标签:isa 云服务 作业 多用户 strong jdk tag 网络模式 初识
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。它其实是将一个大文件分成若干块保存在不同服务器的多个节点中。通过联网让用户感觉像是在本地一样查看文件,为了降低文件丢失造成的错误,它会为每个小文件复制多个副本(默认为三个),以此来实现多机器上的多用户分享文件和存储空间。
Hadoop主要包含三个模块:
本节将会介绍Hadoop集群的配置,目标主机我们可以选择虚拟机中的多台主机或者多台阿里云服务器。
注意:以下所有操作都是在root用户下执行的,因此基本不会出现权限错误问题。
VMware虚拟机有三种网络模式,分别是Bridged(桥接模式)、NAT(网络地址转换模式)、Host-only(主机模式):
桥接:选择桥接模式的话虚拟机和宿主机在网络上就是平级的关系,相当于连接在同一交换机上;
NAT:NAT模式就是虚拟机要联网得先通过宿主机才能和外面进行通信;
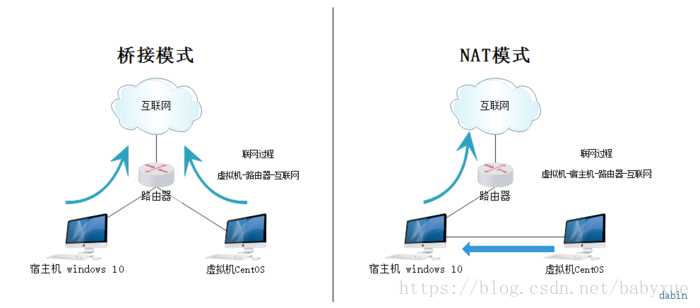
具体区别可以参考博客:Vmware虚拟机下三种网络模式配置。
VMware Workstation Pro 15中文破解版下载地址:http://www.zdfans.com/html/16025.html,参考安装破解教程进行安装。
CentOS7下载地址;http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso。
在Vmware中安装CentOS7的步骤可以参考博客:VMware安装Centos7超详细过程(图文)(包含克隆模式)。
1、网络模式配置为桥接模式,CentOS7网络IP配置参考博客:Centos7虚拟机桥接模式设置静态ip。
2、配置主机名
vi /etc/sysconfig/network

3、配置Host
vi /etc/hosts

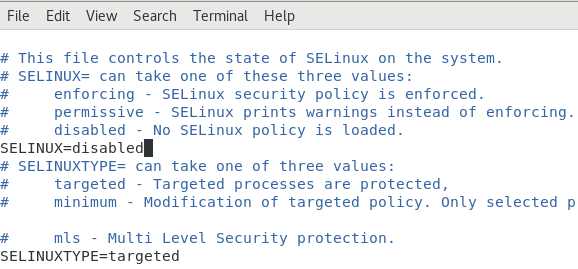
4、关闭防火墙和selinux
service iptables stop
vim /etc/sysconfig/selinux
如果可以申请到阿里云服务器推荐使用阿里云服务器,这里申请的时CentOS 7.2,相关步骤可以参考博客:大数据 -- zookeeper和kafka集群环境搭建第一节。
查看防火墙状态:
systemctl status firewalld

如果时开启,需要利用命令将防火墙关闭:
systemctl stop firewalld
systemctl disable firewalld
JDK安装可以参考博客大数据 -- zookeeper和kafka集群环境搭建第二节。
Hadoop部署模式主要有:本地模式、伪分布模式、完全分布式模式、HA完全分布式模式。
区分的依据是NameNode、DataNode、ResourceManager、NodeManager等模块运行在几个JVM进程、几个机器。
| 模式名称 | 各个模块占用的JVM进程数 | 各个模块运行在几个机器数上 |
|---|---|---|
| 本地模式 | 1个 | 1个 |
| 伪分布式模式 | N个 | 1个 |
| 完全分布式模式 | N个 | N个 |
| HA完全分布式 | N个 | N个 |
下面我选择将Hadoop伪分布式模式安装在阿里云服务器zy1主机上。伪分布式模式可以看作是完全分布式,但是跑在一个节点上,所有的进程都配置在一个节点上,拥有分布式文件系统,只不过这个系统只有一个节点。
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz tar -zxvf hadoop-2.8.5.tar.gz -C /opt/bigdata
重新命名:
mv hadoop-2.8.5 hadoop
vim /etc/profile
追加配置:
export HADOOP_HOME=/opt/bigdata/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使配置生效:
. /etc/profile
echo $HADOOP_HOME
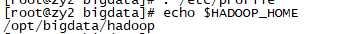
修改hadoop-env.sh:
vim ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java
vim ${HADOOP_HOME}/etc/hadoop/core-site.xml
添加内容如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://zy1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/data/hadoop</value>
