标签:span 来源 frame lan 存储 ret 参数 需要 down
,二叉树是一颗线段树,树状数组,树上的每个维护节点负责维护一个区间信息,节点之间又包含和属于的关系。例如线段树:
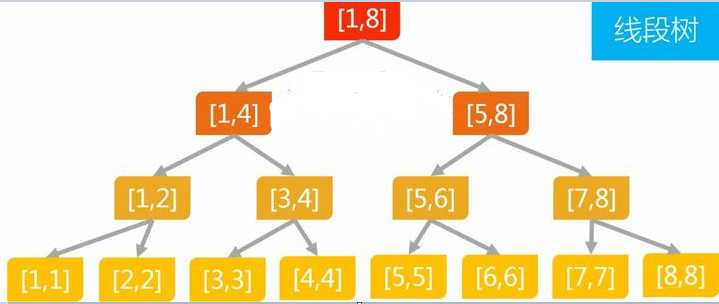
DFS序:
我们通过对每个节点设置两个量,in和out。从根节点开始DFS搜索,in为第一次搜索到时的时间戳,out为退出出栈时的时间戳。
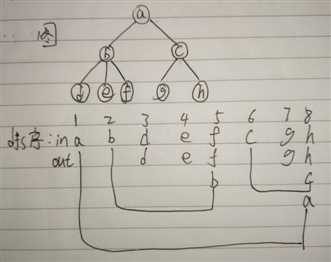
可以得到,例如我们要查询以b为根节点我们只需要查询区间[2,5];要查询以c为根节点子树的信息,我们可以查询区间[6,7];查询a需要查询区间[1,8]。在程序中,当要查询修改时,我们可以用线段树去维护,因为这些序列的性质和线段树太像了。我们要注意线段树的父区间等于两个子区间的和,而这个序列的区间等于父节点以及所有后代节点,例如b树,区间[2,5]包括了b点和d,e,f点,所以在线段树的区间中我们要保存的是原图中的子树。但是对于一些不规则的区间,例如查询[5,7]或是[2,4],虽然身在线段树上我们能找到它,但是在原图中没有什么实际意义或者我不易知道这个区间的意义。所以查找时,一般是通过点找区间,而不是直接查找区间。
[1,1],[2,2],[3,3]...[x,x]代表了原图中节点x的值,in[x],out[x]对应了以x为根节点子树的信息
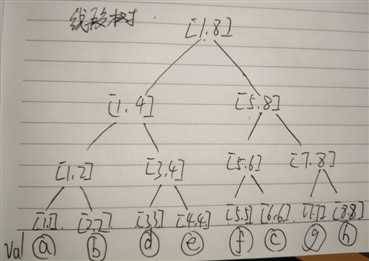
来两道例题:
卡卡屋前有一株苹果树,每年秋天,树上长了许多苹果。卡卡很喜欢苹果。树上有N个节点,卡卡给他们编号1到N,根的编号永远是1.每个节点上最多结一个苹果。卡卡想要了解某一个子树上一共结了多少苹果。
现在的问题是不断会有新的苹果长出来,卡卡也随时可能摘掉一个苹果吃掉。你能帮助卡卡吗?
Input
输入数据:第一行包含一个整数N(N <= 100000),表示树上节点的数目。
接下来N-1行,每行包含2个整数u和v,表示u和v是连在一起的。
下一行包含一个整数M(M ≤ 100,000).
接下来M行包含下列两种命令之一:
"C x" 表示某个节点上的苹果发生了变化,如果原来没有苹果,则现在长出了一个苹果;如果原来有苹果,则是卡卡把它吃了。
"Q x" 表示查询x节点上的子树上的苹果有多少。包含节点x.
