标签:eve str 统计分析 协议 管理 能力 执行 算法 alt
随着IT基础设施的云化,应用运行环境的容器化,系统架构的微服务化,越来越多的企业不得不引入更多的工具、更复杂的流程和更多的运维人员,来提升IT系统管理的精细度,但新的问题也随之而来。如何抑制告警风暴?如何保障重要告警不漏不丢?如何快速的甄别根因告警?如何沉淀告警处置经验?如何快速恢复业务运行? 这些都是每一个运维团队在工作中面临的最棘手的问题。到底是什么原因导致如此频发的告警风暴,给告警管理带来如此之高的复杂度呢?
应用系统间关系更加紧密
完成一笔业务往往需要跨越多个应用系统,应用调用链路上每个IT单元的问题,都有可能导致业务故障。系统中任何一个监控对象的告警都可能引发其他多个相关策略的告警,海量告警的相关度高达90%,也就是说90%的告警都是可以被归因到一个根源告警上。
告警策略设置难以找到平衡点
过高的告警阈值,容易漏掉系统运行故障;而过低的告警阈值,又会带来大量的无效告警,影响运维团队的工作效率。同样,告警检查周期的长短设置也存在类似的问题。往往运维团队为了不落掉告警,不得不提升告警的灵敏度,而这样告警重复率可能高达60%。
告警响应的及时性不高
多个人参与同一类告警的处理是目前大部分运维团队的工作模式,少则2-3人,多到9-10人,同一个告警会被推送到多个运维人员的手中。但是,通常在一些特殊时段只有一个值班员负责处理告警,这就给其他团队成员生活带来了巨大的干扰。因为缺少高效的分派和排班管理机制,加上大量重复的无效信息,这将会在一定程度上造成告警处理的延时和遗漏,从而引发告警风暴。
为了提升 IT 系统的运维管理效率,最大程度降低运维管理难度,AIOps 成了技术发展的必然选择。而告警管理作为AIOps的重要组成部分,上接监控工具,下接ITIL流程和自动化平台,是整个运维监控体系中承上启下的中枢。告警管理能力的高低成为了掣肘IT运维SLA(Service-Level Agreement,服务等级协议)的关键。
为了帮助企业更加量化的评估当下告警管理能力,明确告警管理平台建设目标和演进路线,我们将告警管理能力分为5个级别,整合出了“告警管理能力成熟度模型”,每个级别按照管理能力的不同程度,呈现递进的方式,高级别内容包含低级别内容。
