标签:汉语 nlp 参考 自动 比较 中文 class word 一个
汉字是智慧和想象力的宝库。 ——索尼公司创始人井深大
在英语中,单词就是“词”的表达,一个句子是由空格来分隔的,而在汉语中,词以字为基本单位,但是一篇文章的表达是以词来划分的,汉语句子对词构成边界方面很难界定。例如:南京市长江大桥,可以分词为:“南京市/长江/大桥”和“南京市长/江大桥”,这个是人为判断的,机器很难界定。在此介绍中文分词工具jieba,其特点为:
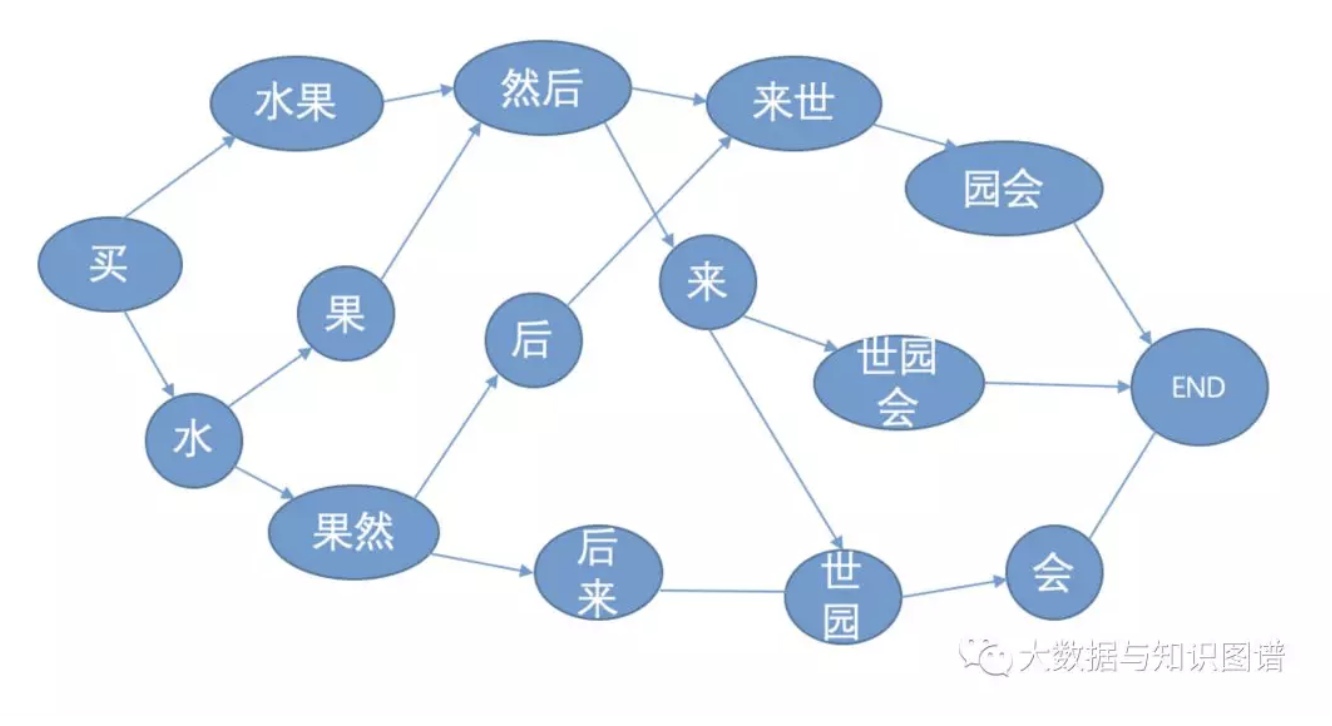
Jieba分词结合了基于规则和基于统计这两类方法。首先基于前缀词典进行词图扫描,前缀词典是指词典中的词按照前缀包含的顺序排列,例如词典中出现了“买”,之后以“买”开头的词都会出现在这一部分,例如“买水”,进而“买水果”,从而形成一种层级包含结构。