标签:mic xid ever 属性 hello 编号 spark sql foreach
图(Graph)的基本概念
图的术语-4
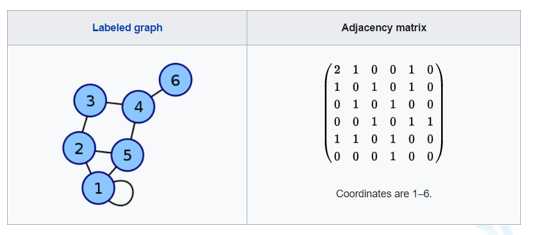
图的经典表示法(了解)
1、对于每条边,矩阵中相应单元格值为1
2、对于每个循环,矩阵中相应单元格值为2,方便在行或列上求得顶点度数
Spark GraphX 简介
1)基于内存实现了数据的复用与快速读取
2)通过弹性分布式属性图(Property Graph)统一了图视图与表视图
3)与Spark Streaming、Spark SQL和Spark MLlib等无缝衔接
GraphX核心抽象
顶点要带边,两个边构成编号
GraphX API
Graph[VD,ED]
VD:顶点的数据类型(二元组)
var rdd=sc.makeRDD(List((1L,"A"),(2L,"B")))
ED:边的数据类型
方法一:spark API
var spark=SparkSession.builder().master("local[2]")
.appName("hello").getOrCreate();
val sc=spark.sparkContext
val verticesRDD=sc.makeRDD(List((1L,1),(2L,2),(3L,3)))
val edgesRDD=sc.makeRDD(List(Edge(1L,2L,1),Edge(2L,3L,2)))
val graph=Graph(verticesRDD,edgesRDD)
graph.vertices.foreach(println(_))
graph.edges.foreach(println(_))
方法二:spark上运行
import org.apache.spark.graphx.{Edge,Graph}
var spark=SparkSession.builder().master("local[2]")
.appName("hello").getOrCreate();
val sc=spark.sparkContext
val verticesRDD=sc.makeRDD(List((1L,1),(2L,2),(3L,3)))
val edgesRDD=sc.makeRDD(List(Edge(1L,2L,1),Edge(2L,3L,2)))
val graph=Graph(verticesRDD,edgesRDD)
graph.vertices.collect
graph.edges.collect
graph.triplets.collect
图的算子-1
属性算子
对顶点进行遍历,传给你的顶点类型,生成新的顶点
def mapVertices[VD2](map: (VertexId, VD) => VD2)
def mapEdges[ED2](map: Edge[ED] => ED2)
结构算子
scala> graph1.reverse.triplets.collect
scala> graph1.subgraph(vpred=(id,attr)=>attr._2<30).triplets.collect
图的算子-3
join算子:从外部的RDDs加载数据,修改顶点属性
class Graph[VD, ED] {
def joinVertices[U](table: RDD[(VertexId, U)])(map: (VertexId, VD, U) => VD): Graph[VD, ED]
def outerJoinVertices[U, VD2](table: RDD[(VertexId, U)])(map: (VertexId, VD, Option[U]) => VD2)
: Graph[VD2, ED]
}
PageRank in GraphX
PageRank (PR)算法
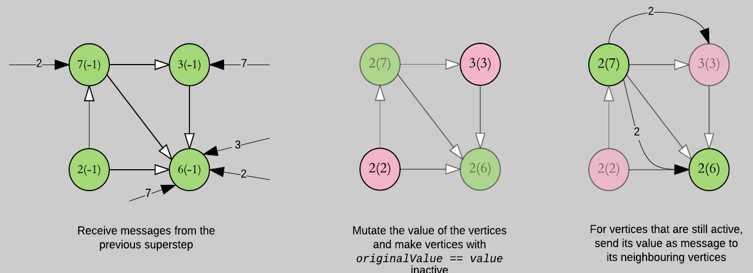
激活(active)和未激活(inactive)
!!!传过来的值和当前的值做对比,小(接受),大(本身去除)
1)首先我们默认将2里面(-1)作为旧值
2)我们将2值传送给7(-1)因为2<7:得出2(7)
3)我们将7值传送给3(-1)因为7>3:得出3(3)
initialMsg:在“superstep 0”之前发送至顶点的初始消息
maxIterations:将要执行的最大迭代次数
activeDirection:发送消息方向(默认是出边方向:EdgeDirection.Out)
vprog:用户定义函数,用于顶点接收消息
sendMsg:用户定义的函数,用于确定下一个迭代发送的消息及发往何处
mergeMsg:用户定义的函数,在vprog前,合并到达顶点的多个消息
--------------------------------------------------------------------------------------------------------------
def pregel[A](initialMsg: A, maxIterations: Int, activeDirection: EdgeDirection)(
vprog: (VertexID, VD, A) => VD,
sendMsg: EdgeTriplet[VD, ED] => Iterator[(VertexID,A)],
mergeMsg: (A, A) => A)
: Graph[VD, ED]
-----------------------------------------------------------------------------------------------------------------------
实例一:
入度:多个b对象指向a
case class User(name:String,ilike:Int,follow:Int)
import org.apache.spark.graphx._
//原始图
var points=sc.makeRDD(Array((1L,"zs"),(2L,"ls")))
var edges = sc.makeRDD(Array(Edge(2L,1L,1)))
var graph=Graph(points,edges)
//改变点的信息的结构
var newGraph=graph.mapVertices(
(id,name)=>User(name,0,0))
newGraph.inDegrees.collect//这是一张表
//将新节点表和入度表联合outerjoin
val nnGraph=newGraph.outerJoinVertices(newGraph.inDegrees)((id,lf,rf)=>User(lf.name,lf.ilike,rf.getOrElse(0)))
scala> nnGraph.pageRank(0.01).triplets.collect
标签:mic xid ever 属性 hello 编号 spark sql foreach
原文地址:https://www.cnblogs.com/tudousiya/p/11333440.html