标签:使用 总结 ESS 通过 target 鼓励 不重启 autot 预测
AutoTikv是一个用于对TiKV数据库进行自动调优的工具。它的设计灵感来自于SIGMOD 2017的一篇paper:Automatic Database Management System Tuning Through Large-scale Machine Learning,使用机器学习模型对数据库参数进行自动调优。
设计目标
整个调优过程大致如下图:
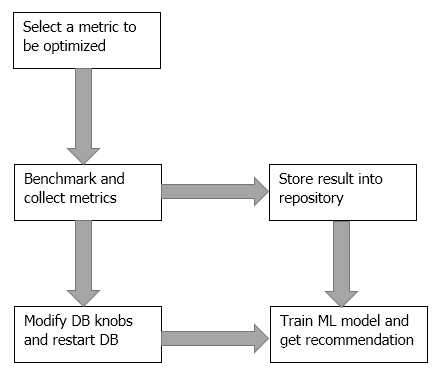
AutoTiKV支持在修改参数之后重启tikv(也可以选择不重启)。需要调节的参数和需要查看的metric可以在controller.py里声明。
以下是一个knob的声明样板:
"write-buffer-size": # name of the knob { "changebyyml": True, # True表示通过修改tikv-ansible/conf/tikv.yml来调节 "set_func": None, # 若changebyyml==False,则在此指定修改参数的函数名(函数也定义在controller.py里,一般就用tikv-ctl命令行来调节) "minval": 64, # if type!=enum, indicate min possible value "maxval": 1024, # if type!=enum, indicate max possible value "enumval": [], # if type==enum, list all valid values "type": "int", # int / enum / real "default": 64 # default value },
以下是一个metric的声明样板:
"write_latency": { "read_func": read_write_latency, # 声明查看该指标的函数(函数也定义在controller.py里) "lessisbetter": 1, # whether less value of this metric is better(1: yes) "calc": "ins", # ins表示该参数的值就是benchmark之后查看的结果。inc表示该参数是incremental的,需要把benchmark之后和之前的值相减作为结果。 },
一开始的10轮(具体大小可以调节)是用随机生成的knob去benchmark,之后的都是用ML模型推荐的参数去benchmark。
ML模型
AutoTikv也使用了和OtterTune 一样的高斯过程回归来推荐新的knob。即估计出 f: X->Y(比如对于参数X,估计出latency Y的值),则问题变为寻找合适的X,使f(X)的值尽量小。这样我们在f上面做梯度下降即可找出合适的X使Y尽量降低(如果Y是越大越好,比如throughput,直接对所有的Y取负值即可)。如下图所示:
用高斯回归的好处之一是:1. 和神经网络之类的方法相比,高斯过程模型属于无参数模型,相对解决的问题复杂度及与其它算法比较减少了算法计算量;而且在训练样本很少的情况下表现比NN更好。2. 它不仅能在给定X时估计对应的Y值,还能估计X的均值m(X)和标准差s(X)。
高斯回归还有一个性质:在寻找新的推荐值的时候,会综合考虑探索(exploration)和利用(exploitation):
在推荐的过程中,既要探索新的区域,也要利用已知区域的数据进行推荐,即需要平衡探索和利用,否则可能会陷入局部最优而无法找到全局最优的点。比如一直利用已知区域的数据来推荐,虽然能找到这个区域最好的点,但未知区域可能有效果更好的点未被发现。而一直在探索又会使得搜索过程很低效。而平衡这二者的核心思想是:当数据足够多时,我们利用这些数据推荐;而当缺少数据时,我们在点最少的区域进行探索,探索最未知的区域能给我们最大的信息量。
以上利用了高斯过程回归的特性:它会估计出均值m(X)和标准差s(X),若X周围的数据不多,则它估计的标准差s(X)会偏大(这个X和其他数据点的差异大),直观的理解是若数据不多,则不确定性会大,体现在标准差偏大。反之,数据足够时,标准差会偏小,因为不确定性减少。
在推荐时,使用置信区间上界Upper Confidence Bound来平衡探索和利用。不妨假设我们需要找X使Y值尽可能大。则 U(X) = m(X) + k*s(X),其中k > 0是可调的系数。我们只要找 X 使 U(X) 尽可能大即可。
在代码实现中,我们一开始random生成40个candidate knobs,然后用高斯回归模型计算出它们的U(X)和预测值,找出U(X)最大的那一个作为本次推荐的结果。
Ref:https://mp.weixin.qq.com/s/y8VIieK0LO37SjRRyPhtrw
实验测试结果
目前AutoTiKV支持调优以下参数:
总结
1
标签:使用 总结 ESS 通过 target 鼓励 不重启 autot 预测
原文地址:https://www.cnblogs.com/pdev/p/11318880.html