若将词看成节点,词与词之间的分词符看成边,则一种分词方案对应着从第一个字到最后一个字的一条分词路径,形成全部可能分词结果的有向无环图。
安装很简单,先创建一个python3.6的虚拟环境,再激活环境,最后安装命令如下:
conda create -n nlp_py3 python=3.6
source activate nlp_py3
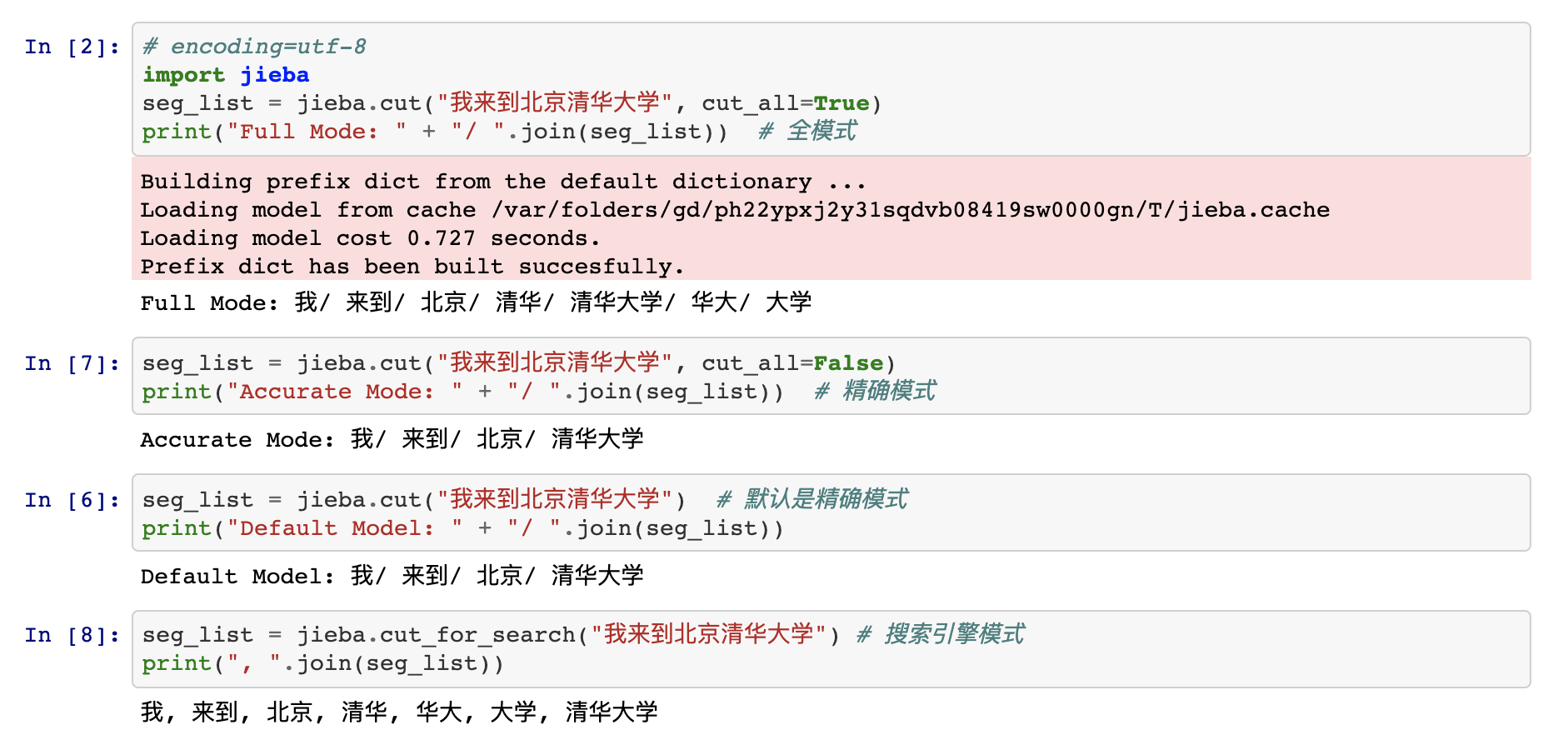
pip install jieba支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析。
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义。
