标签:限速 访问 rest docke 并且 拆分 地方 sla 下载文件
2019 年 7 月 6 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·上海站,又拍云平台开发部负责人叶靖在活动上做了《OpenResty 在又拍云存储中的应用》的分享。OpenResty x Open Talk 全国巡回沙龙是由 OpenResty 社区、又拍云发起,邀请业内资深的 OpenResty 技术专家,分享 OpenResty 实战经验,增进 OpenResty 使用者的交流与学习,推动 OpenResty 开源项目的发展。活动将陆续在深圳、北京、武汉、上海、成都、广州、杭州等城市巡回举办。

叶靖,又拍云平台开发部负责人,目前主要负责又拍云弹性云处理平台以及内部私有云的设计和开发工作,兼部分文件上传接口相关的工作。对 Python/Lua/Go 等语言有较深入的研究,在 ngx_lua 和 OpenResty 模块开发方面有丰富经验,专注于高并发、高可用服务架构设计,对 Docker 容器有较多的实践。平时热衷于参与开源社区分享开源经验。
以下是分享全文:
大家好,我是又拍云叶靖,今天与大家分享 OpenResty 在又拍云存储系统中的应用,一方面介绍 OpenResty 的应用,另一方面会介绍又拍云存储系统的原理,又拍云使用 OpenResty 来实现云存储的网关层和 API 接入层。
分布式存储,尤其是公有云存储系统都离不开三个要求:
存储数据的拆分,第一步要做分区,这在分布式系统里是非常重要的概念,也是最常用的做法。在一个大型数据库中,通常会把整个数据库分成一个个小的子集,最常用的做法就是按 key 分区。对于一个云存储系统,key 就是 url 后面的 path,又拍云就是根据 url 后面的 path ,按 A 到 Z 来排列,把数据进行分区。这样分区可以方便地做前缀扫描,因为我们经常会做目录,列目录无非就是相同的 path 前缀的一些文件,如果 key 是有序排列,这个操作就会非常方便。