我们的运维团队为了尽可能全面的覆盖IT系统的各个环节,不得不引入多个监控工具,不同的监控工具会产生数以万计的告警,这些告警都需要去分析、优先级甄别、并执行预案操作。随着时间的推移,可能是数十万、百万的告警事件需要被关注。
因为缺少了告警的集中管理和分派,不同对象的告警信息在运维人员间无序的传递,导致告警响应和处理效率低下。严格意义上来说,这个级别的成熟度还谈不上管理。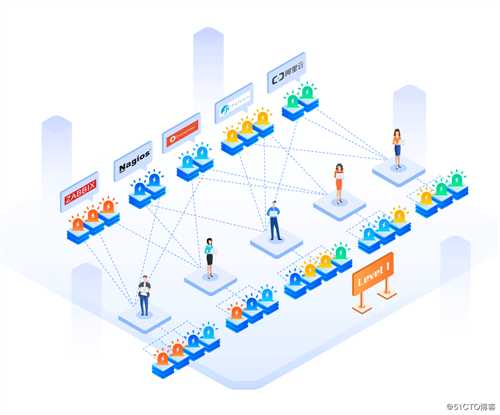
越来越多的运维团队已经意识到了无序所带来的高额的管理成本和低下的故障处理效率。据统计,有超过20%的企业通过运维开发团队自建或利用第三方平台来进行告警的统一管理。
将不同监控工具或系统产生的告警接入到统一管理平台之中,并能够基于一定的规则对告警进行去重,过滤和压缩。这个级别的管理能力成熟度打破了监控工具的边界,以业务或场景为视角,根据运维团队的职能分工,如按照业务或者IT架构分工,将告警分门别类,结合更加高效的协作工具,如钉钉、企业微信、Slack等,在一定程度上提升了故障处理的效率。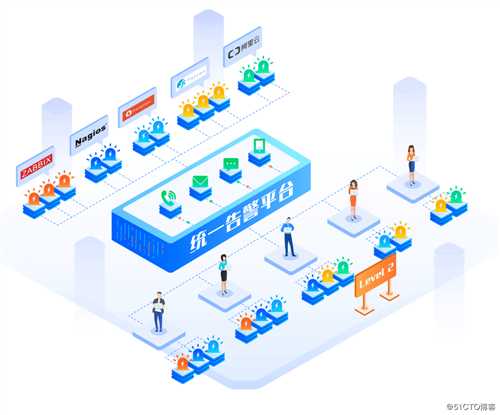
业务在变,监控需求也在变,因为告警去重规则的死板而带来的问题不言而喻。通过大量的数据统计分析,只有不到40%的告警能够通过规则进行压缩。
随着人工智能技术的不断发展,特别是NLP(Natural Language Processing,自然语言处理)技术的成熟,针对告警这类文本数据的分类、聚类、模式发现算法,成为了有效抑制告警风暴,提升告警有效性的主要手段。可以通过时间相关性、文本相似度、故障溯因图、CMDB(Configuration Management Database,配置管理数据库)等手段,对海量数据中相似、相关的告警进行聚合。针对告警中的异常、新奇等重要信息,通过时间熵和内容熵进行标识,越是不频发、无规律、严重度高的告警越需要被重视,熵值越大信息越重要。告警智能管理将极大减少告警处理量,提升告警故障分析效率。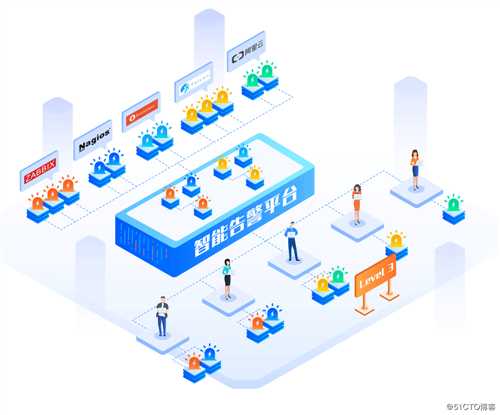
