熵是随机变量不确定性的度量,不确定性越大,熵值就越大;若随机变量退化成定值,熵为0。均匀分布是“最不确定”的分布
假设离散随机变量X的概率分布为P(x),则其熵为:
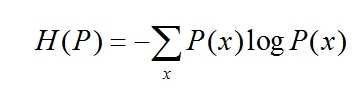
联合熵和条件熵
两个随机变量的X,Y的联合分布,可以形成联合熵,用H(X,Y)表示
条件熵H(X|Y) = H(X,Y) - H(Y)
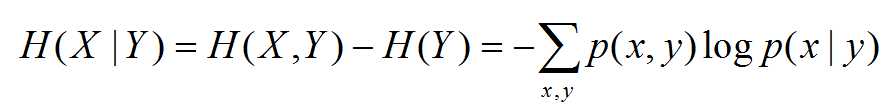
相对熵与互信息
设p(x),q(x)是X中取值的两个概率分布,则p对q的相对熵是:
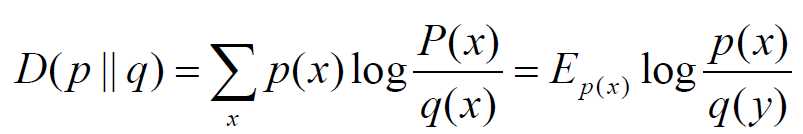
两个随机变量X,Y的互信息,定义为X,Y的联合分布和独立分布乘积的相对熵。
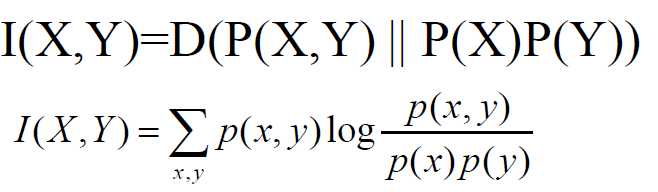
最大熵原理是统计学的一般原理,也是概率模型学习的一个准则。最大熵原理认为,学习概率模型时,在所有可能的概率模型中,熵最大的模型是最好的模型。
2.最大熵模型
2.1最大熵模型的实例(参考[1])

在英汉翻译中,take有多种解释例如上文中存在7中,在没有任何限制的条件下,最大熵原理认为翻译成任何一种解释都是等概率的。
![]()
实际中总有或多的限制条件,例如t1,t2比较常见,假设满足
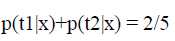
同样根据最大熵原理,可以得出:
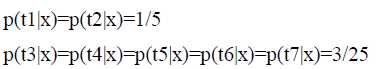
实际的统计模型中,还需要引入特征提高准确率。例如take翻译为乘坐的概率小,但是当后面跟着交通工具的名词“bus",概率就变得非常大。
用特征函数f(x,y)描述输入x,输出y之间的某一个事实,只有0和1两种值,称为二值函数。例如:
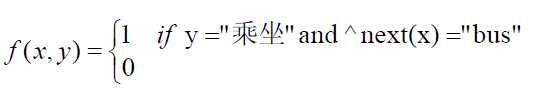
最大熵模型根据最大熵原理在类似上面的特征限制下选择最优的概率分布。
2.2 最大熵模型的数学推导(参考[2])
对于给定的训练数据集T={(x1,y1),(x2,y2),(x3,y3)...(xn,yn)}以及特征函数fi(x,y),i=1,2,3...n,最大熵模型的学习等价于约束的最优化问题:
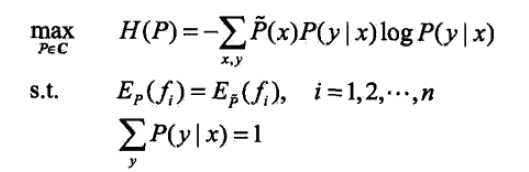
引入朗格朗日算子W,定义拉格朗日函数L(P,w)
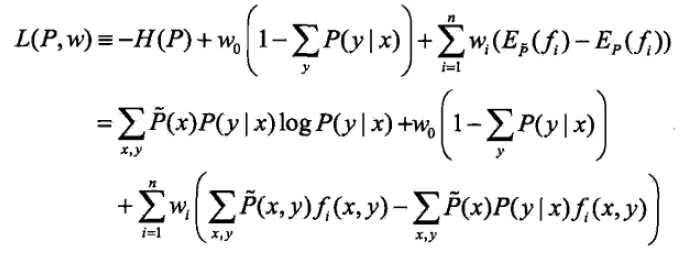
最优化的原始问题:
![]()
对偶问题是:
![]()
由于L(P,W)是P的凸函数,原始问题的解与对偶问题的解是等价的。这里通过求对偶问题的解来求原始问题的解。
第一步求解内部极小化问题,记为:
![]()
通过微分求导,得出P的解是:
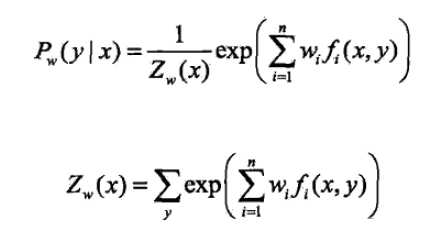
第二步求外部的极大化问题:
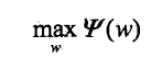
最后的解记为:
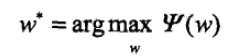
第三步可以证明对偶函数的极大化等价于第一步求解出的P的极大似然估计,所以将最大熵模型写成更一般的形式.
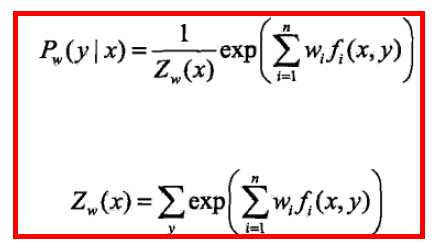
2.3 最大熵模型学习算法
由模型的数学推导2.2知道,最大熵模型的学习最终可以归结为以最大熵模型似然函数为目标函数的优化问题。这时的目标函数是凸函数,因此有很多种方法都能保证找到全局最优解。例如改进的迭代尺度法(IIS),梯度下降法,牛顿法或拟牛顿法,牛顿法或拟牛顿法一般收敛比较快。
《统计学习方法》中有非常详细的使用IIS优化目标函数的过程。
算法的推导比较麻烦,但思路是清晰的:

References:
[2]《统计学习方法》.李航
[3]一文搞懂最大似然估计