</property>
</configuration>
*-default.xml等默认配置文件,就可以看到很多依赖${hadoop.tmp.dir}的配置。默认的hadoop.tmp.dir是/tmp/hadoop-${user.name},此时有个问题就是NameNode会将HDFS的元数据存储在这个/tmp目录下,如果操作系统重启了,系统会清空/tmp目录下的东西,导致NameNode元数据丢失,是个非常严重的问题,所有我们应该修改这个路径。创建临时目录:
mkdir -p /opt/bigdata/data/hadoop
vim ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
添加内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
dfs.replication配置的是HDFS存储时的备份数量,因为这里是伪分布式环境只有一个节点,所以这里设置为1。
hdfs namenode -format
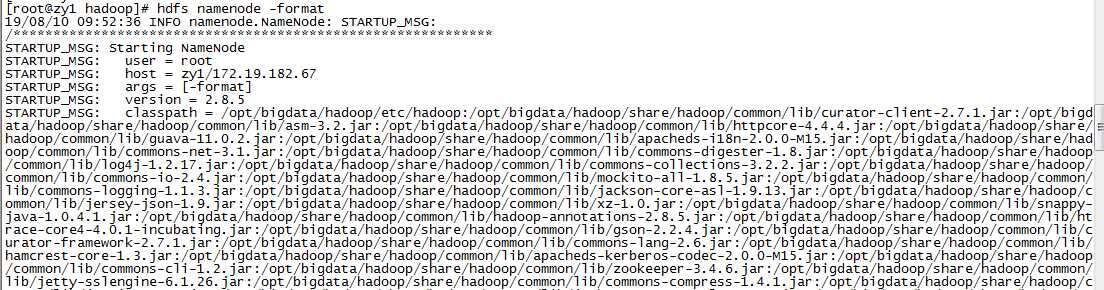
注意:如果格式化成功了,不可以再继续格式化,如果想继续格式化可以参考Hadoop1重新格式化HDFS。如果没有格式化成功,需要一直格式化。
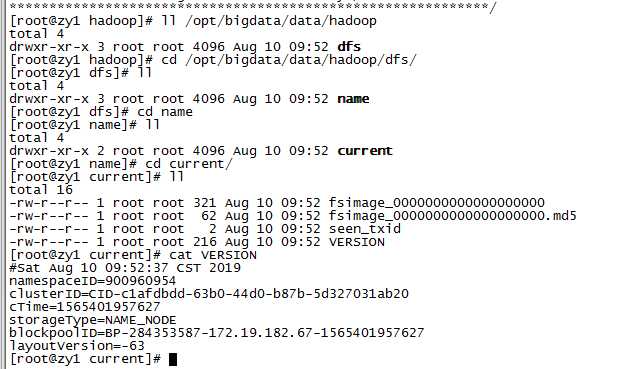
格式化后,查看core-site.xml里hadoop.tmp.dir(本例是/opt/bigdata/data/hadoop目录)指定的目录下是否有了dfs目录,如果有,说明格式化成功。
ll /opt/bigdata/data/hadoop
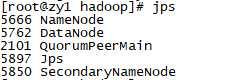
hadoop-daemon.sh start namenode

hadoop-daemon.sh start datanode

hadoop-daemon.sh start secondarynamenode

jps
HDFS上创建目录:
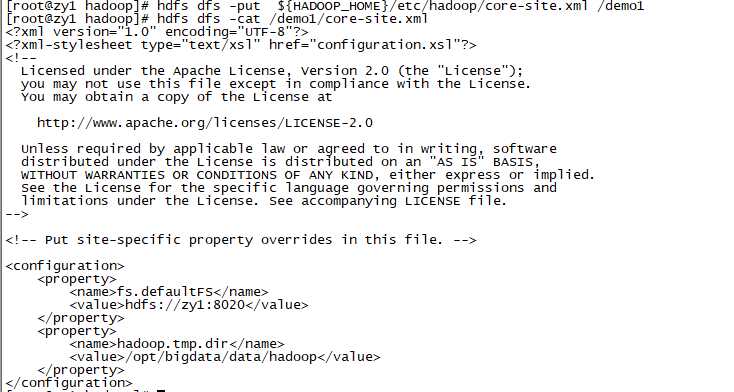
hdfs dfs -mkdir /demo1
上传本地文件到HDFS上:
hdfs dfs -put ${HADOOP_HOME}/etc/hadoop/core-site.xml /demo1
读取HDFS上的文件内容:
hdfs dfs -cat /demo1/core-site.xml
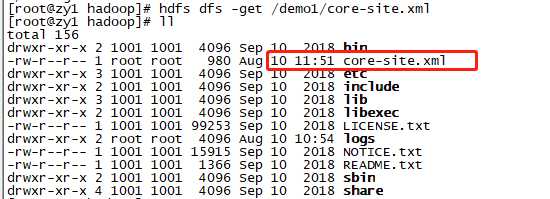
从HDFS上下载文件到本地:
hdfs dfs -get /demo1/core-site.xml
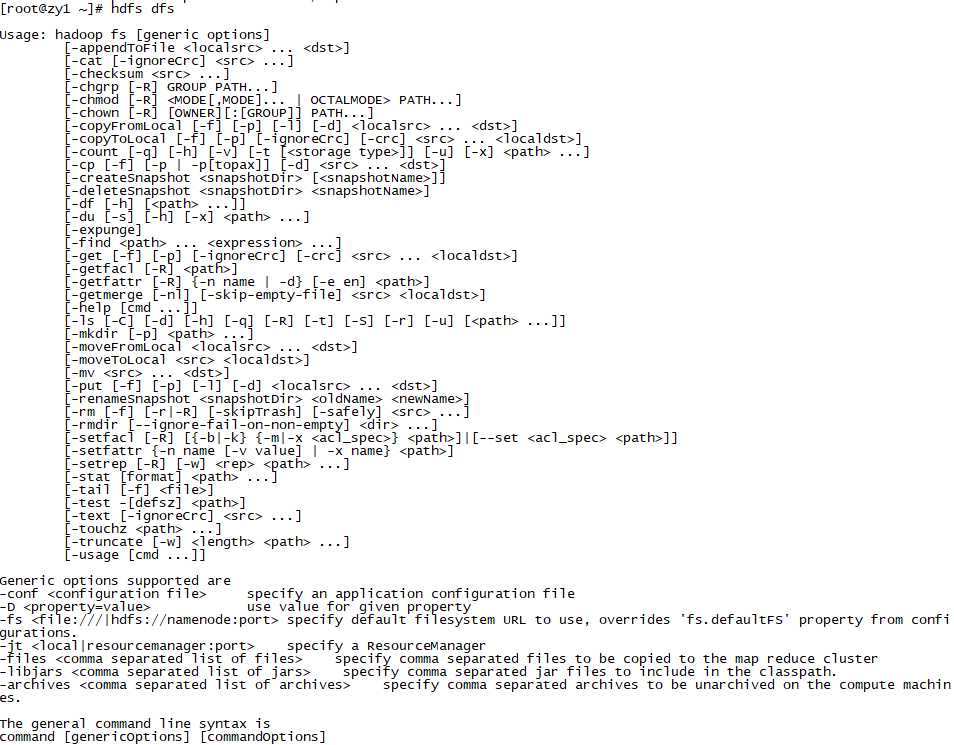
更多hdfs文件系统的命令可以查看:
hdfs dfs
默认没有mapred-site.xml文件,但是有个mapred-site.xml.template配置模板文件。复制模板生成mapred-site.xml:
cd /opt/bigdata/hadoop/
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
添加配置
vim etc/hadoop/mapred-site.xml
指定mapreduce运行在yarn框架上。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vim etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法。
yarn.resourcemanager.hostname指定了Resourcemanager运行在哪个节点上。
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>zy1</value>
</property>
</configuration>
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
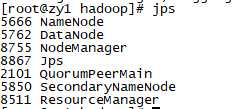
可以看到ResourceManager、NodeManager已经启动成功了。
YARN的Web客户端端口号是8088,通过http://106.15.74.155:8088/可以查看当前执行的job。
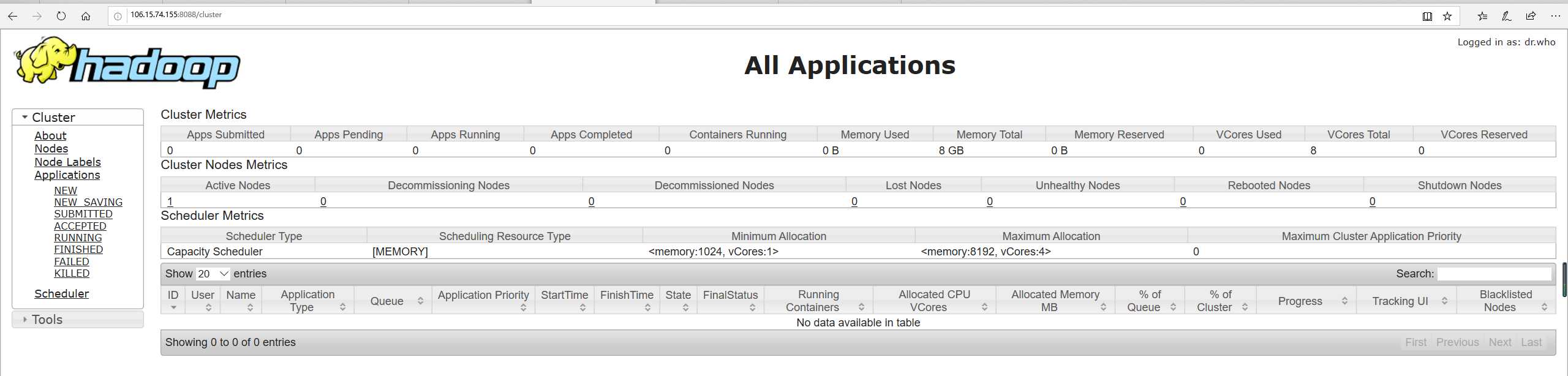
注意:由于使用到了8088端口。需要在阿里云中配置入规则,具体可以参考阿里云官方收藏:同一个地域、不同账号下的实例实现内网互通 。

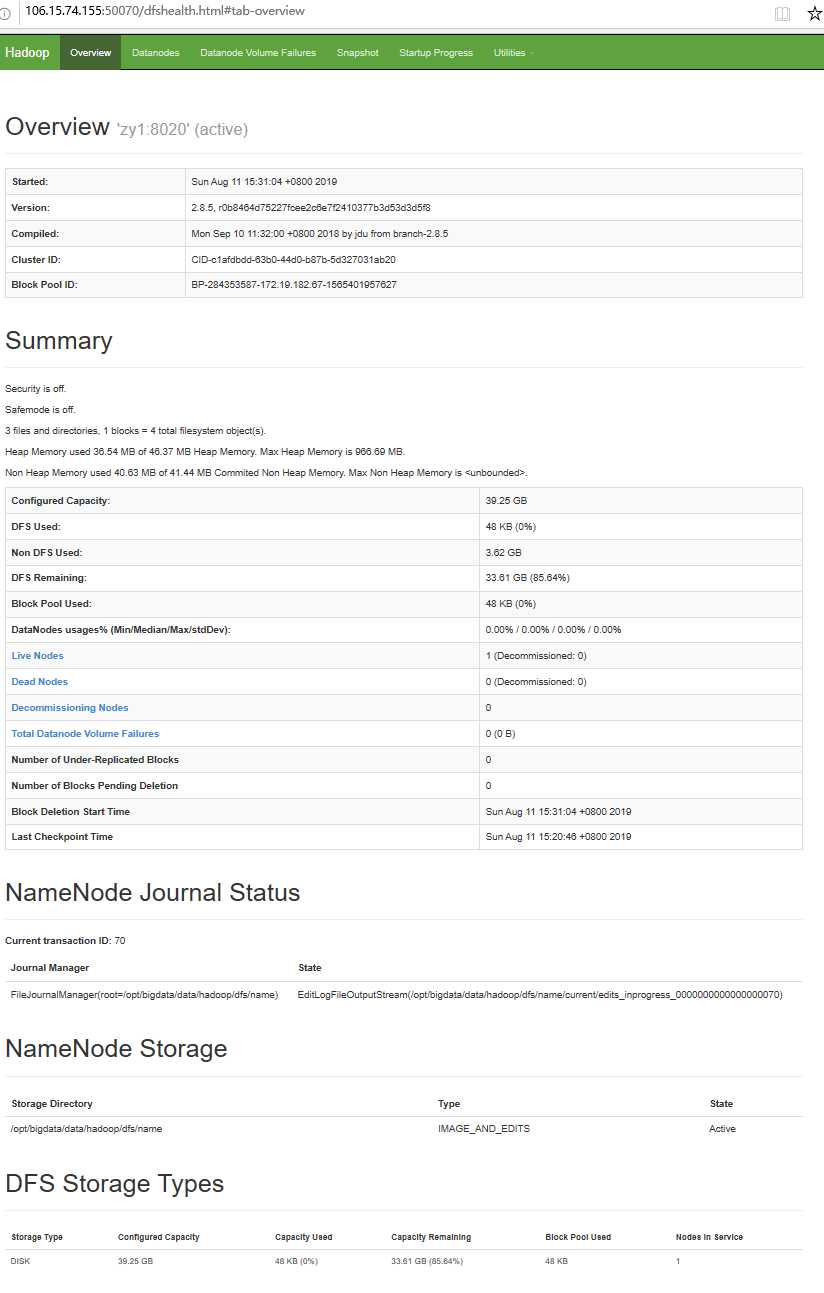
hdfs的Web客户端端口号是50070,通过http://106.15.74.155:50070/可以查看。
