标签:探索 更改 ret 结合 @param int mina 新版 没有
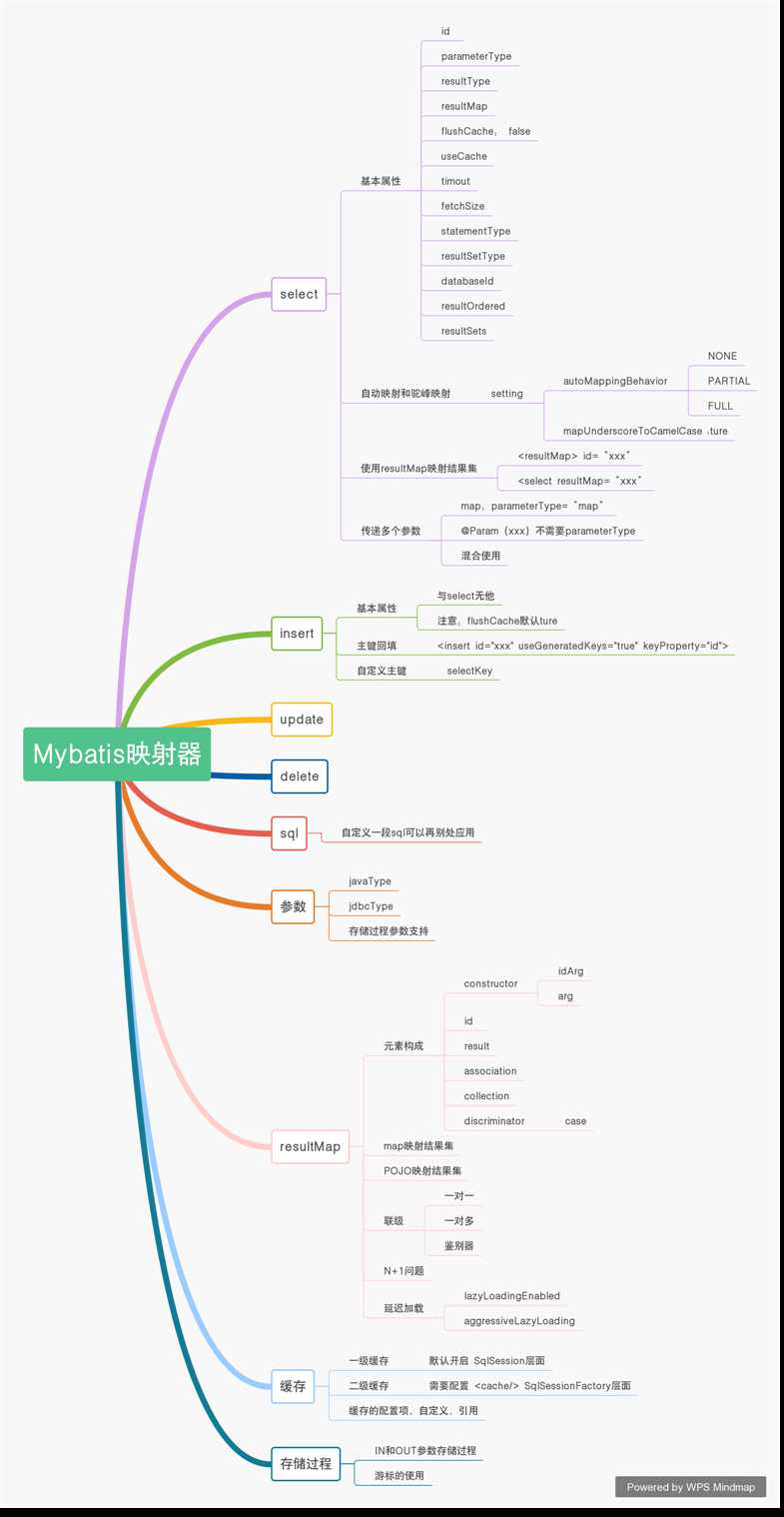
Mybatis映射器xml配置包含如下标签:
| 属性 | 说明 | 备注 |
|---|---|---|
| id | 它和Mybatis的命名空间组合起来是唯一的,提供MyBatis调用 | 若果命名空间和id结合起来不唯一,MyBatis会抛异常 |
| parameterType | 参数类型,可以给出类的全命名,也可以给出别名,但是别名必须是MyBatis内部定义或者自定义的 | 可以选择JavaBean、map等简单的参数传递给SQL |
| 新版废弃的,不建议使用 | -- | |
| resultType | 定义类的全路径,在允许自动匹配的情况下,结果集将通过 JavaBean 的规范映射;或定义为 int、double、float、map 等参数;也可以使用别名,但是要符合别名规范,且不能和 resultMap时使用 | 常用的参数之 ,比如统计总条数时可以把它的值设置为 int |
| resultMap | 它是映射集的引用,将执行强大的映射功能。我们可以使用resultType和 resultMap 其中的一个, resultMap 能提供自定义映射规则的机会 | MyBatis最复杂的元素,可以配置映射规则、联级、typeHandler |
| flushCache | 它的作用是在调用SQL后,是否要求MyBatis清空之前查询本地缓存和二级缓存 | 取值为布尔型,true/false默认值为false |
| userCache | 启动二级缓存的开关,要求MyBatis将此次的结果缓存 | 取值为布尔型,true/false默认值为true |
| timeout | 设置超时参数,超时后将抛出异常,单位为 秒 | 默认值是数据库厂商提供的JDBC驱动所设置的秒数 |
| fetchSize | 获取记录的总条数设定 | 默认值是数据库厂商提供的JDBC驱动所设置的条数 |
| statementType | 告诉MyBatis使用哪个JDBC的Statement工作,取值为STATEMENT(Statement)、PREPARED(PreparedStatement)、CALLABLE(CallableStatement) | 默认为PREPARED |
| resultSetType | 这是对 JDBC resultSet 接口而言,它的值包括FORWARD_ONLY (游标允许向前访问)、 SCROLL_SENSITIVE (双向滚动 ,但不及时更新,就是如果数据库里的数据修改过不在 re ultSet 中反映出来)、 SC ROLL INSENSITIVE (双向滚动,并及时跟踪数据库的更新,以便更改 re ultSet 中的数据) | 默认值是数据库厂商提供的 JDBC 驱动所设置的 |
| databaseId | 结合setting的databaseIdProvider数据库厂商标识 | 支持不同的数据库sql |
| resultOrderd | 这个设置仅适用于嵌套结果 select 语句 如果为 true ,就是假设包含了嵌套结果集或是分组了,当返回 个主结果行时,就不 能引用前面结果集了 。这就确保了在获取嵌套的结果集时不至于 导致内存不够用 | 取值为布尔型,true/false默认值为false |
| resultSets | 适合于多个结果集的情况,它将列出执行 SQL 后每个结果集的名称,每个名称之间用逗号分隔 | 很少使用 |
在setting元素中提供了两个可以配置的选项:
map
使用@Param注解
JavaBean传递参数
混合使用
public Paging fidPageByUser(@Param("user") User user,@Param("page")PageParam pageParam);<select id="fidPageByUser" resultType="paging">
