标签:log文件 bullet 获取 负载 ati -o define 数据读取 word
hadoop dfs -ls file:/// (最后一个/表示本地文件系统的根目录)
HDFS的弱点:
配置hdfs块的大小 hsfs-site.xml
冗余性
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
值越多,冗余性越好
分块的好处:
1.分块可以提高扩展性,比如存储在不同的磁盘或者机器
2.实现元数据和数据的分开存储
3.容错性高
NameNode
SecondaryNamenode
将
FSImage
EditLog
合并
?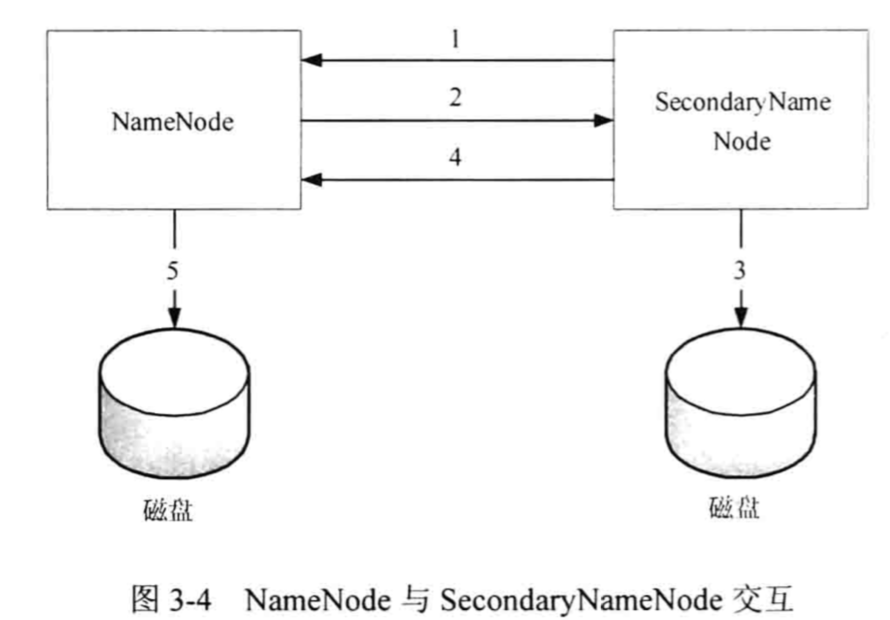 ?
?
- SecondaryNamenode 引导 NameNode 滚动更新 EditLog文件,并开始将新的内容写入Edit Log.new
- 复制FSImage和Edit Log文件
3) 合并FSImage和Edit Log并存入磁盘
4)送回NameNode
5) Namenode将 新的EditLog.new命名为Edit Log
3.1.3 HDFS容错
NameNode 检测与 DataNode 之间是否有心跳机制,如果未收到,则DataNode 上的数据被认为是无效的。 NameNode会检测是否有文件块的副本数目小于设置值,如果小于就自动开始复制新的副本到其它NameNode节点。
计算校验和,若不一致,从其它DataNode上获取改文本
- Namenode 伤的FSImage和Edit Log文件
SecondaryNamenode用于备份
文件被安置于/trash中,由hdfs-site.xml决定。fs.trash.interval,单位为秒
HDFS读取文件和写入文件
? ?
?
