标签:随机梯度 需要 keep 概率 最大 趋势 near 情况下 框架
目录
回顾下之前学习的内容。人工神经网络里面有重要的三条内容,一个是加和,加function,把前面的输入所对应模型的权重相乘相加,第二经过一个非线性变化,第三signal out输出。如果把function设置为Sigmoid函数,它相当于是一个逻辑回归。
 ?
?
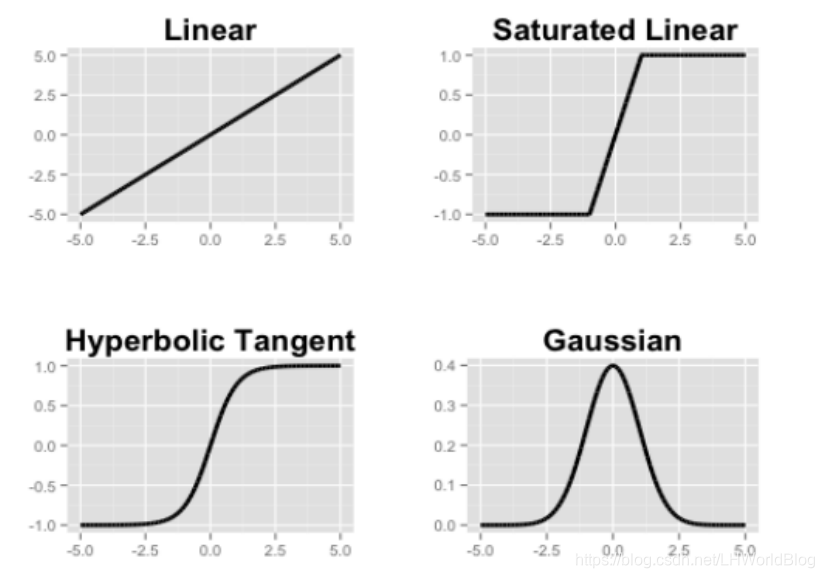
第一个叫01函数,它要么就是0,要么就是1;
第二个叫Sigmoid函数;
 ?
?
可以是linear;也可以是saturated linearcs饱和的线性;也可以用gaussian激活函数。也可以是Tangent,它是一种比较常见的激活函数,通常写Tanh,它其实也是一个S曲线,跟Sigmoid函数S曲线有一点区别在于它的y轴是从-1到+1之间的,Sigmoid函数y轴是从0到+1之间的。如果是Sigmoid函数的话,它的输出一定是大于0的,有些时候我们不希望看到输出大于0的,希望它给一个负反馈,这样的话就会用Tanh,因为它有负的区间段;
哪一个方式都行,常用的就三种,第一种是ReLU,第二种是Sigmoid函数, 第三种是Tanh。一般的框架都会把这三种的公式给它进行封装,我们只需要传不同的参数就可以去使用不同的激活函数。
再看下拓扑结构:
 ?
?
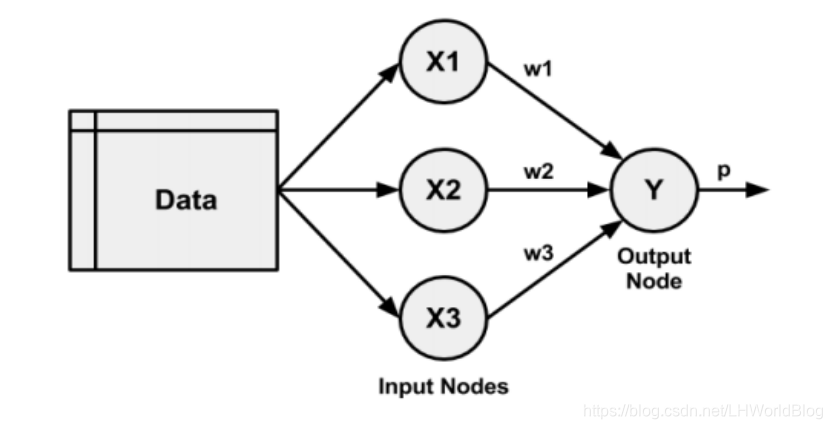
这就是一个单层的网络拓朴,比方我们有一个Data数据x1……xn有n个维度和相对应的y,中间的X1,X2,X3相当于Data数据里的每一列,对应着每个维度。往后去输入数据的时候,是一行行的获取样本数据,进行一个正向传播(从输入到输出的计算),以此类推,把所有数据都拿出来进行正向传播。第一行样本和权重相乘相加,再经过function函数计算,得到?1,然后依次类推,得到?1,?2……?m样本的预测结果,再根据真实结果,算一下Loss损失。
如果把这里的y写成∑f,f是Sigmoid函数的话,就是一个逻辑回归。前面的输入层是不需要任何加和和激活的,直接把数据结构往下游去传递,在输出层会有加和以及function函数输出。单层网络,只有一个输入层,输出层,它并不能体现出神经网络的优点。
如果function函数是Sigmoid函数,这样一个逻辑回归是做二分类的,还是来做多分类的?二分类,因为它给了一个P概率,如果概率跟0.5进行比较,>0.5就是1这个类别,<0.5就是0这个类别。
逻辑回归也可以做多分类,它本质上是把多分类变成多个二分类来做,那么能不能用神经网络图来表达逻辑回归做多分类?
