标签:gif sed 模块 mon str time() 开启 yield 感知
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的
1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
2. 单线程内开启协程,一旦遇到io,自己通过代码控制切换,以此来提升效率;给操作系统感觉这个线程没有没有任何的IO(!!!非io操作的切换与效率无关)
1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
2. 单线程内就可以实现并发的效果,最大限度地利用cpu
1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
1.必须在只有一个单线程里实现并发 2.修改共享数据不需加锁 3.用户程序里自己保存多个控制流的上下文栈 4.附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
1.当任务是IO密集型的情况下 提升效率
2.当任务是计算密集型的情况下 降低效率
单纯的切换(在没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度
1.串行执行 需要时间:3.316875696182251 import time def func1(): for i in range(10000000): i+1 def func2(): for i in range(10000000): i+1 start = time.time() func1() func2() stop = time.time() print(stop - start) 2.基于yield并发执行 需要时间:3.3223798274993896 import time def func1(): while True: 10000000+1 yield def func2(): g=func1() for i in range(10000000): # time.sleep(60) # 模拟IO,yield并不会捕捉到并自动切换,不会执行 i+1 next(g) start=time.time() func2() stop=time.time() print(stop-start)
from gevent import monkey;monkey.patch_all() # 由于该模块经常被使用 所以建议写成一行 from gevent import spawn # spawn 检测某个任务又没有IO import time """ 注意gevent模块没办法自动识别time.sleep等io情况 需要你手动再配置一个参数 """ def heng(): print("胡歌") time.sleep(2) print(‘帅‘) def ha(): print(‘霍建华‘) time.sleep(3) print(‘皮‘) def heiheihei(): print(‘彭于晏‘) time.sleep(5) print(‘萌‘) start = time.time() g1 = spawn(heng) g2 = spawn(ha) # spawn会检测所有的任务,g1,g2,g3,三者之间一直在快速的切换 g3 = spawn(heiheihei) g1.join() g2.join() g3.join() # 因为g3睡的时间最长,所以结果为5s print(time.time() - start)