Output
#include<stdio.h> #include<iostream> #include<algorithm> using namespace std; const int maxn=1e5+10; struct node{ int u,v,nxt; }g[maxn]; int head[maxn],in[maxn],out[maxn],sum[maxn*4],tim; void pushup(int rt){ sum[rt]=sum[rt<<1]+sum[rt<<1|1]; } void build(int rt,int L,int R){ if(L==R){ sum[rt]=1; return ; } int mid=(L+R)>>1; build(rt<<1,L,mid); build(rt<<1|1,mid+1,R); pushup(rt); } void update(int rt,int L,int R,int pos){ if(L==R){ if(sum[rt]) sum[rt]=0; else sum[rt]=1; return ; } int mid=(L+R)>>1; if(pos<=mid) update(rt<<1,L,mid,pos); else update(rt<<1|1,mid+1,R,pos); pushup(rt); } int query(int rt,int L,int R,int l,int r){ if(l<=L&&r>=R){ return sum[rt]; } int mid=(L+R)>>1,ans=0; if(r<=mid) ans=query(rt<<1,L,mid,l,r); else if(l>mid) ans=query(rt<<1|1,mid+1,R,l,r); else ans=query(rt<<1,L,mid,l,r)+query(rt<<1|1,mid+1,R,l,r); return ans; } void dfs(int now,int fa){ in[now]=++tim; for(int i=head[now];i!=-1;i=g[i].nxt) { if(g[i].v==fa) continue; dfs(g[i].v,now); } out[now]=tim; } int main(){ int n,m,cnt=0; scanf("%d",&n); for(int i=1;i<=n;i++) head[i]=-1; for(int i=1;i<n;i++){ int u,v; scanf("%d%d",&u,&v); g[++cnt].u=u; g[cnt].v=v; g[cnt].nxt=head[u]; head[u]=cnt; } dfs(1,0); build(1,1,n); scanf("%d",&m); for(int i=1;i<=m;i++){ char ch; int x; getchar(); scanf("%c%d",&ch,&x); if(ch==‘C‘) update(1,1,n,in[x]); else if(ch==‘Q‘) cout<<query(1,1,n,in[x],out[x])<<endl; } return 0; }
Input输入数据第一行是一个整数T(T≤10)T(T≤10),表示有TT组测试数据。
对于每组数据,包含两个整数n,m(1≤n,m≤100000)n,m(1≤n,m≤100000),表示有nn个零食机,mm次操作。
接下来n−1n−1行,每行两个整数xx和y(0≤x,y<n)y(0≤x,y<n),表示编号为xx的零食机与编号为yy的零食机相连。
接下来一行由nn个数组成,表示从编号为0到编号为n−1n−1的零食机的初始价值v(|v|<100000)v(|v|<100000)。
接下来mm行,有两种操作:0 x y0 x y,表示编号为xx的零食机的价值变为yy;1 x1 x,表示询问从编号为0的零食机出发,必须经过编号为xx零食机的路线中,价值总和的最大值。
本题可能栈溢出,辛苦同学们提交语言选择c++,并在代码的第一行加上:
`#pragma comment(linker, "/STACK:1024000000,1024000000") `Output对于每组数据,首先输出一行”Case #?:”,在问号处应填入当前数据的组数,组数从1开始计算。
对于每次询问,输出从编号为0的零食机出发,必须经过编号为xx零食机的路线中,价值总和的最大值。
Sample Input
1 6 5 0 1 1 2 0 3 3 4 5 3 7 -5 100 20 -5 -7 1 1 1 3 0 2 -1 1 1 1 5
Sample Output
Case #1: 102 27 2 20
预处理每个节点到编号0的距离,线段树维护区间中的编号,到编号0的距离,查询经过x,就是查询,(in[x],out[x])即,x及x图中的后代节点到根节点的最大值