现在画框的图就是一个二分类,再来几个就是多分类,在输出层再加一个神经元,把前面的x1,x2,x3传给它,下面再画一个神经元,把前面的x1,x2,x3传给它。现在是一个全连接,因为两点之间全部都连接到一起。
每个结果y都会对应一个输出概率P,假如做的是个三分类的问题,第一个节点是来分第一个类别的,以此类推P1,P2,P3,最后逻辑回归看P1、P2、P3谁的输出最大,它就是属于哪个类别。
逻辑回归来做多分类,它本质上相当于是把第一层的输入和第一个输出的节点做一个二分类;然后接着它再把前面输入跟第二个做一个二分类;然后把前三个输入跟第三个输出节点再来作一个二分类,它相当于回归做了三个二分类模型。那么逻辑回归把多分类的问题当做二分类的问题来做,它们每一个分类器的w参数之间互相影响吗?
它们之间互相不影响,比如X1发出的第一根绿线,它不会把这根绿色线的结果传给w1,w2,w3,另外一个绿色线也不会传给其它的二分类模型,所以逻辑回归做多分类转为二分类问题时,每个模型之间是互相不影响的,是独立算的。
那么P1+P2+P3=1吗?事实上等于1概率不大,因为它们之间互相不影响,比如P1=0.8,P2=0.9,P3=0.6,那0.9最大,就分到第二个类别里面,它们互相之间不影响。
生成的另外两个神经元是新构建另外的w1,w2,w3吗?是,比如红色的节点,它就会有三个w值,w4,w5,w6;绿色的节点,它还会有三个w值,比如w7,w8,w9,每个独立的二分类模型,都会去算对应的w参数。
它分二分类的话,它都能跟什么样的那种类型区分加上里面,就是说什么样的就是混合类型的话,什么叫混合类型? 不够。资格跟我讲。这跟高速广东模型没关系。这跟高斯混合模型没关系,这个就是来做一个多分类的问题,
如果是三分类,相当于如果逻辑回归来做三分类,现在力量有三个输出节点。如果来说N分类上地方有N个输出节点用来做分类,那一个输入点就够了。明白这意思吗?那么在这里面换句话说,
如果逻辑回归来做多分类,如果没有截距的话,它至少得要算9个参数;如果考虑截距的话,每一个节点会有一个w0,也就是有12个w要算。
这里面的X直接输入往后传递输出,Y要先加和,在经过function变化,如果做多分类,function变化全部都是Sigmoid函数,我们称为浅层的模型,只有一个输入层,一个输出层。
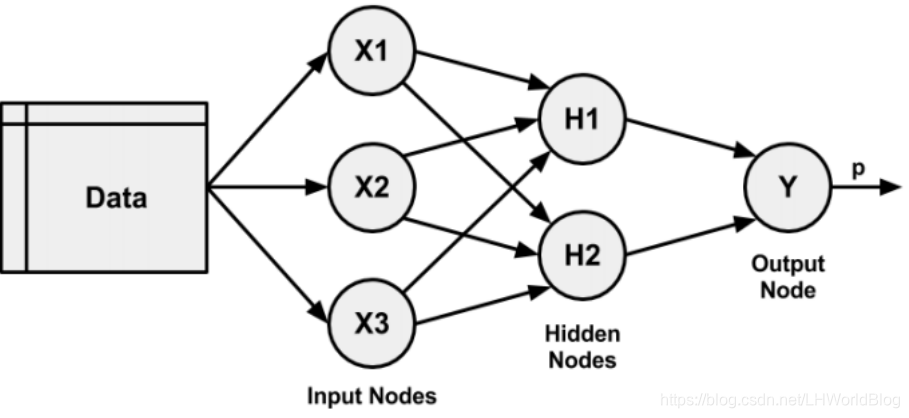
真正的神经网络绝对不只有输入输出两层,前面的输入层的节点叫做输入节点,输出层上的节点叫做输出节点,中间一层上的节点叫做隐藏景点,这一层叫做Hidden layer,它用了2个隐层节点。
除了输入层,隐藏层一定是神经元,神经元就一定有加和和非线性变化,输出层如果做分类,有加和和非线性变化;如果做回归,不一定。
我们先看下拓扑图:
 ?
?
什么是非线性变化?那什么是线性变化?
如图:
 ?
?
如果y随着x成一个线性的变化,这个就称为线性变化。
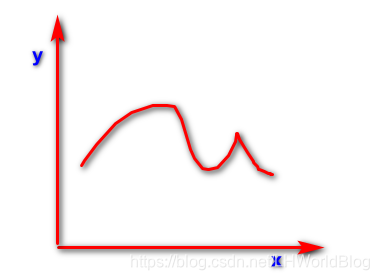
如果换一个曲线,那么y随x就不成一个线性的变化如图:
 ?