第二步操作是需要对 key 进行 hash,来把访问打散,下文会详细介绍。
上面的这些工作在又拍云都是用 Lua 代码来写的,由 OpenResty 完成数据拆分。
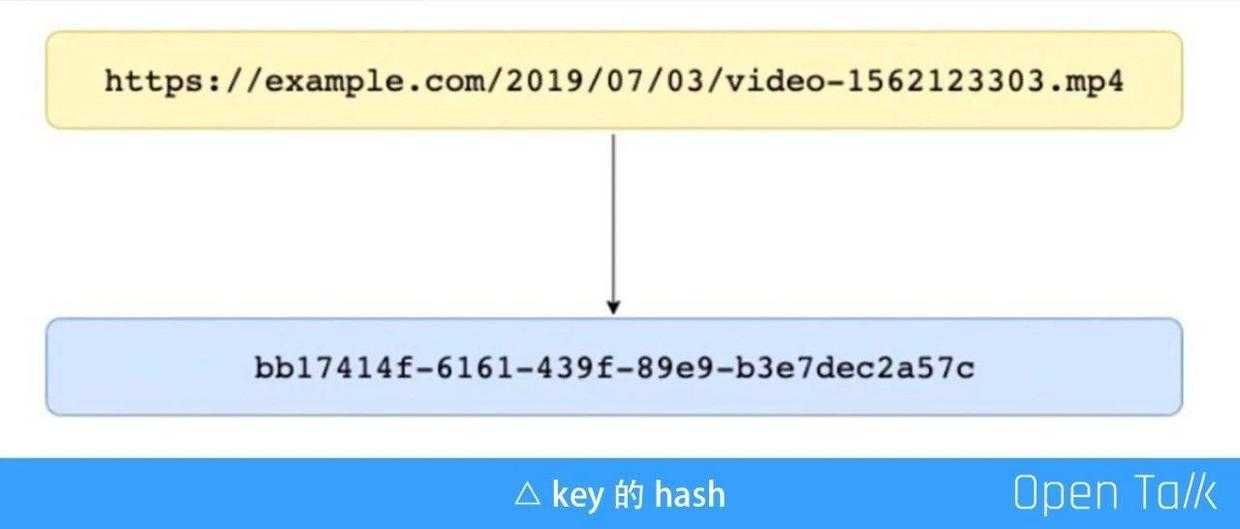
上图是的 key 的 hash,云存储文件原始的请求是一个 url,但是如果写到存储时也用这个 url 作为它的 key 会造成热点非常严重。又拍云有超过 50 万的付费客户,经过我们观察,其中有很多客户,尤其是大客户,他们文件的 key 都是带日期的,因此文件的 key 的前缀可能都是某一个日期,而最近上传的文件肯定是最热的,这就会导致今天上传的文件全部放在同一台机器上,会使这台机器的带宽被撑满。因此我们把文件的 url 变成一个 hash,这个 hash 并不是 key 的 MD5,也不是某种算法算出来的 hash,其实就是内部生成的一个 UUID 对应这个文件,然后把对应关系记录下来。
索引在存储系统里是文件的元数据信息,元数据信息是指这条记录原始的 key、内部的 key、文件大小、存在于哪些集群内等类似的信息。
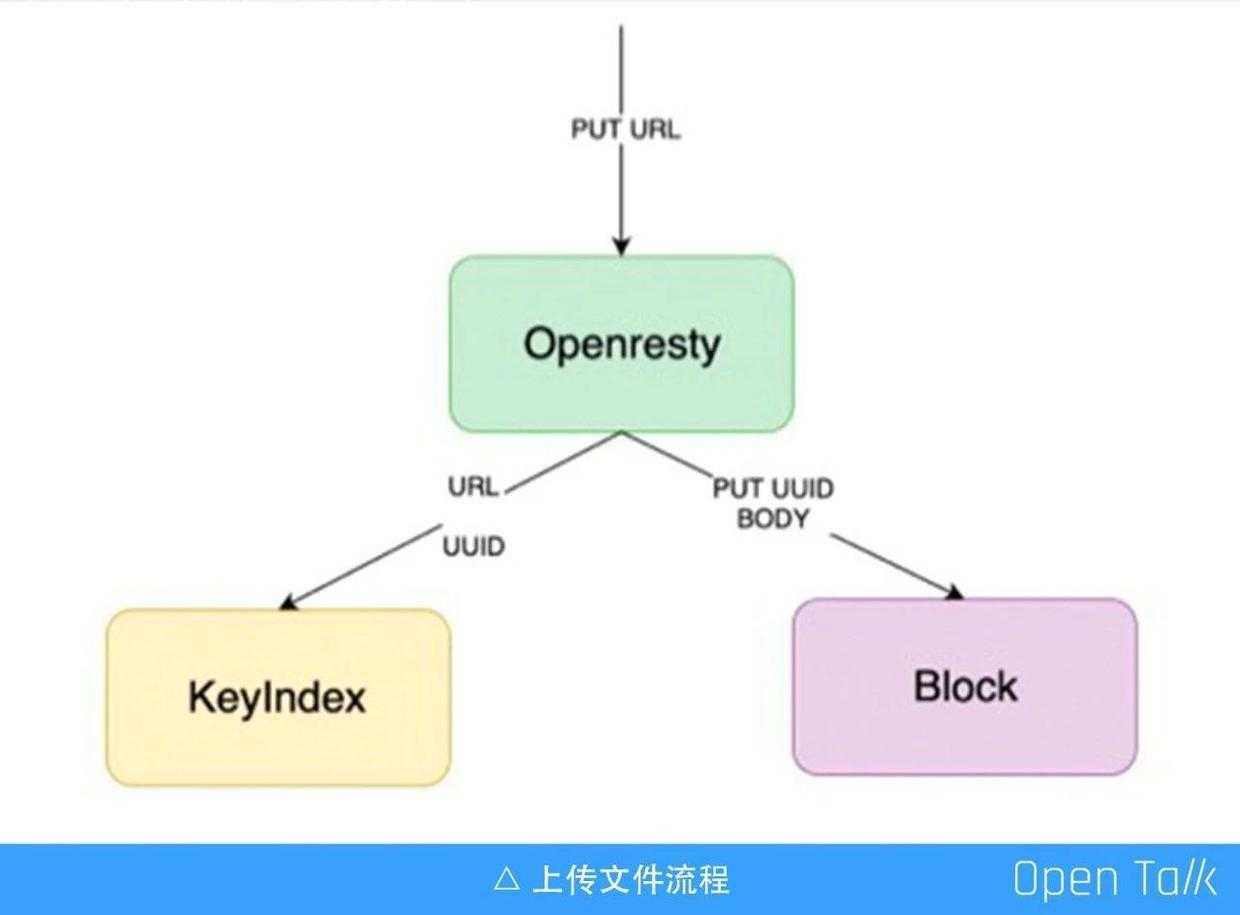
上图的流程是外部存储访问的上传文件流程。首先是发一个 put 请求,put 请求的 url 就是文件的 key。接着到 OpenResty 层,这层是基于 OpenResty 做的存储网关,存储网关会把 url 生成一个内部的 UUID 并做对应。生成之后会带着 UUID 做上传,接收数据,这里我们是用 Lua 来做,ngx_lua 里面有一个 req.socket,它会拿到 socket 然后读取上传的数据,数据读到之后存到一个叫 Block 集群内,Block 集群是真正存放文件二进制的地方。整个过程是流式的,边读边写,所以不会带来一些大文件的问题,当文件数据存完之后,再把 UUID、一些元数据信息写到 KeyIndex (元数据集群)。
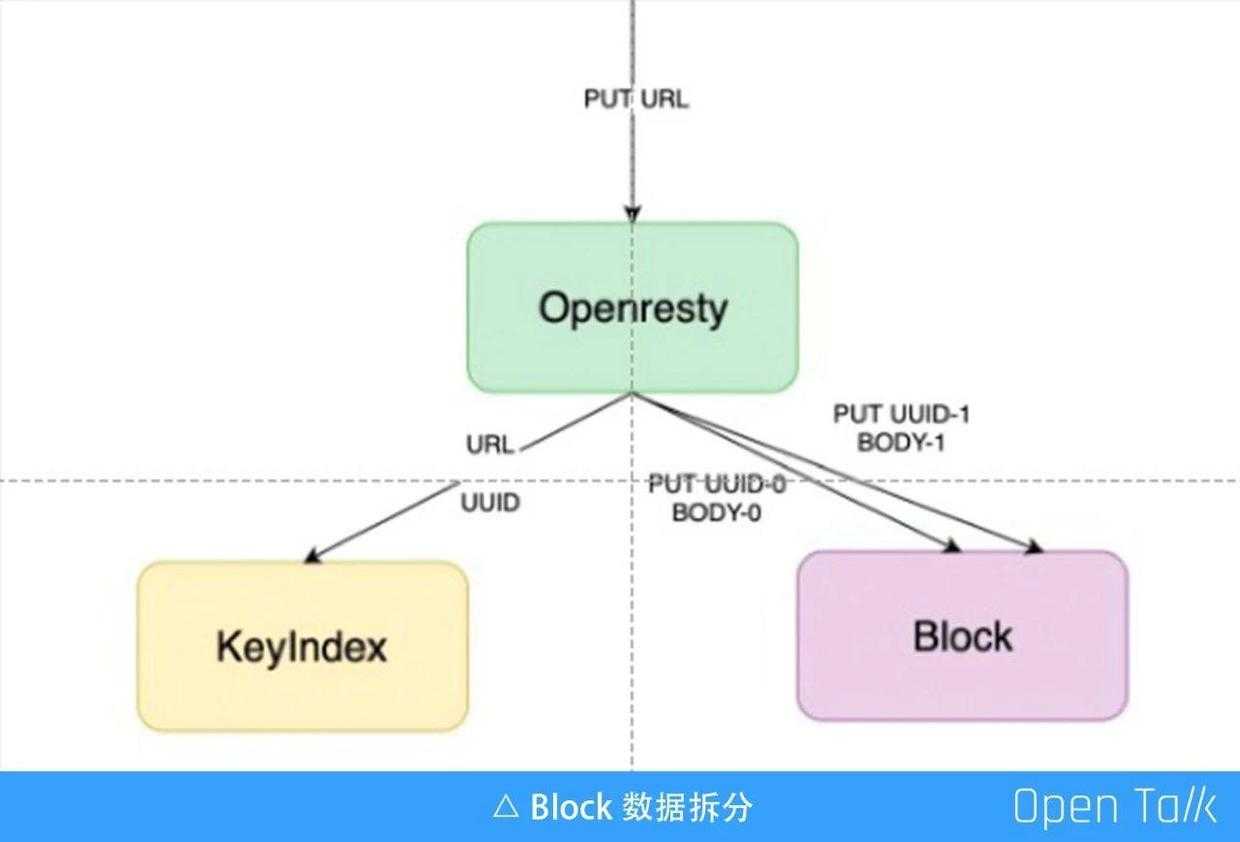