#pragma comment(linker, "/STACK:1024000000,1024000000") #include<iostream>//单点改值 最大值 #include<string.h> #include<stdio.h> #include<vector> using namespace std; typedef long long LL; const long long inf=1e17; const int maxn=1e5+5; vector<int> g[maxn]; LL dis[maxn],w[maxn]; int dfs_clock; int n,m; struct Tree{ LL add,v; }sum[maxn<<2]; int fa[maxn];//父节点 int dep[maxn];//深度 int sz[maxn];//以o为根节点的子树节点数 int son[maxn];//重子节点 int rk[maxn];//rk[i]=u树链序为i的节点是U int top[maxn];//节点O所在重链的顶部节点 int id[maxn];//节点o在树链序的位置 void init(){ dfs_clock=0; // memset(dis,0,sizeof(dis)); memset(w,0,sizeof(w)); memset(fa,0,sizeof fa); memset(dep,0,sizeof dep); memset(sz,0,sizeof sz); memset(son,0,sizeof son); memset(rk,0,sizeof rk); memset(top,0,sizeof top); memset(id,0,sizeof id); memset(sum,0,sizeof sum); for(int i=0;i<maxn;i++){ sum[i].add=sum[i].v=0; } for(int i=0;i<maxn;i++) g[i].clear(); } void push_up(int rt){ sum[rt].v=sum[rt<<1].v+sum[rt<<1|1].v; } void build(int rt,int l,int r){ if(l==r){ sum[rt].v=w[rk[l]]; return ; } int mid=(l+r)>>1; build(rt<<1,l,mid); build(rt<<1|1,mid+1,r); push_up(rt); } void push_down(int rt,int l,int r){ int m=(l+r)/2; if(sum[rt].add!=0){ sum[rt<<1].v+=(m-l+1)*sum[rt].add; sum[rt<<1|1].v+=(r-m)*sum[rt].add; sum[rt<<1].add+=sum[rt].add; sum[rt<<1|1].add+=sum[rt].add; sum[rt].add=0; } } void update(int rt,int l,int r,int ll,int rr,LL d){ if(ll<=l&&r<=rr){ sum[rt].add+=d; sum[rt].v+=d*(r-l+1); return ; } push_down(rt,l,r); int mid=(l+r)>>1; if(ll<=mid) update(rt<<1,l,mid,ll,rr,d); if(rr>mid) update(rt<<1|1,mid+1,r,ll,rr,d); push_up(rt); } LL query(int rt,int l,int r,int ll,int rr){ if(ll<=l&&r<=rr){ return sum[rt].v; } push_down(rt,l,r); int mid=(l+r)>>1; long long res=0; if(ll<=mid) res+=query(rt<<1,l,mid,ll,rr); if(rr>mid) res+=query(rt<<1|1,mid+1,r,ll,rr); return res; } void TreeSplitDfs1(int u,int prev,int depth){ fa[u]=prev; dep[u]=depth; sz[u]=1; for(int i=0;i<g[u].size();i++){ int v=g[u][i]; if(v==prev) continue; TreeSplitDfs1(v,u,depth+1); sz[u]+=sz[v]; if(sz[v]>sz[son[u]]) son[u]=v; } } void TreeSplitDfs2(int u,int tp){ top[u] = tp; id[u] = ++dfs_clock; rk[dfs_clock] = u; if (!son[u]) return; TreeSplitDfs2(son[u], tp); for(int i=0; i<g[u].size(); i++){ int v=g[u][i]; if( v==son[u] || v==fa[u]) continue; TreeSplitDfs2(v,v); } } LL TreeSplitQuery(int u,int v){ LL ret=0; // cout<<"ii"<<u<<endl; while( top[u]!