在Hadoop的share目录里,自带了一些jar包,里面带有一些mapreduce实例小例子,位置在share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar,可以运行这些例子体验刚搭建好的Hadoop平台,我们这里来运行最经典的WordCount实例。
在hdfs文件系统上创建测试用的Input文件:
hdfs dfs -mkdir -p /wordcountdemo/input
创建原始文件:
在本地/opt/bigdata/data/hadoop目录创建一个文件wc.input,vim /opt/bigdata/data/hadoop/wc.input内容如下:
doop mapreduce hive
hbase spark storm
sqoop hadoop hive
spark hadoop
将wc.input文件上传到HDFS的/wordcountdemo/input目录中:
hdfs dfs -put /opt/bigdata/data/hadoop/wc.input /wordcountdemo/input
运行WordCount MapReduce Job:
cd /opt/bigdata/hadoop yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /wordcountdemo/input /wordcountdemo/output
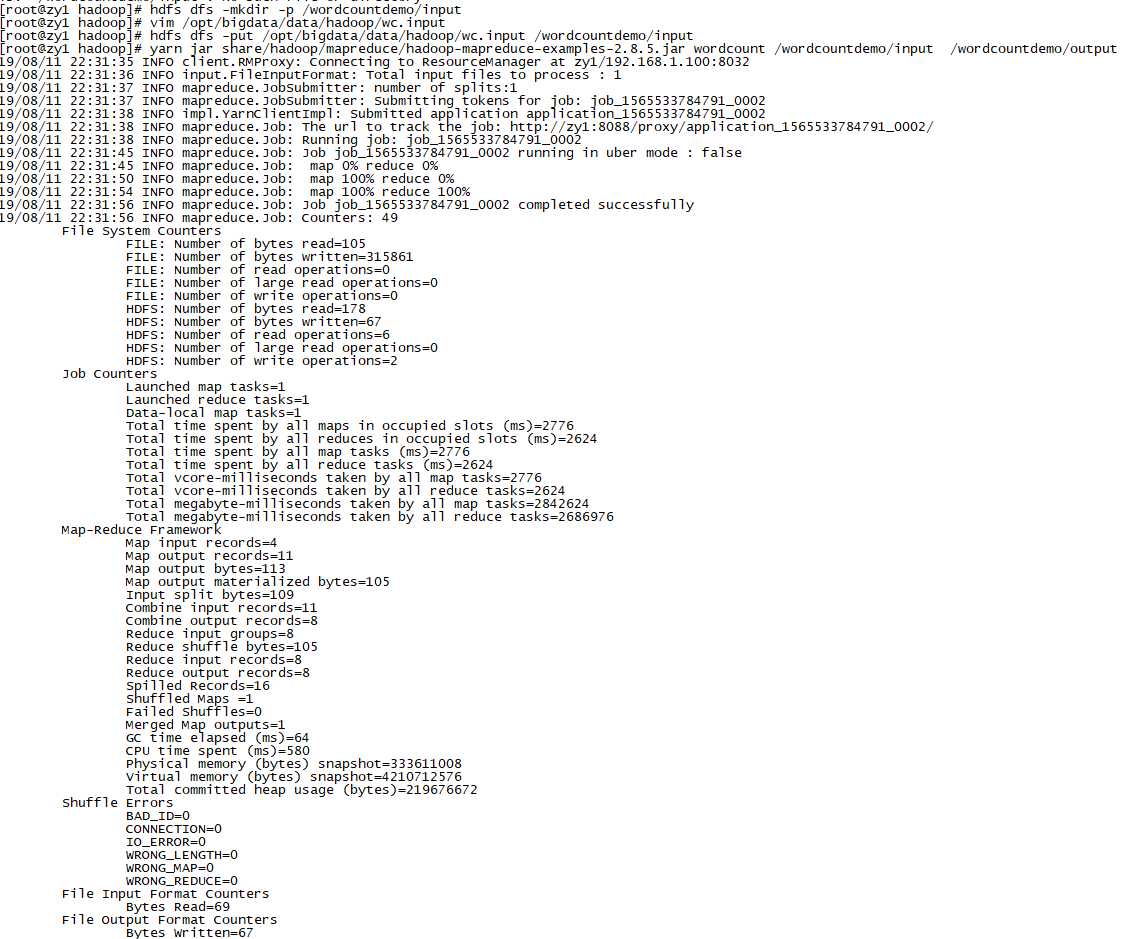
注意:如果执行一直卡在map 0% reduce 0%,可能是由于硬件配置较低的原因:

更多错误可以查看日志:$HADOOP_HOME/logs:
more $HADOOP_HOME/logs/yarn-root-nodemanager-zy1.log more $HADOOP_HOME/logs/yarn-root-resourcemanager-zy1.log
如果运行成功,查看输出结果目录:
hdfs dfs -ls /wordcountdemo/output

output目录中有两个文件:
查看输出文件内容:
hdfs dfs -cat /wordcountdemo/output/part-r-00000

结果是按照键值排好序的。