第二步要对 Block 数据进行拆分,前面提到的只是一个简单的过程,其实在接收上传数据并写到 Block 集群的过程中,并不是把所有数据都写到同一个 Block 集群中,而是会做拆分。又拍云支持最大 40T 的文件上传,现在用的磁盘最大也就单个 8T,单文件 40T 是如何支持呢?做法其实是把 Block 做一个拆分,假如把这个数据拆分成 10M、10M 的块,可以把他上传到不同的机器和磁盘,只要记录下它的对应关系就可以了。
实际上在 OpenResty 网关里,接收数据的原理也是如此,先收一个 Block 大小,比如 10 M,然后 10M 变成一个 UUID-0 写到 Block 里,再收第二个 10 M,变成 UUID-1,写到 Block 集群,一直到接收完毕,这样一个 G 的文件可能就产生了 100 多个 “UUID-数字”的分块文件,他们分别被存到不同的机器、磁盘里,这样就能支持超大的文件存储了。
接收数据并写入数据的过程其实是有策略的。不同于一般的 OpenResty 用法,比如在做一些鉴权操作、限速操作,只要是在 access 阶段或者 rewrite 阶段去做一些控制,后面就交给 Nginx proxy_pass 做代理,把数据代理出来就可以了;而在这里是完全没有走 Nginx proxy_pass,直接用 Lua 代码去控制数据的读和写,然后返回,整个的过程都是 Lua 代码去控制。
总的来说,上面的内容讲了拆分,一共分为三步:
第二部分内容,介绍存储里面的路由。
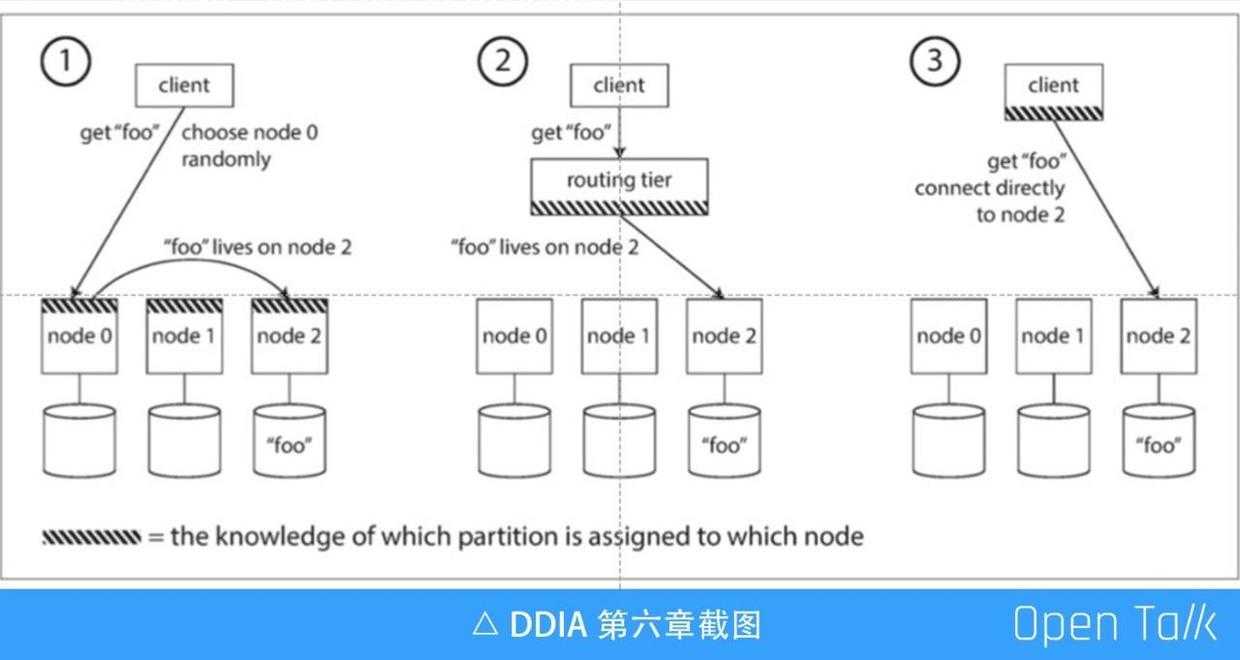
通常提到路由会想到一种模式就是代理,代理的角色是上图中间的第②种,它中间做了一层代理,所有下面的 MySQL 或 Redis 都只是做单节点的存储,其中前面的代理知道下面所有的节点的存储的分布的路由情况,所有的请求都是经过代理的。
左边第①种模式所有的节点都是对等的,所有节点都知道数据存在哪个节点上,Redis 在访问的时候就可以随便找一个节点访问,如果数据刚好在这个节点上就直接返回,如果不在这个节点上,此节点会代理到其他的节点上去。