=top[v]){ // cout<<"ss"<<endl; if(dep[ top[u] ]< dep[ top[v] ]) std::swap(u,v); ret+= query(1,1,n,id[ top[u] ],id[u]); u = fa[top[u]]; } if(id[u] > id[v] ) std::swap(u,v); ret+=query(1,1,n,id[u],id[v]); return ret; } int main(){ init(); scanf("%d%d", &n, &m); for (int i = 1; i <= n; ++i) scanf("%lld", &w[i]); for (int i = 1, u, v; i < n; ++i) { scanf("%d%d", &u, &v); g[u].push_back(v); g[v].push_back(u); } TreeSplitDfs1(1, 0, 1); TreeSplitDfs2(1, 1); build(1, 1, n); int opt,x,a; for(int i=1;i<=m;i++){ scanf("%d",&opt); if(opt==1){ scanf("%d%d",&x,&a); update(1,1,n,id[x],id[x],a); } if(opt==2){ scanf("%d%d",&x,&a); update(1,1,n,id[x],id[x]+sz[x]-1,a); } if(opt==3){ scanf("%d",&x); cout<<TreeSplitQuery(x,1)<<endl; } } return 0; }
树链剖分
树链,即为通过dsf将树的一条长支作为一条链,有多少个叶节点就有多少条链,为了方便划分节点(重要的用处后面讲),我们将从一个节点出发到叶节点,能过使链最长的支成为这个节点的重链,且这个节点也属于这条链,他的其他分支都称为轻链。例如下图节点1的重链为1-3-7-10-13-16,其他都为他的轻链。以及要存储各节点的父节点,各条链的顶节点,节点的深度,节点的重子节点等等;
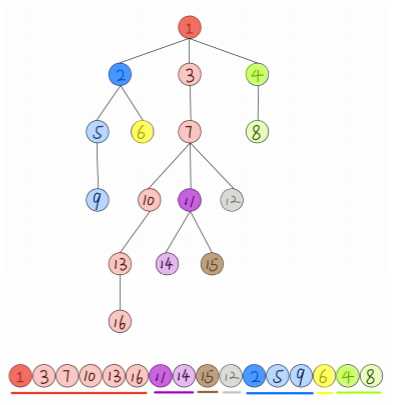 图片来源-LY学长
图片来源-LY学长
我们通过dfs可以得到和DFS序一样的in序列,一条下划线的代表一条链,但是即有DFS序,为何又要有树链剖分呢?DFS中我们说过,当操作的区间不是一整个子树的区间时,他的意义很迷。但是在剖序中,当我们要查询节点9到节点15的这条路径中节点的信息,因为树链变很容易。首先15比9更深,且不在同一条链上,我们用15开始操作:15是它所在链的顶节点,所以我们从15跳的他的父节点11,我们查11和9不在同一链,所以跳到11的顶节点3,在到3的父节点1,1和9在同一条链上,结束。好了,我们得到一些关键的数字,15,11,3,1,9,我们只需对[ id9 , id1 ] , [ id3 , id7 ] ,[ id11,id11 ] ,[ di15 , id15] 。对于为什么是这样解决,我认为的是,还是刚才的例子,现在我们只看下面的树链序:15的父节点是上一条链的中的11节点,因为他们属于两条链,分别访问[ id15,id15 ]和[ id3, id11 ] ,为什么不直接[ id15, id11]呢?其实这条路径上的点我们都要访问,对不同链分开访问实际是防止重复(我是不是啰嗦了?‘~‘),这也就是为啥分轻重链,其实没啥关键的原因,就是为了给顶节点分配一条链,是链的划分更有序啦
一道题:
对于每个询问操作,输出该询问的答案。答案之间用换行隔开。
Sample Output6 9 13 Hint
对于 100% 的数据, N,M<=100000 ,且所有输入数据的绝对值都不会超过 10^6 。
对于1,2操作,dfs序都能完成,操作3涉及了两个节点所以要用树链剖分,这里线段树节点维护的信息是区间和。值得注意的是操作2,像我一样不要迷,区间更新在树剖也是首节点x到尾(节点x加上根x的子树的节点数,DFS序节点x的out也可以这样表示)构成了图中根节点x的子树(DFS序更新一样)。
#pragma comment(linker, "/STACK:1024000000,1024000000") #include<iostream>//单点改值 最大值 #include<string.h> #include<stdio.h> #include<vector> using namespace std; typedef long long LL; const long long inf=1e17; const int maxn=1e5+5; vector<int> g[maxn]; LL dis[maxn],w[maxn]; int dfs_clock; int n,m; struct Tree{ LL add,v; }sum[maxn<<2]; int fa[maxn];//父节点 int dep[maxn];//深度 int sz[maxn];//以o为根节点的子树节点数 int son[maxn];//重子节点 int rk[maxn];//rk[i]=u树链序为i的节点是U int top[maxn];//节点O所在重链的顶部节点 int id[maxn];//节点o在树链序的位置 void init(){ dfs_clock=0; // memset(dis,0,sizeof(dis)); memset(w,0,sizeof(w)); memset(fa,0,sizeof fa); memset(dep,0,sizeof dep); memset(sz,0,sizeof sz); memset(son,0,sizeof son); memset(rk,0,sizeof rk); memset(top,0,sizeof top); memset(id,0,sizeof id); memset(sum,0,sizeof sum); for(int i=0;i<maxn;i++){ sum[i].add=sum[i].v=0; } for(int i=0;i<maxn;i++) g[i].clear(); } void push_up(int rt){ sum[rt].v=sum[rt<<1].v+sum[rt<<1|1].v; } void build(int rt,int l,int r){ if(l==r){ sum[rt].v=w[rk[l]]; return ; } int mid=(l+r)>>1; build(rt<<1,l,mid); build(rt<<1|1,mid+1,r); push_up(rt); } void push_down(int rt,int l,int r){ int m=(l+r)/2; if(sum[rt].add!