根因定位一直是告警管理皇冠上的那颗明珠。由于告警的传递性和多面性,要在众多错综复杂的信息中迅速定位根因对所有运维团队来说都是巨大的挑战。
关于根因定位的探索大致可以分为以下三个方向,一是基于动态获取的系统调用链路和承载关系,并结合时间相关性开展根因分析;二是基于CMDB构建一个实时反映系统环境的配置项和关系二元组群,通过告警在其中的投射关系进行根因定位;三是建立全面覆盖IT运维管理全域的实体、属性、关系三要素库,再运用知识图谱算法获得根因告警。当然不论是哪一种方案,都需要建立在对IT系统架构的深度学习和理解基础之上,才能真正做到明辨真伪,洞悉根因。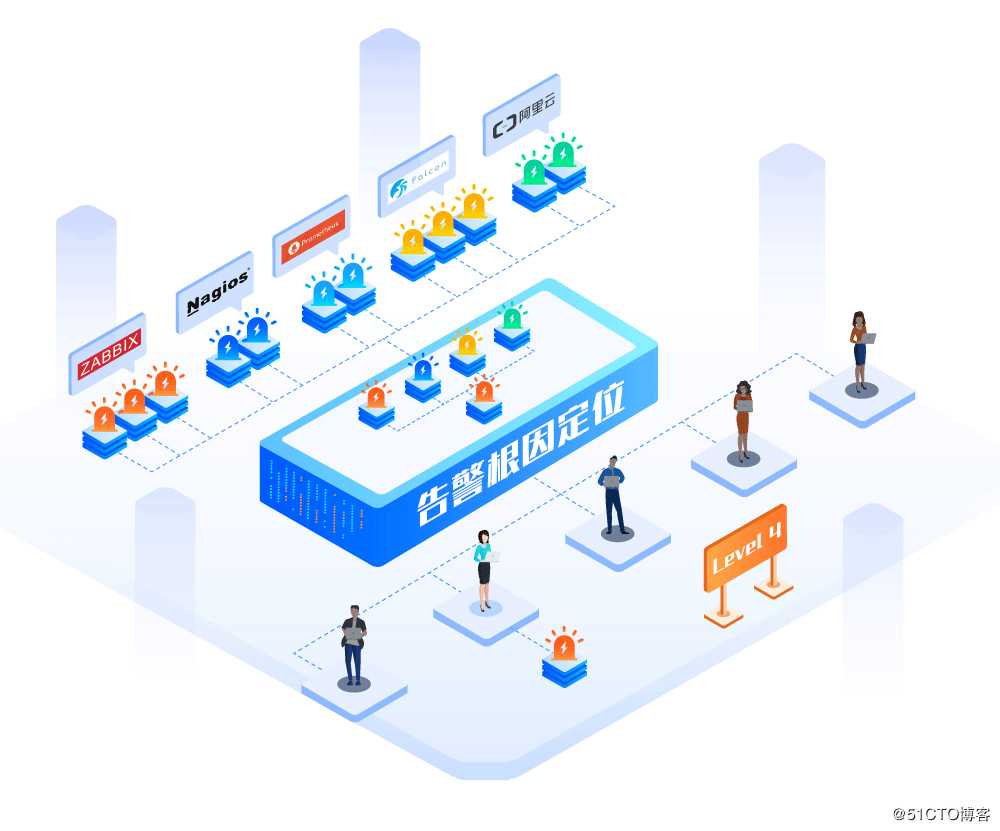
告警自愈是一套完备的故障自动化处理流程,通过打通监控工具、告警平台、任务调度平台、CMDB、ITIL等相关系统,实现从告警接收,根因定位,规则匹配,脚本执行,故障恢复,人工确认,最后到告警恢复,真正实现告警的全生命周期管理。
除了Level 4中根因告警定位这个技术难点外,整个告警自愈过程还有另一个关键点,就是告警故障知识库的建立,这是日常运维工作经验的积累和沉淀,也是故障恢复方案的基础。但这也恰恰是我们很多企业的软肋,大量的故障处理经验都存在于运维人员各自的大脑中,日常中更多的依靠个人能力去排查和恢复故障。随着运维人员的流动,这些最为宝贵的资产也随之流失,这使得一个重复故障的处理也需要进行重新分析,不必要的拉长了故障恢复时间。
告警自愈能帮助运维团队第一时间查明问题原因,实现故障的快速修复。同时还能帮助运维团队沉淀问题处置经验,防范潜在风险,最终形成系统运维的闭环管理。
目前,越来越多的企业在告警管理领域展开探索,并且在告警风暴抑制上取得了一定的成效。睿象云的智能告警平台也在帮助不同行业的运维团队解决告警集中和智能管理的问题。运维之路,艰苦漫长,告警的持续改进也不能一蹴而就,相信随着技术的发展和经验的积累,告警管理必将迎来跨越式发展的盛夏。我们也希望通过大家对告警管理能力成熟度模型的探讨和实践,引领我们共同步入无人值守这个运维终极目标。
标签:eve str 统计分析 协议 管理 能力 执行 算法 alt
原文地址:https://blog.51cto.com/14429589/2429078