第③种是 Java 生态系统经常使用的,像 Hbase 就是是使用第③种方式,路由信息存在 client 中,client 直接找到那个节点,省去了好多中间的过程。但是有一个问题是 client 会非常复杂,在存储系统里面,第③种肯定是不行的,因为 client 即客户的 rest api ,它只有一个 HTTP,不可能带路由信息。
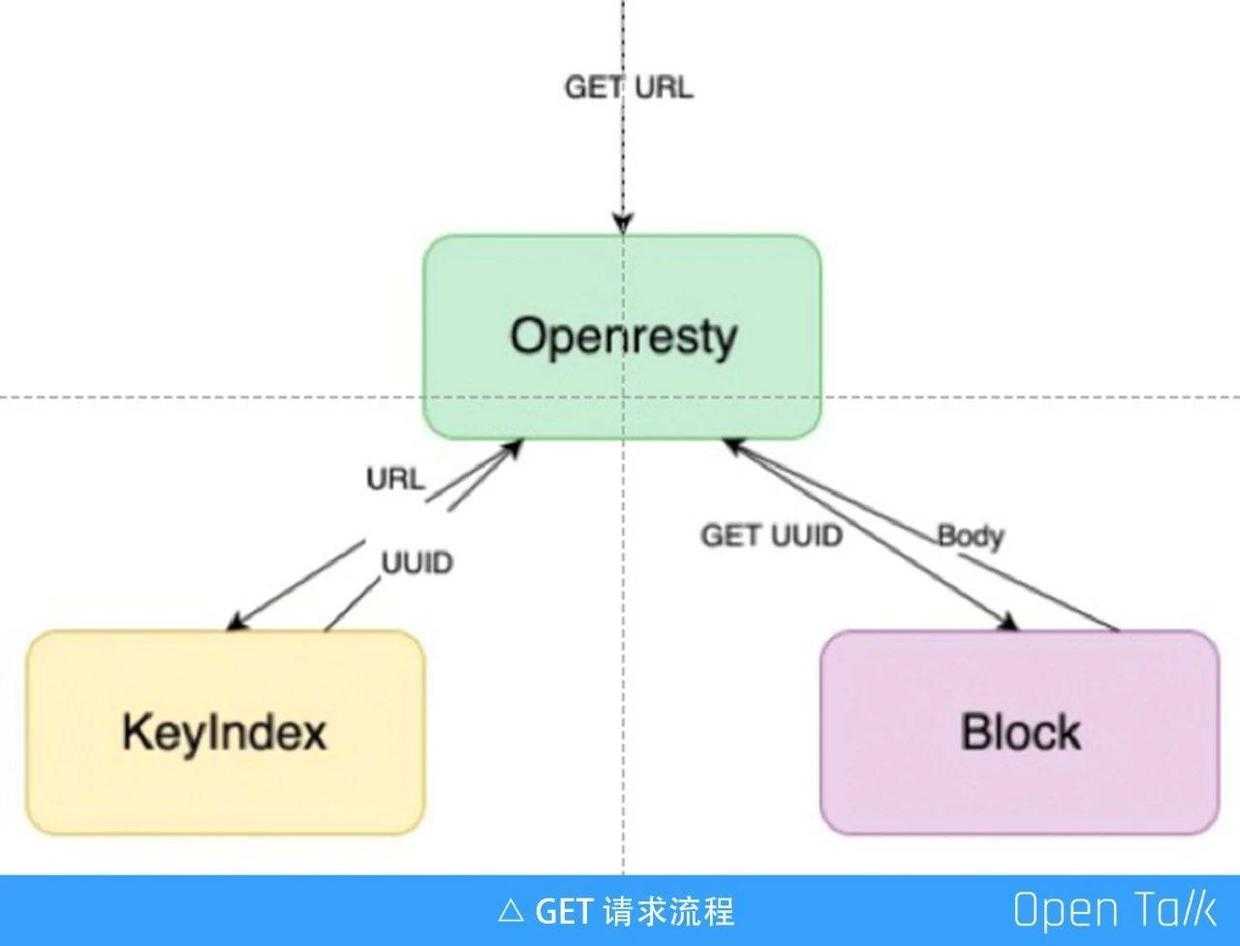
又拍云选择的是第②种模式,第②种模式中 routing tier 就是 OpenResty 存储网关,它里面有路由信息,知道这个 url 应该去哪个集群。上图是一个下载文件的 get 请求流程,一个 url 进来后,网关会先去 Meta 集群,即左边的 KeyIndex,拿 url 去找到内部对应的 UUID,然后拿内部的“ UUID-数字”,去 Block 集群里把的分块读出来,然后一块一块流式地吐回去,这就是 get 的过程。
Meta 集群路由都是固定路由,分为几个层次:
又拍云内部通过网关列目录,简单来说就是 key 的前缀匹配,我们建了单独的目录系统来实现目录功能。
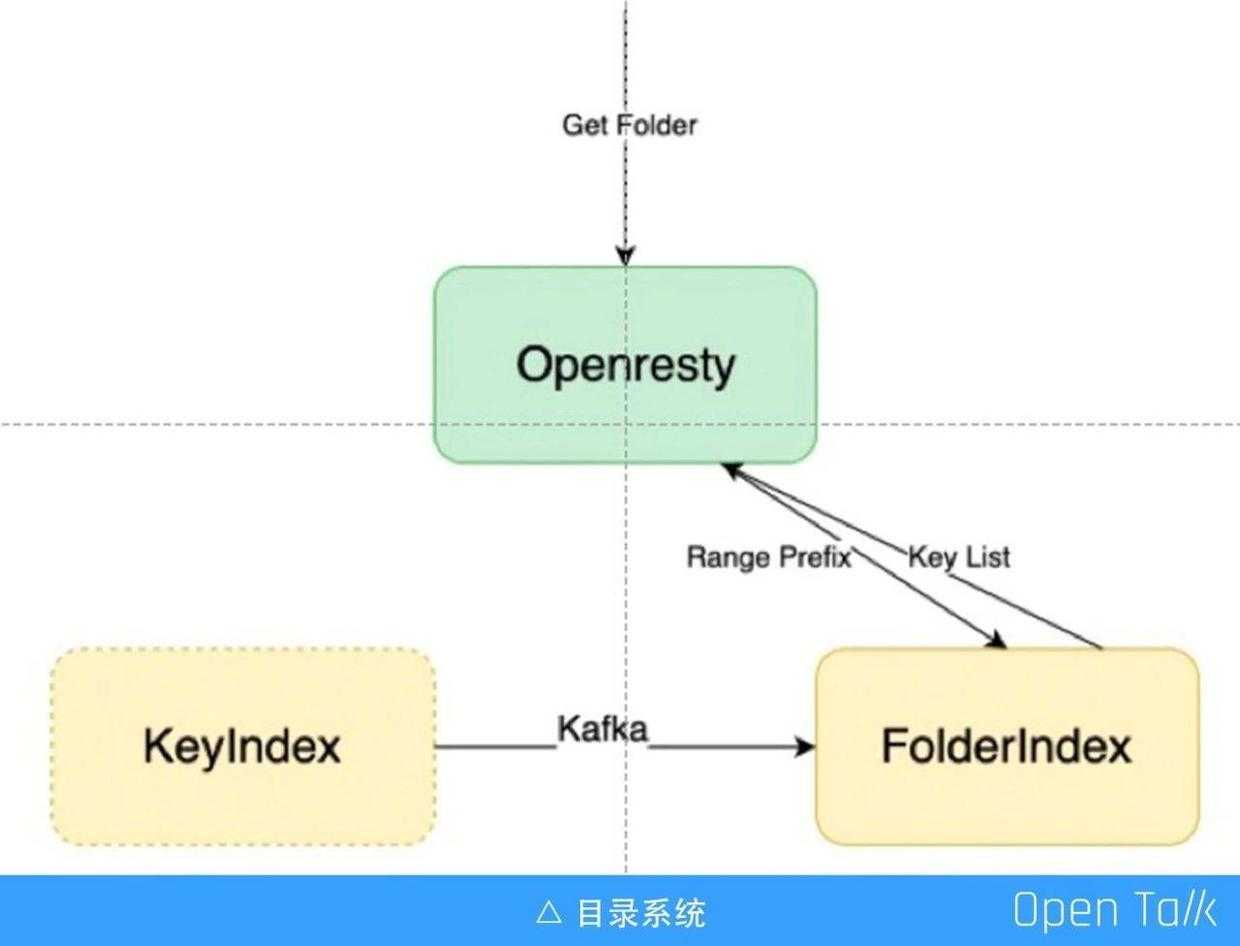
上图中左边的 KeyIndex (Meta 集群),里面的数据会实时同步,把一些需要的信息同步到目录索引中,比如列目录只需要文件的 key 的名称、大小、类型、修改时间等,它会把这些信息抽取出来输入到目录系统里面,如果前面的网关收到的是一个列目录的请求,就会直接去目录系统里面,根据前缀匹配把数据列出来。
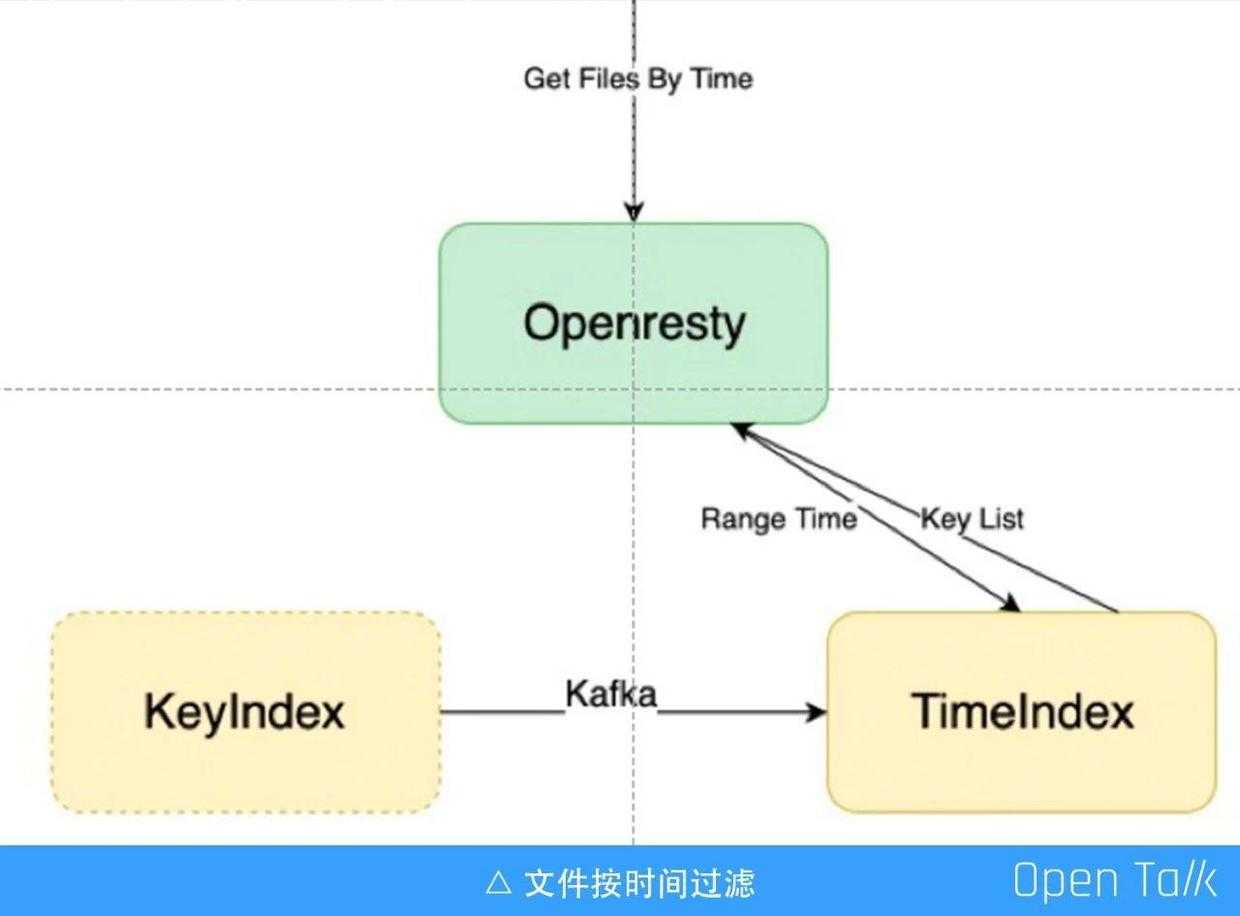
我们经常会碰到一个需求,要按照文件的上传时间来列最近上传的文件,或者某天上传的文件,亦或是一年前的上传文件。此时需要单独再建一套按时间排列的索引,不同于本地的文件系统,本地的文件系统少,要怎么列就怎么列,而云存储文件数量都是千亿以上级别的,如果不事先做好索引,等请求到了再去列,是不可能完成的。