hadoop-daemon.sh stop namenode hadoop-daemon.sh stop datanode hadoop-daemon.sh stop secondarynamenode yarn-daemon.sh stop resourcemanager yarn-daemon.sh stop nodemanager
Hadoop开启历史服务可以在web页面上查看Yarn上执行job情况的详细信息。可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。
mr-jobhistory-daemon.sh start historyserver
开启后,可以通过Web页面查看历史服务器:http://106.15.74.155:19888/
MapReduce是在各个机器上运行的,在运行过程中产生的日志存在于各个机器上,为了能够统一查看各个机器的运行日志,将日志集中存放在HDFS上,这个过程就是日志聚集。
Hadoop默认是不启用日志聚集的。在yarn-site.xml文件里配置启用日志聚集。
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
yarn.log-aggregation-enable:是否启用日志聚集功能。
yarn.log-aggregation.retain-seconds:设置日志保留时间,单位是秒。
重启Yarn进程:
stop-yarn.sh start-yarn.sh
重启HistoryServer进程:
mr-jobhistory-daemon.sh stop historyserver mr-jobhistory-daemon.sh start historyserver
测试日志聚集:运行一个demo MapReduce,使之产生日志:
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar wordcount /wordcountdemo/input /wordcountdemo/output
运行Job后,就可以在历史服务器Web页面查看各个Map和Reduce的日志了。
参考文章
[2]阿里云hadoop安装教程_完全分布式_Hadoop 2.7.4/CentOS 7.4
标签:isa 云服务 作业 多用户 strong jdk tag 网络模式 初识
原文地址:https://www.cnblogs.com/zyly/p/11209286.html