标签:style blog http color for strong sp 数据 div
场景:
让我们来玩个游戏, 假设我们是懒得"无可救药"的坏学生, 就是死活不做题, 一根筋的要走"抄袭"路线.
How to do it?
让我们来简单枚举下各自的方式:
1). copy/paste
老师: 呵呵, 也只能呵呵了
2). 名称替换 (变量名/函数名)
老师: 能有点创意不?
3). 代码位置置换
老师: 丢人.....
4). 添加注释, 调整代码书写形式
老师 (推推鼻梁上的眼镜): 有点意思 .....
5). 简单重构 ( 函数合并和拆分 )
老师 : 有进步, 看来还有救.......
就此打住, 总之抄袭方法, 没有最好, 只有更好, 众人拾材火焰高, oh yeah.

需求分析:
基于上述的场景, 我们把代码抄袭过程视为一次transform, 转换前后的代码应该是相似的.
那么代码抄袭检测系统的基本功能, 列举如下所示:
1). 相似代码检测的准确率高
定义相似度算法, 能准确反映出代码之间的相似程度, 通过上述的抄袭方式转换的代码, 彼此之间的相似度高
2). 相似代码对比的友好展示效果
相似代码在两两对比时, 能通过染色+高亮的方式来强调突出可疑的相似区域, 而不需人肉对比了.
3). 快速增量
代码检测需快速响应, 在大数据量代码仓库下的情况, 依旧能快速检索.
难点解析:
1). 相似度如何描述和定义
不可否认, 自然语言和机器所能理解的语言, 存在着天然的鸿沟. 那如何从机器的角度去理解语言? 相似文本的检测算法, 是否可以套用到代码检测上? 好像不行, 简单的词袋模型, 并不能表述代码的特征(后续的文章详细阐述). 那代码的特征是什么, 它在那里?
2). 相似代码对比的友好性
这个似乎简单一点, 但它绝不是vimdiff那么简单
3). 在大数据量的前提下, 如何支持快速检索
显然相似检索时, 是不会遍历所有的代码做相似计算, 然后求出top n的.
例如, 我们假设相似算法计算耗时10ms, 当代码集数量为10, 遍历一边耗时为100毫秒, 当如果代码集数量达到1万时, 需要耗时为100秒, 这显然无法接受.
当然我们可以大致猜测的实现思路, 分如下两步骤
(1). 快速检索出小数据集的候选集
(2). 然后精确的计算该候选集的相似度, 并做top n排序
如何去支撑该实现, 又该选用存储方案, 这是我们需要所面临的问题.
而这一切, 所有的关键就是特征, 究竟代码的特征是谁? 从哪里来? 将要去哪里?
先卖个关子,请期待后续的文章.
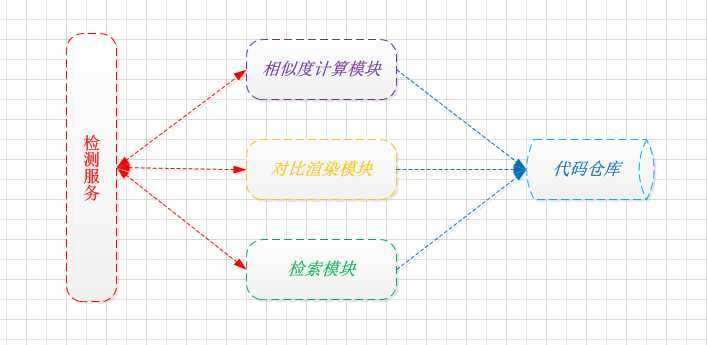
后续:
不太清楚, 自己能写几篇, 下一篇文章会重点介绍代码相似度的定义和计算, 敬请关注.
标签:style blog http color for strong sp 数据 div
原文地址:http://www.cnblogs.com/mumuxinfei/p/4043045.html