Block 集群的路由和 Meta 集群一样,也是按照存储类型和用户空间划分。此外,不同的 Block 集群可以有不同的 Weight ,来控制它不同的写入量,如果一个新加的 Block 集群需要多写一点数据,就可以把它的 Weight 调高。
又拍云很早之前就开源了一个模块 lua-resty-checkups(https://github.com/upyun/lua-resty-checkups),路由在 OpenResty 里面就是通过这个模块来实现,这个模块在又拍云几乎所有的 ngx_lua 的机器上都有,已经用了好几年了,非常稳定。这个模块主要的工作是管理 upsteam 地址,去做主动的健康检查、被动的健康检查、动态更新 upsteam 地址以及路由的策略等,前面提到的所有的路由功能都是通过这个模块来实现。
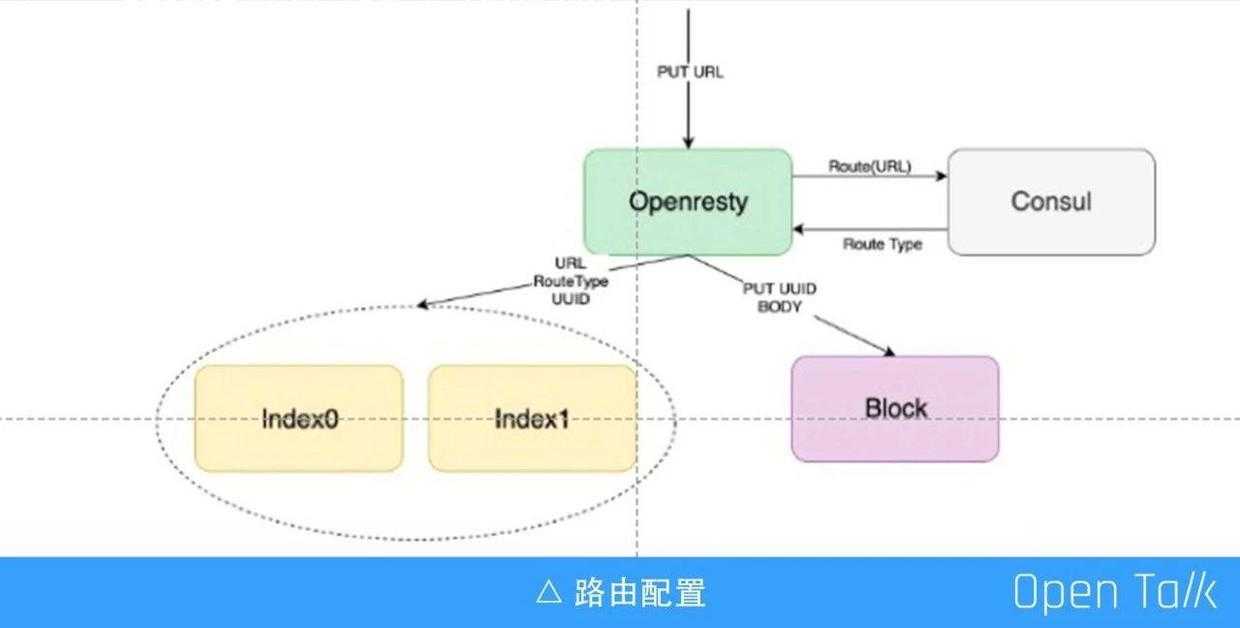
又拍云把路由的配置放在 consul 里面,OpenResty 网关会定时去 consul 里面拿最新的配置,然后缓存到自己的进程里面,目前我们是一分钟拿一次路由配置,缓存到进程里,每个进程都按照这份配置来工作。关于配置功能,又拍云还开源了一个项目 slardar (https://github.com/upyun/slardar),这里的配置原理和 slardar 原理一模一样,而且很多模块是直接拿过来的。
前面介绍了上传、下载和列目录,我们经常使用的还有 Head 操作,Head 操作是检查文件存不存在,它和文件真实的数据没有关系,Head 过来后网关就会拿这个 url 去检查,看是否有这个文件,如果存在就 200 ,不存在就 404 。
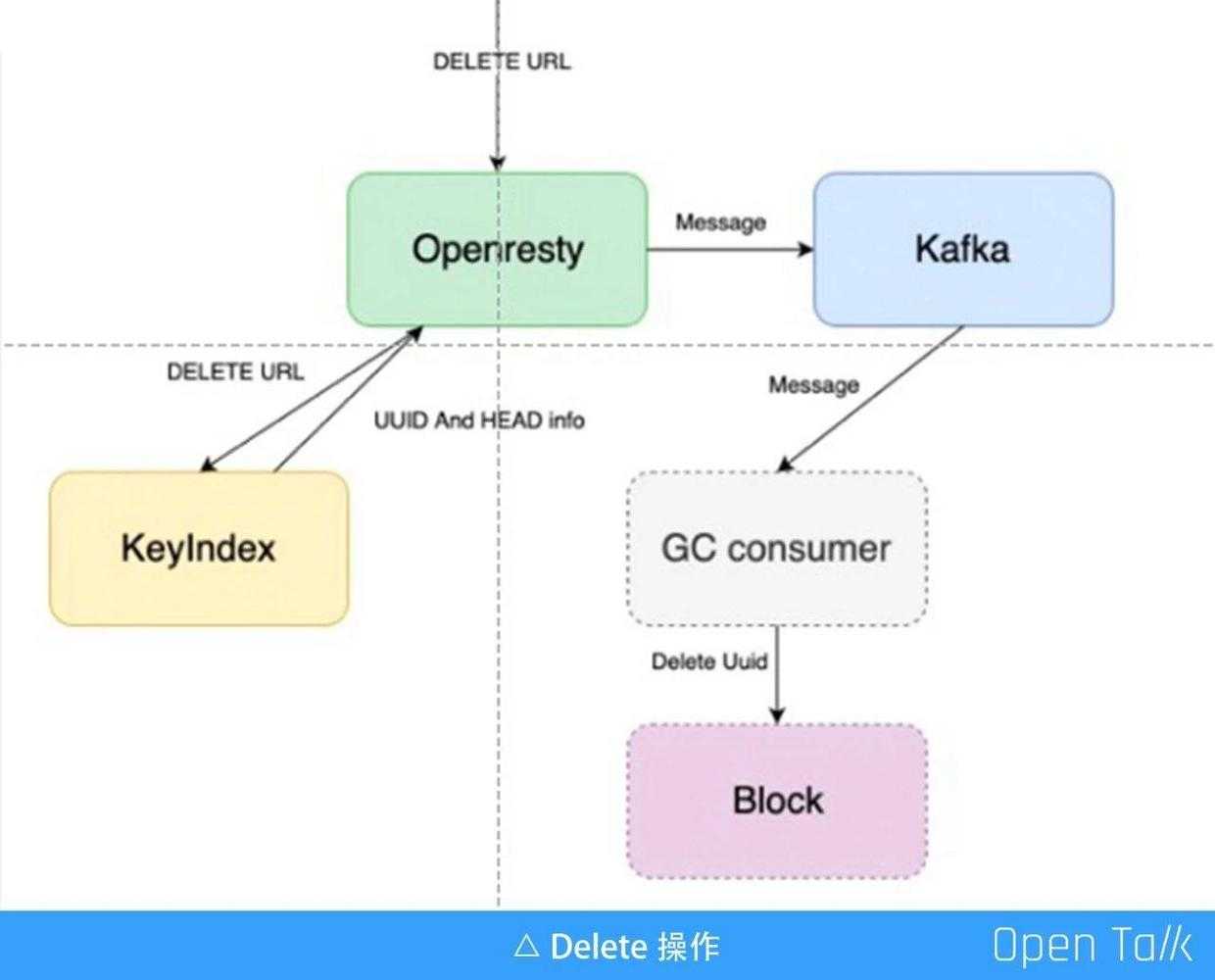
