标签:没有 因此 tor rda ace can size 随机 dataset
Torch中有一种整理你数据结构的东西:DataLoader,它能够包装你的数据,并且进行批训练。
一:相关操作
1:包的导入:
import torch.utils.data as Data
初始数据:
x = torch.linspace(1 , 10, 10)
y = torch.linspace(10, 1, 10)
2:包装数据类:
# 先转换成 torch 能识别的 Dataset #torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y) #以前的版本 torch_dataset = Data.TensorDataset(x,y) #现在的版本这样就行了
3:加载数据:.DataLoader
loader = Data.DataLoader( dataset = torch_dataset, #数据集 batch_size = BATCH_SIZE, #每次读取的大小 shuffle = True, #是否随机打乱 num_workers=2, # 多线程来读数据 )
二:批训练:(源码)
#-*-coding:utf-8-*- #批数据训练 BATCH_SIZE = 5 import torch import torch.utils.data as Data x = torch.linspace(1 , 10, 10) y = torch.linspace(10, 1, 10) # 加入“数据集”里面 torch_dataset = Data.TensorDataset(x,y) loader = Data.DataLoader( dataset = torch_dataset, batch_size = BATCH_SIZE, shuffle = True, #是否随机抽样 num_workers=2, # 多线程来读数据 ) if __name__ == ‘__main__‘: #没有这一行可能会报错:“he "freeze_support()" line can be omitted if the program” for epoch in range(3): for index,(batch_x,batch_y) in enumerate(loader): # 打出来一些数据 print(‘Epoch: ‘, epoch, ‘| Step: ‘, index, ‘| batch x: ‘, batch_x.numpy(), ‘| batch y: ‘, batch_y.numpy())
2.结果:
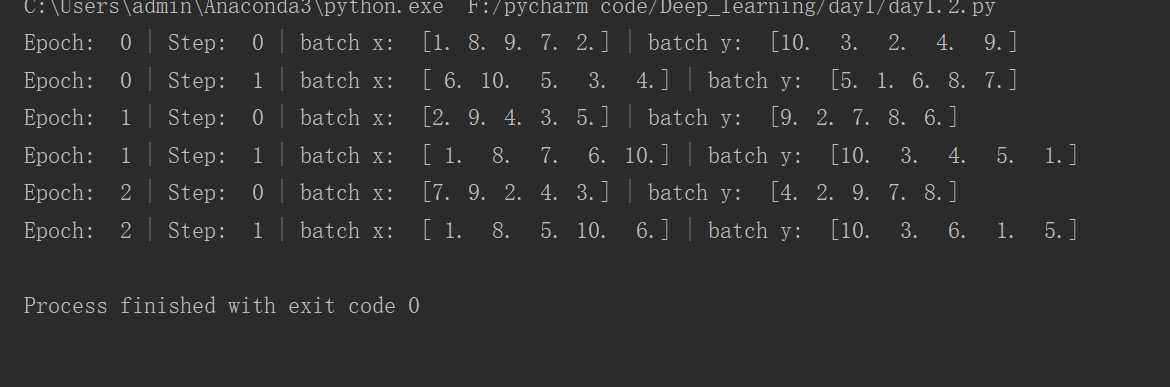
注:
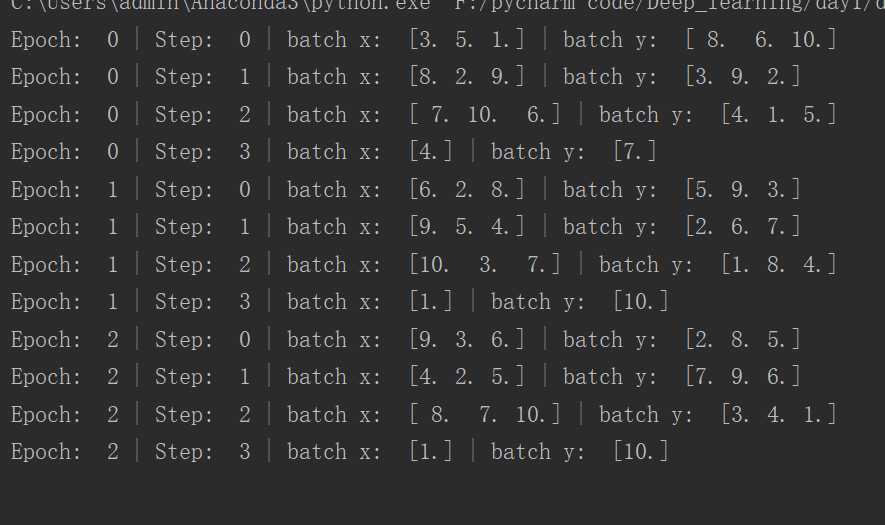
上面这个图为BATCH_SIZE = 5时的结果,原因在于,当数据大小和每次话费大小不是整数倍时,最后一次划分就是剩下的,不一定就是BATCH_SIZE这么大。
比如第一张图:size为5,数据有10个,因此两次,每次五个。第二张图,size为3,数据有10个,所以分为四次,且最后一次只有一个。
标签:没有 因此 tor rda ace can size 随机 dataset
原文地址:https://www.cnblogs.com/carrollCN/p/11345945.html