=1
except:
continue
commnetstr+=va[3]
for (k, v) in c.most_common():
if v<5:
c.pop(k)
continue
#print(k,v)
print(len(c),c)
getzhifang(c)
getciyun_most(c)
#print(commnetstr)
def anylase():
data = xlrd.open_workbook(‘nezha.xls‘) # 打开xls文件
table = data.sheets()[0] # 打开第i张表
comment = []
for i in range(1, 500):
comment.append(table.row_values(i))
# print(comment)
anylasescore(comment)
anylaseword(comment)
if __name__ == ‘__main__‘:
anylase()
依然有不够完善地方,如影评,对不同评分的平均不同处理、其他不同角度如评论用户性别、地点等等等等,这里不做延申。后端、爬虫、数据结构算法等感性趣欢迎关注我的个人公众号交流(关注一波十年少):bigsai 持续输出分享!
标签:tick tst generate int login ESS ping 更改 inf
原文地址:https://www.cnblogs.com/bigsai/p/11320428.html