select * from t_user
where user_name like
concat('%',#{user.name},'%')
and age != #{user.age}
limit #{page.start},#{page.limit}
</select>总结:
resultMap标签可以支持复杂的映射,如typeHandler、联级等。同时select标签也提供了resultMap属性将定义好的resultMap作为映射结果集。
| 属性 | 描述 | 备注 |
|---|---|---|
| id | SQL编号,用于标识这条SQL | 唯一,不然抛异常 |
| parameterType | 参数类型,同select | 可以单个也可以多个 |
| 废弃 | -- | |
| fushCache | 是否刷新缓存,为true,插入时会刷新一、二级缓存 | 默认值 true,而select默认false |
| timeout | 超时时间,单位 秒 | -- |
| statementType | 告诉MyBatis使用哪个JDBC的Statement工作,取值为STATEMENT(Statement)、PREPARED(PreparedStatement)、CALLABLE(CallableStatement) | 默认为PREPARED |
| useGeneratedKeys | 是否启用JDBC的getDeneratedKeys方法来取出由数据库内部生成的主键。(如mysql的自增主键) | 默认为 false |
| keyProperty | 用来告诉系统,生成的主键放在哪个属性中。如果有多个就用,分割 |
默认值unset。不能和keyColumn连用。(仅对insert和update语句有用) |
| keyColumn | 用来告诉系统,生成的主键放在哪个属性中。如果有多个就用,分割 |
不能和keyProperty连用。(仅对insert和update语句有用) |
| databaseId | 不同数据库的不同语句 | -- |
<insert id="insertUser" parameterType="user" useGeneratedKeys="true" keyProperty="id">
insert into t_user(user_name,user_age) values(#{userName},#{age})
</insert><insert id="insertUser" parameterType="user">
<selectKey keyProperty="id" resultType="long" order="BEFORE">
select if(max(id)=null,1,max(id)+3) from t_user
</selectKey>
insert into t_user(user_name,user_age) values(#{userName},#{age})
</insert>sql标签的作用在于可以定义一条SQL的一部分,方便后面的SQL引用它,比如最典型的列名。通常在select、insert等语句中反复编译他们。
<sql id="userCols">
id,user_name,user_age
</sql>
<select id="selectOneById" parameterType="long" resultMap="userMap">
select <include refid="userCols" /> from t_user where id = #{id}
</select>
<insert id="insertUser" parameterType="user">
insert into t_user(<include refid="userCols" />) values(#{id},#{userName},#{userAge})
