标签:rtti default 拷贝 自动 atomic fir 执行 循环 strong
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。
在VS中启用OpenMP很简单,很多主流的编译环境都内置了OpenMP。在项目上右键->属性->配置属性->C/C++->语言->OpenMP支持,选择“是”即可。
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:
OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译制导、API函数集和环境变量。
编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma omp 指令[子句[,子句] …]。常用的功能指令如下:
相应的OpenMP子句为:
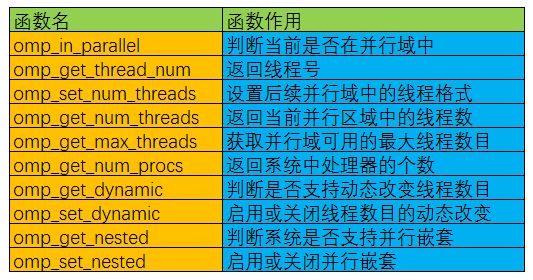
除上述编译制导指令之外,OpenMP还提供了一组API函数用于控制并发线程的某些行为,下面是一些常用的OpenMP API函数以及说明:
OpenMP中定义一些环境变量,可以通过这些环境变量控制OpenMP程序的行为,常用的环境变量:
parallel制导指令用来创建并行域,后边要跟一个大括号将要并行执行的代码放在一起:
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel
{
cout << "Test" << endl;
}
system("pause");
}
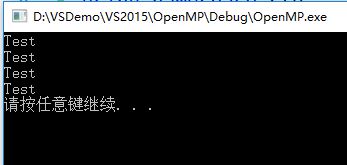
执行以上程序有如下输出:
程序打印出了4个“Test”,说明parallel后的语句被4个线程分别执行了一次,4个是程序默认的线程数,还可以通过子句num_threads显式控制创建的线程数:
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel num_threads(6)
{
cout << "Test" << endl;
}
system("pause");
}
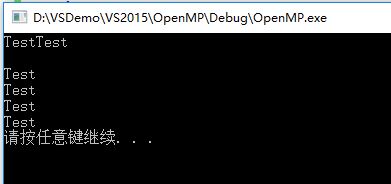
编译运行有如下输出:
程序中显式定义了6个线程,所以parallel后的语句块分别被执行了6次。第二行的空行是由于每个线程都是独立运行的,在其中一个线程输出字符“Test”之后还没有来得及换行时,另一个线程直接输出了字符“Test”。
使用parallel制导指令只是产生了并行域,让多个线程分别执行相同的任务,并没有实际的使用价值。parallel for用于生成一个并行域,并将计算任务在多个线程之间分配,从而加快计算运行的速度。可以让系统默认分配线程个数,也可以使用num_threads子句指定线程个数。
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
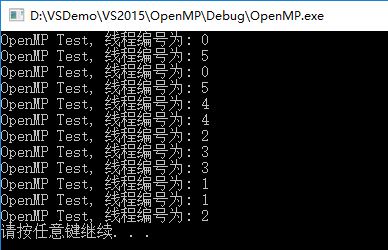
#pragma omp parallel for num_threads(6)
for (int i = 0; i < 12; i++)
{
printf("OpenMP Test, 线程编号为: %d\n", omp_get_thread_num());
}
system("pause");
}
运行输出:
上边程序指定了6个线程,迭代量为12,从输出可以看到每个线程都分到了12/6=2次的迭代量。
#include<iostream>
#include"omp.h"
using namespace std;
void test()
{
for (int i = 0; i < 80000; i++)
{
}
}
void main()
{
float startTime = omp_get_wtime();
//指定2个线程
#pragma omp parallel for num_threads(2)
for (int i = 0; i < 80000; i++)
{
test();
}
float endTime = omp_get_wtime();
printf("指定 2 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定4个线程
#pragma omp parallel for num_threads(4)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 4 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定8个线程
#pragma omp parallel for num_threads(8)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 8 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//指定12个线程
#pragma omp parallel for num_threads(12)
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("指定 12 个线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
//不使用OpenMP
for (int i = 0; i < 80000; i++)
{
test();
}
endTime = omp_get_wtime();
printf("不使用OpenMP多线程,执行时间: %f\n", endTime - startTime);
startTime = endTime;
system("pause");
}
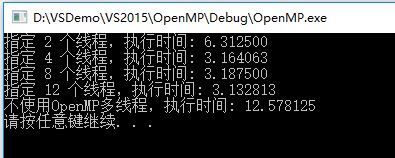
以上程序分别指定了2、4、8、12个线程和不使用OpenMP优化来执行一段垃圾程序,输出如下:
可见,使用OpenMP优化后的程序执行时间是原来的1/4左右,并且并不是线程数使用越多效率越高,一般线程数达到4~8个的时候,不能简单通过提高线程数来进一步提高效率。
标签:rtti default 拷贝 自动 atomic fir 执行 循环 strong
原文地址:https://www.cnblogs.com/mazhenyu/p/11328932.html