标签:次数 一个 做了 公司 存储 场景 log mysql数据库 mysq
(这是第二篇大数据架构篇,成长之路序列会包含多篇,笔者作为这个平台的架构兼技术经理,充分讲述其中的迭代心酸之路以及中间遇到的问题和解决方案)
声明:文章不涉及公司内部技术资料的外泄,涉及的图片都是重画的简易架构图,主要通过架构的演进,讲述分享技术的迭代之路和过程。
在第二轮迭代完成后,第三轮迭代中,我们就开始做平台的数据分析了,这里我们以工作台数据分析为例,讲解平台如何采用大数据的方式来进行数据分析。
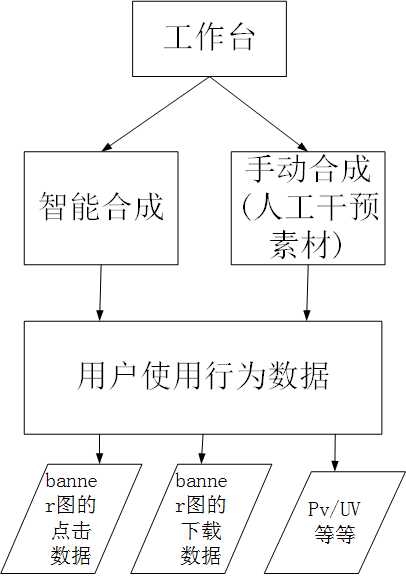
工作台中,需要做数据分析,比如平台合成出来的banner图被用户的点击次数,banner图合成出来后,被用户下载的数据,工作台中的PV/UV情况等。
在此轮设计中,我们直接用的大数据解决方案,并没有在一开始使用关系型数据来做这样的数据分析统计,架构方案如下,我们选用了Druid来做数据存储,以OLAP的方式来做数据分析,Druid.io(以下简称Druid)是面向海量数据的、用于实时查询与分析的OLAP存储系统。Druid的四大关键特性总结如下:
1)、亚秒级的OLAP查询分析,Druid采用了列式存储、倒排索引、位图索引等关键技术,能够在亚秒级别内完成海量数据的过滤、聚合以及多维分析等操作。
2)、实时流数据分析,区别于传统分析型数据库采用的批量导入数据进行分析的方式,Druid提供了实时流数据分析,采用LSM(Long structure merge)-Tree结构使Druid拥有极高的实时写入性能;同时实现了实时数据在亚秒级内的可视化。
3)、丰富的数据分析功能。针对不同用户群体,Druid提供了友好的可视化界面、类SQL查询语言以及REST 查询接口
4)、高可用性与高可拓展性。Druid采用分布式、SN(share-nothing)架构,管理类节点可配置HA,工作节点功能单一,不相互依赖,这些特性都使得Druid集群在管理、容错、灾备、扩容等方面变得十分简单。
关于druid的介绍,可以参考https://www.jianshu.com/p/0a614455a964 这篇文章。
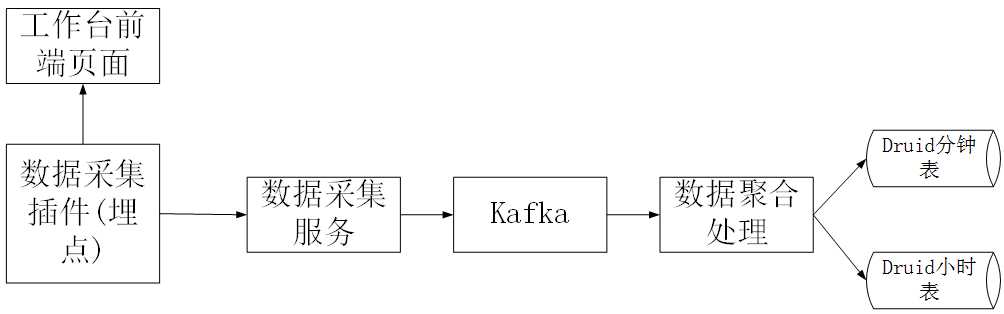
1、 在页面中,我们用采集插件做了数据埋点采集,数据采集通过数据采集服务丢入到kafka中。