</insert>传递变量给sql标签:
<sql id="userCols">
${alias}.id,${alias}.user_name,${alias}.user_age
</sql>
<select id="selectOneById" parameterType="long" resultMap="userMap">
select
<include refid="userCols" >
<property name="alias" value="r" />
</include>
from t_user r where id = #{id}
</select>#{userName,typeHandler=com.example.mybatis.StringTypeHandler},#{userAge}#{age,javaType=int,jdbcType=NUMERIC,typeHandler=MyTypeHandler} #{width , javaType=double , jdbcType=NUMERIC, numericScale=2} 存储过程支持
#{id,mode=IN}
#{userName,mode=OUT}
#{age,mode=INOUT}特殊字符串的替换和处理
接口参数可以传递子类实例
insert(A a); B extends A; ==> insert(b);resultMap的作用是定义映射规则、联级更新、定制类型转换器等。但是只支持resultMap的查询。
resultMap元素的子元素:
<resultMap>
<constructor> <!--用于配置构造方法,不存在没有参数的构造方法的情况-->
<idArg />
<arg />
</constructor>
<id />
<result />
<association />
<collection />
<discriminator>
<case />
</discriminator>
</resultMap>result元素和idArg元素的属性
一般而言,任何select语句都可以使用map存储:
<select id="select" parameterType="string" resultType="map">
select xxxxxxxxxxx ...
</select>map原则上是可以匹配所有的结果集,但是可读性下降。更多推荐POJO的方式。
使用resultMap映射了。
mybatis的联级分为3种:
假设现在有 个关联关系完成了级联,那么只要再加入 个关联关系,就变成了 N+1个级联,所有的级联 SQL 会被执行,显然会有很多并不是我们关心的数据被取出,这样会造成很大的资源浪费,这就是 N+1问题,尤其是在那些需要高性能的互联网系统中,这往往是不被允许的。
所以有了延迟加载的功能,一开始只加载需要的部分,当我们需要时对应的记录才通过SQL取出来。
| 配置项 | 作用 | 配置选项说明 | 默认值 |
|---|---|---|---|
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。在特定关联关系中,可通过设置fetchType属性来覆盖该项的开关状态。 | true|false | false |
| aggressiveLazyLoading | 当启用时,对任意延迟属性的调用会使带有延迟加载属性的对象完整加载;反之,则每种属性按需加载。 | true|false | 版本3.41(包含)之前是true,之后为false |
mybatis中允许使用缓存,缓存一般都存放置在高速读/写的存储器上。
<cache />标签:探索 更改 ret 结合 @param int mina 新版 没有
原文地址:https://www.cnblogs.com/nm666/p/11329972.html