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
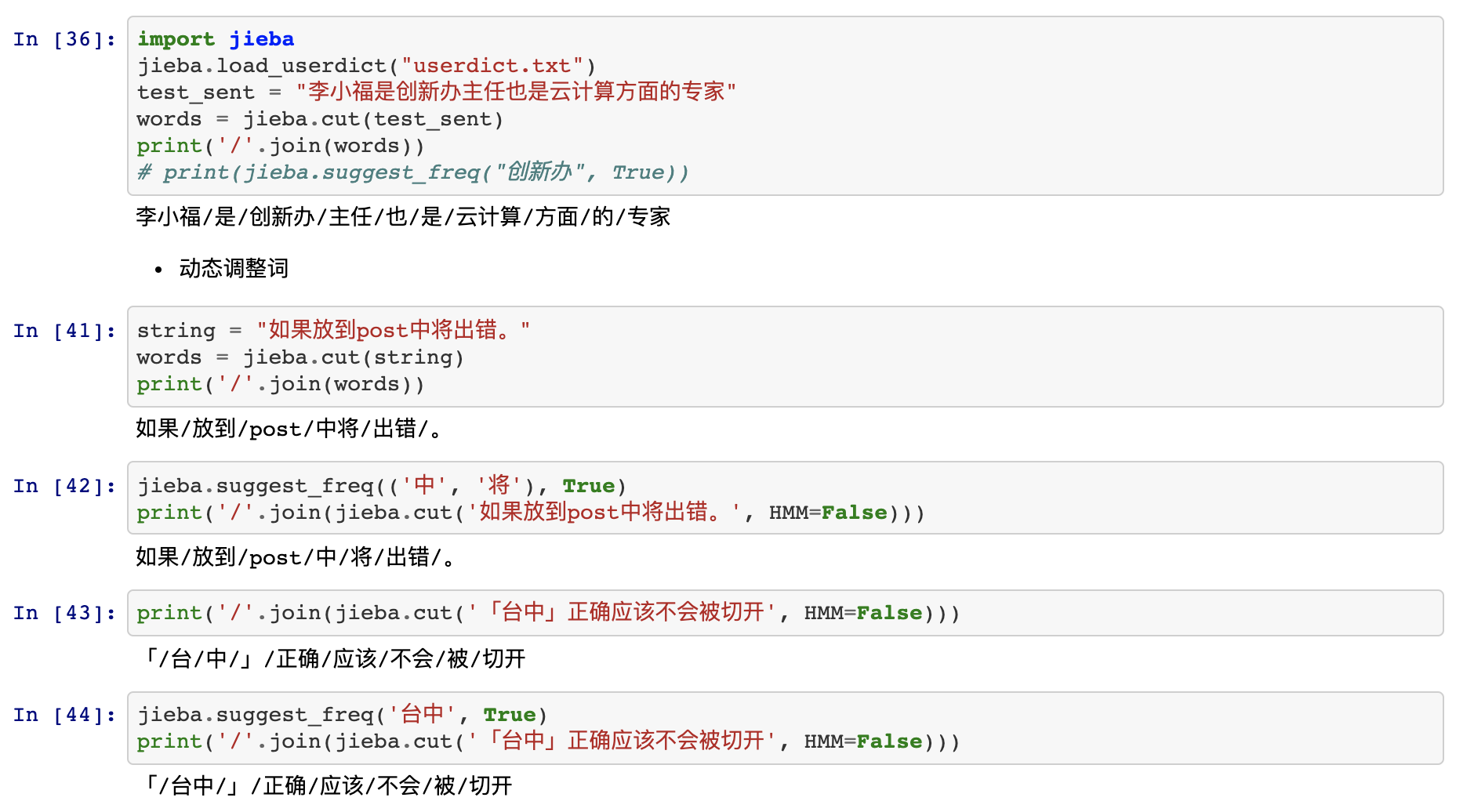
支持自定义词典
MIT 授权协议
1. 分词
执行示例:
2.添加自定义词典
执行示例:
tips:
P(台中) < P(台)×P(中),“台中”词频不够导致其成词概率较低
解决方法:强制调高词频
jieba.add_word('台中')
或者
jieba.suggest_freq('台中', True)参考官网:https://github.com/fxsjy/jieba

标签:汉语 nlp 参考 自动 比较 中文 class word 一个
原文地址:https://www.cnblogs.com/zeppelin/p/11335457.html