from gevent import monkey;monkey.patch_all() import socket from gevent import spawn server = socket.socket() server.bind((‘127.0.0.1‘,8080)) server.listen(5) def talk(conn): while True: try: data = conn.recv(1024) if len(data) == 0:break print(data.decode(‘utf-8‘)) conn.send(data.upper()) except ConnectionResetError as e: print(e) break conn.close() def server1(): while True: conn, addr = server.accept() spawn(talk,conn) if __name__ == ‘__main__‘: g1 = spawn(server1) g1.join()
import socket from threading import Thread,current_thread def client(): client = socket.socket() client.connect((‘127.0.0.1‘,8080)) n = 0 while True: data = ‘%s %s‘%(current_thread().name,n) client.send(data.encode(‘utf-8‘)) res = client.recv(1024) print(res.decode(‘utf-8‘)) n += 1 for i in range(400): t = Thread(target=client) t.start()
一共有五种IO Model:
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路复用
* signal driven IO 信号驱动IO
* asynchronous IO 异步IO
由signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种IO Model。
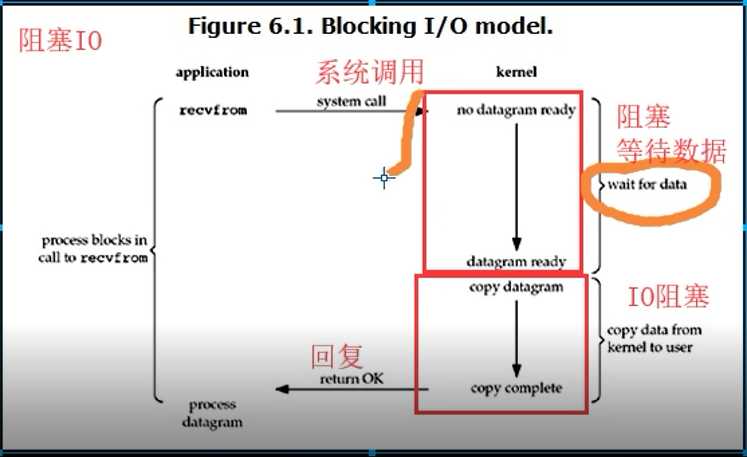
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。
而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
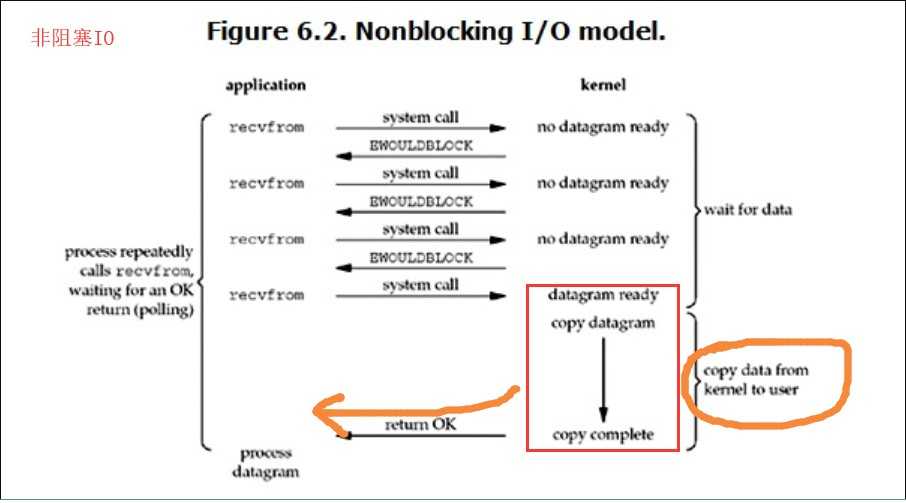
从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是用户就可以在本次到下次再发起read询问的时间间隔内做其他事情,或者直接再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存(这一阶段仍然是阻塞的),然后返回。
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
所以,在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。
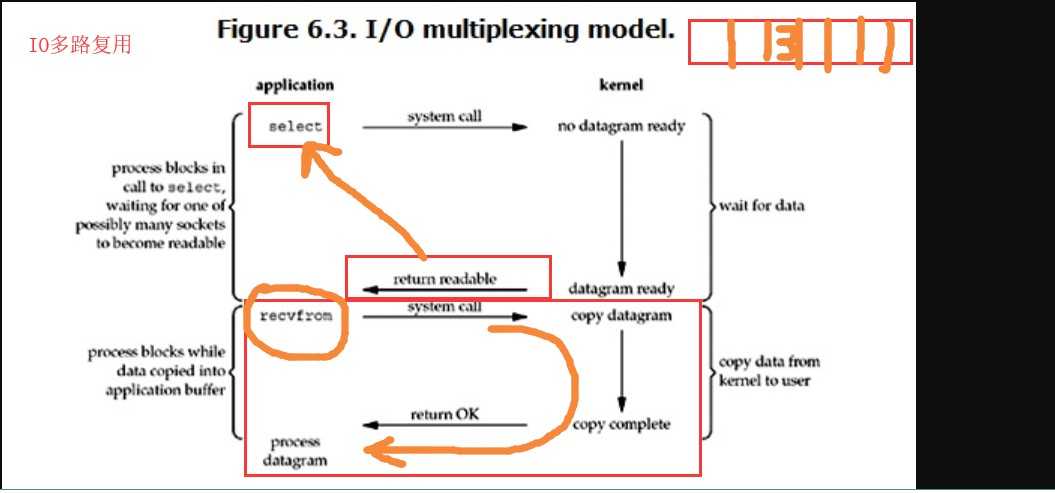
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
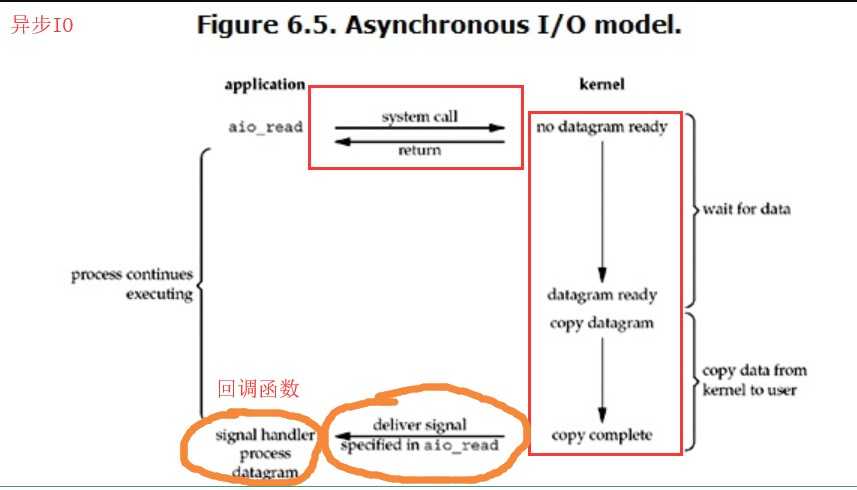
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
标签:gif sed 模块 mon str time() 开启 yield 感知
原文地址:https://www.cnblogs.com/xiongying4/p/11359042.html