Delete 操作是不需要 Block 数据的参与的,因为在一个存储系统里面,Delete 并没有从磁盘上把数据真正地删除掉,这里的删除只是在元数据库 KeyIndex 里面做一个标记,把这个文件标记为删除。而数据的清理其实是通过一个异步的 worker 来收集已经被标记删除的文件,然后去 GC 把它们真正地删除掉,并且 GC 会有延迟,并不是标记删除就马上就去 GC,因为有可能会遇到一些误操作的情况,为了避免这种情况,我们通常会把 GC 延迟 7 天甚至 1 个月。整个过程,网关会通过 Lua 中的 kafka 模块,发消息到 kafka 队列,表明这是一次删除操作,kafka 这条消息就会被 GC 的消费者消费,当它拿到这条日志就会定时,时间到了就会去 Block 数据里面把这个文件真正删除。
存储系统里除了刚才说的操作之外,还有很多其他的操作:
Random 功能目前我们还没有实现,但是随机读的功能是可以的。除了 Random 功能,其他的都是可以通过 Lua 代码来实现的,这些是用 OpenResty 来写业务逻辑的很好的一个例子。
接下来介绍存储的扩容,这部分内容和 OpenResty 关系不大,但是是存储一定要讲的一个问题。扩容涉及两个方面,一个是 Meta 集群的扩容,另一个是 Block 集群的扩容。
Meta 集群存的是文件的元数据信息,value 其实非常小,可能就只有几百个字节,再大也大不过 1K,它的扩容是相对容易的,比如加一台机器,它的总量也小,balance 速度非常快。
事实上,我们一般不会做 Mata 集群的扩容,印象中又拍云这么多年只做过一次,因为 Meta 集群的容量可以算出来的,比如要支持一千亿条文件的存储,可以计算出大概需要的 Meta 集群的容量,几百个 T 肯定够了,因此你买一批设备放在那,就不用考虑扩容的事情了。总的来说,Meta 集群的扩容是比较简单的。
相对来说比较麻烦的是 Block 集群的扩容。Block 的文件可大可小,它的容量非常大,几十个P,甚至几百个 P。如果你的一个集群有好几个 P,当你加一台机器要重新 balance ,所有的其他的机器要挪出一部分的数据来写到当前你新加的这台机器上,这是一件非常恐怖的事情,可能会需要几天甚至一星期,整个集群都处于一种数据倒来倒去的状态,这是肯定会影响业务的。
