标签:删除 复杂 重做日志 效率 销售 目标 附加 两种 多个
一、基本概念
ETL,它是Extract、Transform、Load三个单词的首写字母。ETL是建立数据仓库最重要的处理过程,也是工作量最大的环节,一般会占到整个数据仓库建立的一半工作量。
建立一个数据仓库,就是要把来自多个异构的源系统的数据集成在一起,然后放置于一个集中的位置,用于数据分析。
二、E:抽取
典型的源系统一般是事务处理应用,可能是一个销售分析数据仓库的源系统之一,又可能是一个订单录入系统,其中包括了订单的相关操作的全部行为记录。这些记录很多,很复杂,确定需要抽取的数据(目标数据)非常困难。通常数据都不是只抽取一次,而是需要一定的时间间隔反复抽取,通过这样的方式把数据的所有变化提供给数据仓库,保持数据的及时性。假设已经明确抽取的目标数据,就可以考虑使用哪种抽取方法。
抽取方法的选择高度依赖于源系统和目标数仓环境的业务需求。一般遵循两大原则:一、不可在源系统添加额外的逻辑;二、不能增加源系统的工作负载。即不可以对源系统具有侵入性。下面介绍抽取的两大方法:逻辑抽取和物理抽取。
1、逻辑抽取
逻辑抽取分为:全量抽取和增量抽取。
1.1 全量抽取
全量,即将源系统的全部数据都抽取过来。这种抽取方式有一种好处,就是不需要跟踪自上次成功抽取以来的数据变化,不需要给源系统数据附加逻辑信息(譬如时间戳)。一般情况下,第一次抽取会采用全量抽取。
1.2 增量抽取
增量,只抽取某个事件发生的特定时间点之后的数据,即某个时间点变化的数据。往往源系统的数据量是非常庞大的,譬如一些c端的行为信息,那么采用全量抽取,会使得抽取的效率很慢,所以增量抽取是一种很好的手段。使用增量抽取,必须能够标识出特定时间点之后所有的数据变化,因为数据由源系统提供,那么常用的可以是在抽取逻辑上将时间戳提取出来,作为标识。增量抽取的技术,也常被称作“变化数据获取”,简称“CDC”。常用的有四种手段:时间戳、快照、触发器和日志。
在很多数据仓库中,抽取过程并不含有任何变化数据捕获技术,其增量抽取的过程是这样的:把源系统中的整个表抽取到数据仓库过渡区,然后用这个表的数据和上次从源系统抽取的表数据做对比,从而得到变化的数据。当然,这种做法会给数仓处理增加负担,特别是数据量特别大的时候。
2、物理抽取
依赖于选择的逻辑抽取方法,以及能够对源系统所做的操作和所受的限制,可以有两种物理抽取机制:联机抽取和脱机抽取。
2.1 联机抽取
数据直接从源系统抽取。
2.2 脱机抽取
数据不从源系统直接抽取,而是从一个源系统以外的过渡区抽取。过渡区可以是已经存在(如数据库备份文件、重做日志或者归档日志),也可以是抽取程序自己建立。
三、T:转换
数据从操作型源系统获取之后,需要多种转换操作,如统一数据类型、处理拼写错误、消除数据歧义、解析为标准格式等。数据转换一个重要的功能是数据清洗,目的是只有“合规”的数据才能进入目标数据仓库。转换操作是ETL最复杂,最繁琐的环节,占据整个ETL50%时间,由于篇幅有限,这里不详细说明。
四、L:加载
ETL的最后步骤是把转换后的数据装载进目标数据仓库,需要关注的两个问题:
1、数据的装载效率
要提高装载的效率,可以从下面几个方面入手:
2、一旦装载中途失败,如何再次重复执行装载过程
需要再次执行装载过程,一般有两种情况。
一种情况是,数据装载过程中,可能由于各种原因而失败,比如源表与目标表的结构不一致,而这时已经有部分表装载成功。那么,在大数据情况下,如何只装载失败的部分数据,是一个不小的挑战。这种情况下,解决方案是记录失败点,并在装载程序中处理相关逻辑。
另一种情况是,装载成功后,某些数据滞后了,会带来数据的更新或新增,对于这种情况,是先删除再插入,或者使用replace into、merge into等类似功能的操作。
(附上一张简单的关系图)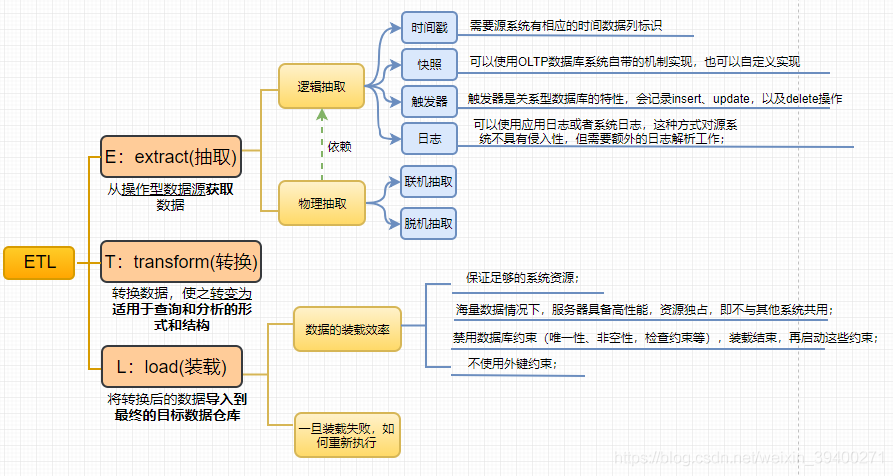
标签:删除 复杂 重做日志 效率 销售 目标 附加 两种 多个
原文地址:https://www.cnblogs.com/SysoCjs/p/11345156.html