将数据存在一个节点之中,数据复制所需要的带宽最小;
将数据存在一个节点之外,将会消耗更多的带宽。
而存在一个节点中,节点发生故障的话,数据更容易丢失
数据读取
?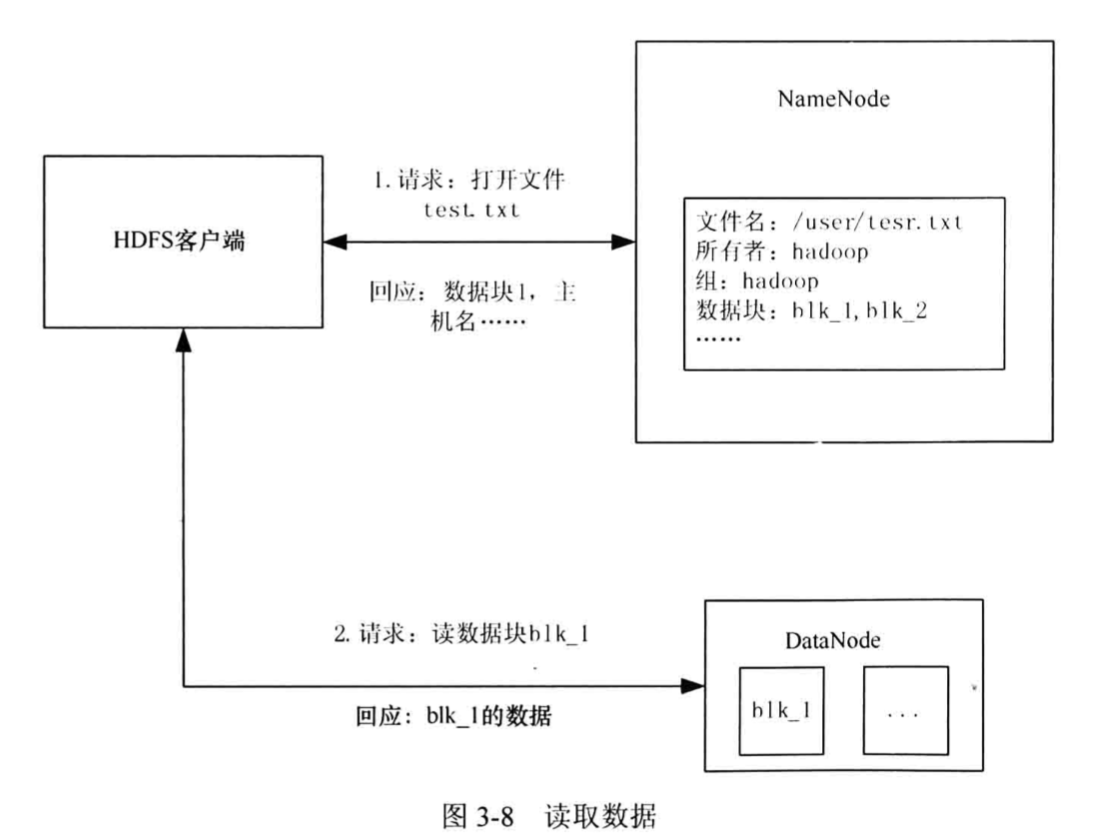 ?
?
- /usr/test.txt请求,打开文件test.txt.回应,数据块1,主机名......
- 请求:读数据块h1k_l
- 回应:blk_1的数据
写入数据
?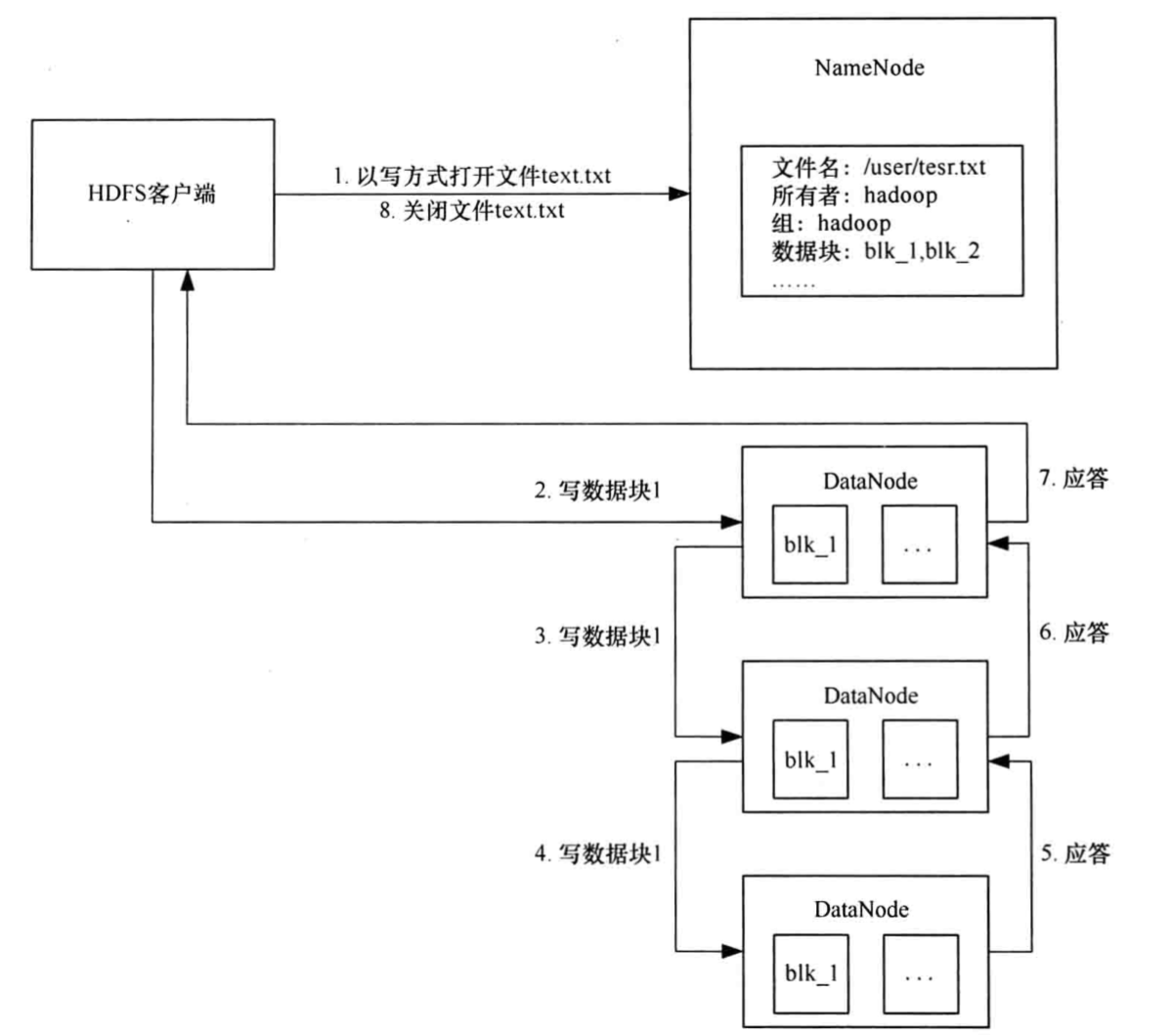 ?
?
HDFS客户端通过API发送请求,当符合权限时,数据会被分成数据包,并将数据包保存在内存队列中
建立多个复制管道,每个复制管道独立确认是否写入磁盘
数据完整性
通过校验和