我们要尽量避免这种 balance 的操作,于是想了一种比较取巧的办法,尽量不做集群内部的 balance,当需要扩容时,就直接新增一个集群。当然有时候也是需要做 balance,如果一定要加就让它慢慢扩,扩几天或者一星期。但是我们一般的做法是估算出下一个集群需要多少机器、多少容量,直接整个集群上去,在网关层把整个集群配进去,然后调高 Weight 值,让大量的数据都写到新的集群中,这样去做整个云存储的扩容。
不论是 Meta 集群还是 Block 集群,都需要有复制的能力,因为我们都是使用多副本存储,或者 EC 存储。Meta 集群可以选用 Hbase,Postgresql/Mysql,Hbase 有 HDFS 能自带复制功能,而如果是 Postgresql/Mysql,需要配置它的主从或者给它做一些同步、复制的功能。
此外,Meta 数据的备份也很重要,因为 Meta 集群关系到所有的数据是否能够访问,一旦出现问题就会非常严重,所以这里就需要在网关层把 Meta 数据写到 kafka,另外一种办法是直接在数据库弄个插件,再导到 kafka。
Block 集群的复制比较复杂,通常是集群内部要完成的事情,和网关层没有太大的关系。
事务也是存储非常重要的概念,在云存储系统中,没有办法做到像单机数据库那样的事务,它只能做到单个对象级别的事务,保证这个对象是处在事务里面的。整个操作是需要一个 Meta 集群支持一个 CAS(compare-and-set)操作。一个对象不能被两个线程同时写入,这样会造成其中一个线程失败,会以后面写入的 Meta 信息为准。
前面提到一个 Key 只能一次被写入,这里会涉及到限速,我们使用的是 openresty/lua-resty-limit-traffic,又拍云在此基础上增加了 token bucket 的方法,token bucket 这个模块目前也是开源放在我们的 github 上,我们内部都是用这个模块,测试下来这个模块是最平滑的,能很好应对突发的请求。
