标签:经历 简单的 replace ima 选择 一致性算法 报错 nbsp ati
Redis持久化
:如果用户将数据保存到内存中,如果服务器断电或者宕机则内存数据将清空,导致缓存数据清空.
持久化文件使用规则:
当程序正常运行时会生成持久化文件.如果当服务器宕机后重启时.会根据配置文件中指定的持久化文件进行数据的恢复.
RDB模式:
说明:
说明:
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
时间T:数据自上一次到现在的时间.
说明:LFU算法是redis5以后才提出的.
LFU(least frequently used (LFU) page-replacement algorithm)。即最不经常使用页置换算法,要求在页置换时置换引用计数最小的页,因为经常使用的页应该有一个较大的引用次数。但是有些页在开始时使用次数很多,但以后就不再使用,这类页将会长时间留在内存中,因此可以将引用计数寄存器定时右移一位,形成指数衰减的平均使用次数。
使用次数越少越先被删除.
1.volatile-lru: 将设定了超时时间的数据,采用LRU算法将数据提前删除.
2.allkeys-lru -> 对所有的数据采用LRU算法进行删除
3.volatile-lfu -> 设定超时时间的数据采用LFU算法删除
4.allkeys-lfu -> 对所有数据采用LFU算法删除
5.volatile-random 设定了超时时间的数据随机删除
6.allkeys-random 所有数据随机删除
7.volatile-ttl 设定了超时时间的数据根据剩余时间少的删除数据
8.noeviction 不删除内存数据,如果内存溢出报错返回.
说明:将多台redis搭建成分片的结构.实现内存的扩容.
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
规则:
二进制: 逢2进1 0,1
八进制: 逢8进1 0-7
十六进制 逢16进制1 0-9-A(10)-F(15)
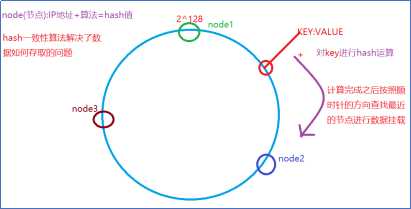
说明:因为采用hash一致性算法,可能导致数据负载不均.所以hash一致性提出虚拟节点解决负载均衡的问题.
说明:当节点新增时,其中的数据会自动的迁移.
注意事项:节点只能新增,不能减少,因为少了内存缺失,数据丢失.
说明:由于分布式的部署,某个节点不能获取全部的内存空间.一个key可能会有多个位置.
说明:由于分布式部署.某个节点不能获取全部的内存空间.一个位置可能保存了多个数据.
如果有效降低分散性和负载:尽可能的使用同一块内存区域.
标签:经历 简单的 replace ima 选择 一致性算法 报错 nbsp ati
原文地址:https://www.cnblogs.com/luojie1216/p/11325531.html