HDFS会将数据和校验和发送到DataNode组成的复制管道中,最后一个DataNode检验校验和是否一致,如果异常,则报错
HDFS读数据时,也会计算校验和
3.3 如何访问 HDFS
当成lab,手动尝试HDFS
————————————————————————————————————————
第四章 分而治之的智慧:MapReduce
Mapreduce运行环境
?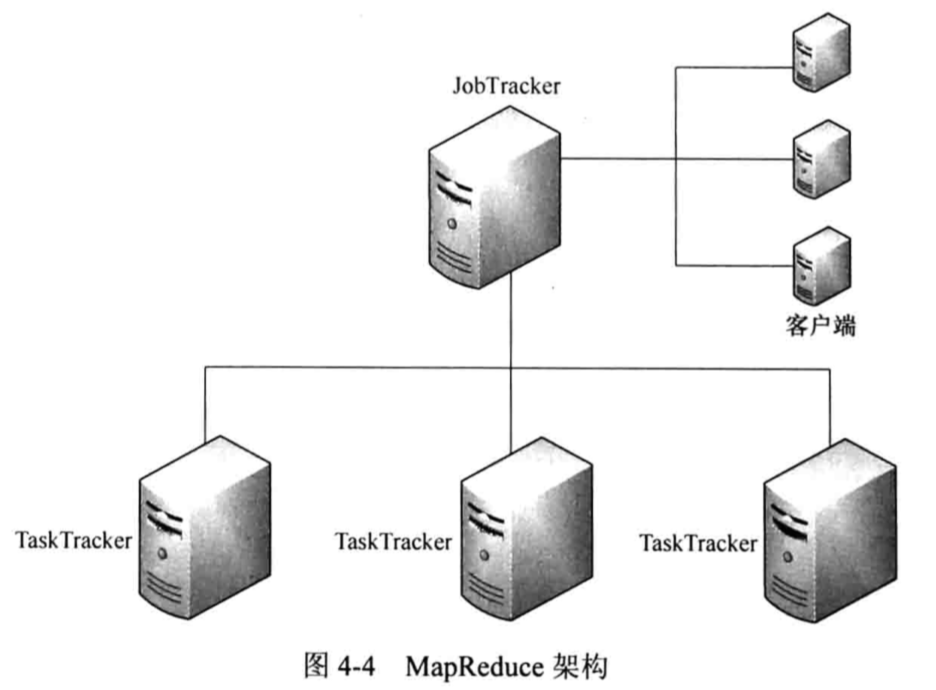 ?
?
4.2.2 编写WordCount
mapreduce框架主要运用快排和归并排序
4.4mapreduce的工作机制
hadoop基础
标签:log文件 bullet 获取 负载 ati -o define 数据读取 word
原文地址:https://www.cnblogs.com/zhichun/p/11361259.html