前面介绍的都是存储的网关层、以及存储下面的功能,其实做一个云存储系统,不单单是做一个网关或存储,后面还有许多配套的东西,比如 API,API 又拍云也是通过 Lua 来写的,这里也有很多的业务逻辑,比如表单 API 涉及到表单的解析、参数的解析、上传到存储网关等。此外,还有认证的算法、断点续传也都是通过 Lua 来写的。断点续传,是指一个大文件如十几个 G 的文件,可以把它切成 1M、1M 的文件块分别传到存储,存储会先把这些文件写到 Block 集群,当接收到最后一个 finish 消息,存储就会把这些临时的数据拼成一整个文件。
又拍云存储系统
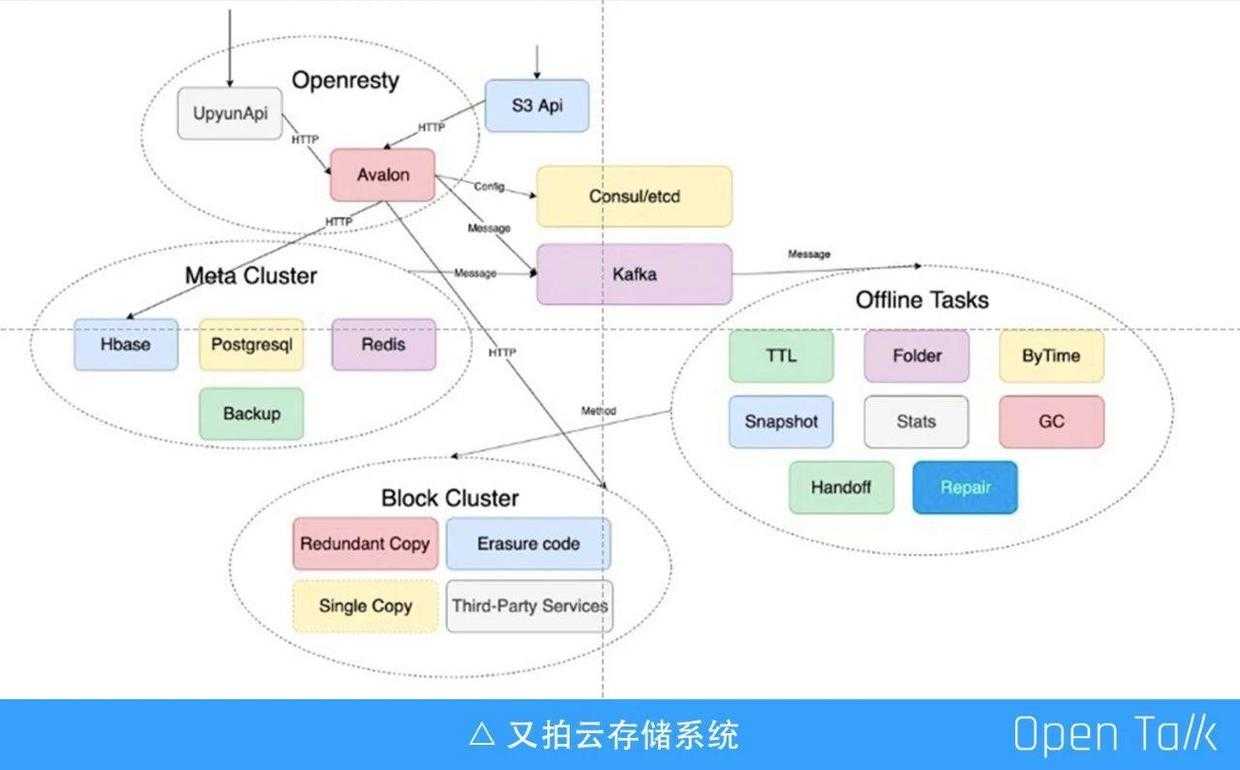
上图是又拍云存储系统模块关系图,OpenResty 在里面主要是左上角这块,UpyunApi 是又拍云的 API 层,像认证、鉴权、上传的表单 API 等都是它做的事情;Avalon 是 OpenResty 的云存储网关,内部与存储相关的流量都会经过这里,包括 CDN 的 get 流量也会经过这里;左边的是 Meta 集群,它有很多组件,包括 Hbase、Postgresql、Redis 以及备份的工作;右边的是一些消费者,因为存储系统需要很多的消费者来完成一些特定的工作,比如自动过期、TTL、GC、坏盘的修复等;最下面的部分是 Block 集群,是真正存数据的地方。
下面是前面提到的一些又拍云开源出来的开源项目,这些在 upyun 的仓库里面都可以找到,又拍云内部也是大量使用这些模块,主要包括:
[1] upyun/slardar :?https://github.com/upyun/slardar
[2] upyun/lua-resty-checkups :?https://github.com/upyun/lua-resty-checkups
[3] upyun/lua-resty-limit-rate :https://github.com/upyun/lua-resty-limit-rate
标签:限速 访问 rest docke 并且 拆分 地方 sla 下载文件
原文地址:https://www.cnblogs.com/upyun/p/11320990.html