=0){ sum[rt<<1].v+=(m-l+1)*sum[rt].add; sum[rt<<1|1].v+=(r-m)*sum[rt].add; sum[rt<<1].add+=sum[rt].add; sum[rt<<1|1].add+=sum[rt].add; sum[rt].add=0; } } void update(int rt,int l,int r,int ll,int rr,LL d){ if(ll<=l&&r<=rr){ sum[rt].add+=d; sum[rt].v+=d*(r-l+1); return ; } push_down(rt,l,r); int mid=(l+r)>>1; if(ll<=mid) update(rt<<1,l,mid,ll,rr,d); if(rr>mid) update(rt<<1|1,mid+1,r,ll,rr,d); push_up(rt); } LL query(int rt,int l,int r,int ll,int rr){ if(ll<=l&&r<=rr){ return sum[rt].v; } push_down(rt,l,r); int mid=(l+r)>>1; long long res=0; if(ll<=mid) res+=query(rt<<1,l,mid,ll,rr); if(rr>mid) res+=query(rt<<1|1,mid+1,r,ll,rr); return res; } void TreeSplitDfs1(int u,int prev,int depth){ fa[u]=prev; dep[u]=depth; sz[u]=1; for(int i=0;i<g[u].size();i++){ int v=g[u][i]; if(v==prev) continue; TreeSplitDfs1(v,u,depth+1); sz[u]+=sz[v]; if(sz[v]>sz[son[u]]) son[u]=v; } } void TreeSplitDfs2(int u,int tp){ top[u] = tp; id[u] = ++dfs_clock; rk[dfs_clock] = u; if (!son[u]) return; TreeSplitDfs2(son[u], tp); for(int i=0; i<g[u].size(); i++){ int v=g[u][i]; if( v==son[u] || v==fa[u]) continue; TreeSplitDfs2(v,v); } } LL TreeSplitQuery(int u,int v){ LL ret=0; // cout<<"ii"<<u<<endl; while( top[u]!=top[v]){ // cout<<"ss"<<endl; if(dep[ top[u] ]< dep[ top[v] ]) std::swap(u,v); ret+= query(1,1,n,id[ top[u] ],id[u]); u = fa[top[u]]; } if(id[u] > id[v] ) std::swap(u,v); ret+=query(1,1,n,id[u],id[v]); return ret; } int main(){ init(); scanf("%d%d", &n, &m); for (int i = 1; i <= n; ++i) scanf("%lld", &w[i]); for (int i = 1, u, v; i < n; ++i) { scanf("%d%d", &u, &v); g[u].push_back(v); g[v].push_back(u); } TreeSplitDfs1(1, 0, 1); TreeSplitDfs2(1, 1); build(1, 1, n); int opt,x,a; for(int i=1;i<=m;i++){ scanf("%d",&opt); if(opt==1){ scanf("%d%d",&x,&a); update(1,1,n,id[x],id[x],a); } if(opt==2){ scanf("%d%d",&x,&a); update(1,1,n,id[x],id[x]+sz[x]-1,a); } if(opt==3){ scanf("%d",&x); cout<<TreeSplitQuery(x,1)<<endl; } } return 0; }
后言:我们应该用DFS去确定区间,然后用线段树维护,序列的意义不是线段树决定的,线段树的区间维护的是图节点x的子树的或节点x和它的后代节点的信息。
欧拉序
对有树进行dfs,无论是递归正向
标签:span 来源 frame lan 存储 ret 参数 需要 down
原文地址:https://www.cnblogs.com/jjl0229/p/11337403.html