2、 我们在druid中设计了两张表,数据的粒度精确到分钟时间段,也就是有分钟表和小时表两张。分钟表数据量可能会比较大,所以我们只会保留1个月内的分钟表数据,小时表的数据会长期保存。
3、 在kafka中,我们创建了两个消费组,一个用于小时消费处理,一个用于分钟消费处理。
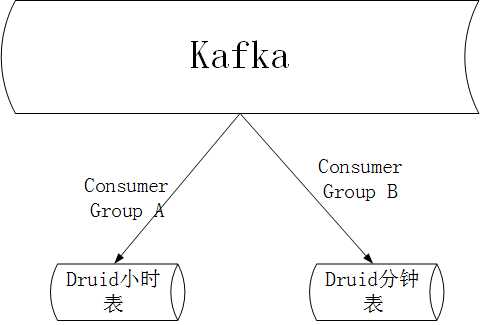
4、 在平台设计时,每张banner图都有一个唯一的bannerId和url,在数据聚合处理操作时,bannerId 就成了唯一的标志,按照bannerId进行分钟级的聚合处理和小时级的聚合处理。
5、 小时级的聚合处理也可以考虑使用hive,处理的方案如下,由于分钟表的数据会保存1个月,所以1个月内的查询其实都是直接查询分钟表,1个月以外的数据才会查询小时表。所以尽管此种方案可能会存在数据采集延迟的情况,但是也不会延迟1个月之久,所以可以通过定时任务来处理,定时任务可以在第二天处理前一天的数据。

6、 数据报表在查询时,就可以按照1个月以内查询分钟表,1个月以外的查询小时表。
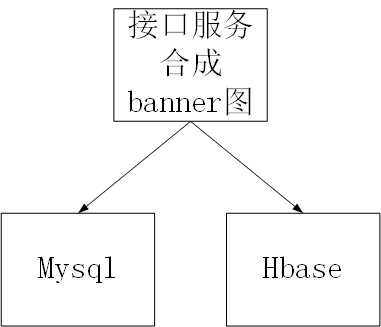
上面讲的工作台中数据分析的场景,另外我们还有接口合成banner图的数据也是需要分析。在第二轮迭代时,接口请求合成的banner图的结果数据我们同时入了hbase和mysql两张表,上文中已经说过入hbase中的数据是供用户做接口合成结果查询的。入mysql中当时是准备用作数据分析的(因为第二轮时,调用量还不够大,所以那个时候还未采用大数据方案),如下图
在第三轮的接口迭代中,我们将架构进行了优化,以适应每天千万级的接口合成调用,不然mysql数据库会成为最终的瓶颈,如下图
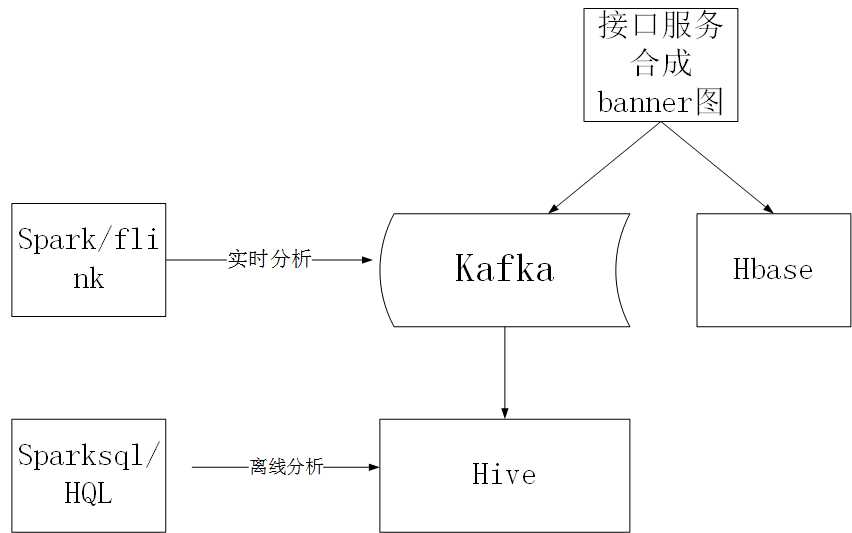
我们将入mysql的那份数据改成写到kafka中,然后kafka的数据可以做实时分析,也可以将kafka的数据进入到hive中做离线分析。
未完待续
苏宁人工智能研发中心智能创意平台架构成长之路(二)--大数据架构篇
标签:次数 一个 做了 公司 存储 场景 log mysql数据库 mysq
原文地址:https://www.cnblogs.com/laoqing/p/11327403.html