?
就是非线性的变化。x可以任意的增加,只要不是直线的变化,就说它是非线性的。x的维度上升比如x2,x3都是非线性变化的。 如果是多维,比如y=x0*w0+x1*w1+x2*w2,其中x0*w0和y是成线性变化,x1*w1也是,x2*w2也是,x都是一次方,就一定是线性变化的;如果它是0.5次方,0.4次方或者1.5次方,都是非线性变化。
最终的结果是一个加和,就是∑xi*wi,x是一次方,加和之后的结果和x变化是线性变化。
最后的结果只有一个神经元来决定,∑|f,如果function是Sigmoid函数,如果它做分类,就是一个二分类问题的。
还是用逻辑回归来举例:假如没有隐藏层的话,最后给出P概率的结果会受到3个维度的影响。
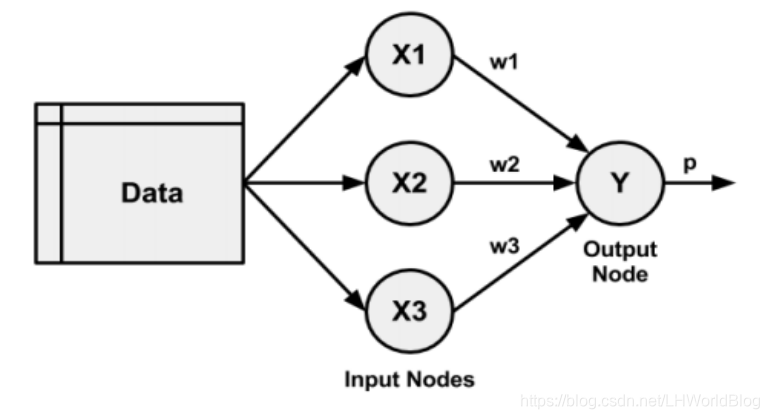 ?
?
如果加隐藏层,隐藏层里面只有两个隐藏节点,两个神经元,它的概率输出结果受到2个值的影响,一个H1的输出,一个H2的输出。
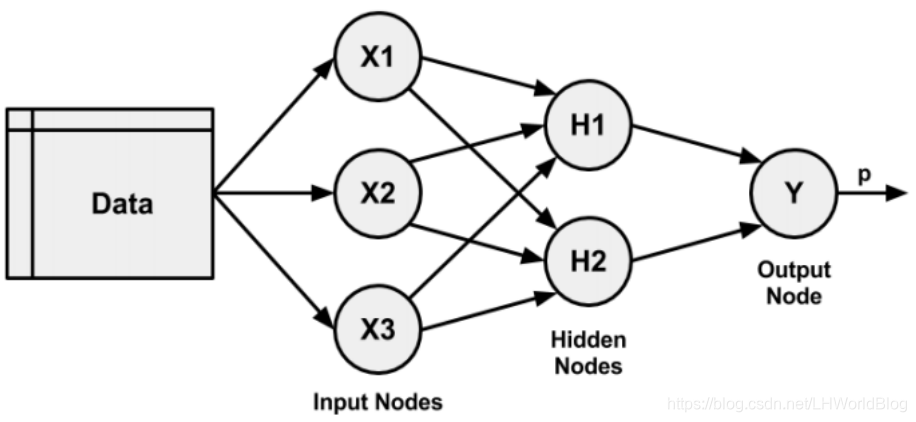 ?
?
之前我们的y受到三个节点的影响,由于我们加了隐藏层,里面有两个隐层节点,y就受到了两个维度的影响,它本质上做了一件降维。这个是神经网络里面自带的好处。
降维的好处是使得我们的计算复杂度变得更加简单,还有防止过拟和。因为有些时候开始的维度可能有些重要有些不重要, 经过了降维之后,它把重要的维度,对结果影响比较大的保留下来。
所以神经网络里,如果隐藏层的个数小于输入层的个数,相当于做了降维。
所谓的升维,说的是计算复杂度,降维本身也会有计算,做降维主要是看最后的结果,取决于前面因素有几个。H1,H2这两个维度的结果,是前面x1,x2,x3算出来的,对于y来说它考虑因素少了,实际上就是降维了。最前面输入的这一层可以叫预处理,相当于把原来这些维度数据进行了处理,给它变成了两个维度,然后再让y进行考虑。
总结下前面说的一堆废话~~~
逻辑回归,对于深度学习来说,就是一个神经元,前面是加和,后面是Sigmoid函数。对于逻辑回归,它的输入就是上一层的H1,H2两个,不再是X1,X2,X3三个了。从三个变两个的过程,相当于做了降维,把原来的数据进行了预处理,把它维度减少了。
如果隐藏层不是两个隐藏节点,五个隐藏节点,最后y进行判断的时候,它考虑因素从原来的三个变成了五个。第一个输入层和隐藏层中间的计算,相当于是升维。
神经网络里面网络拓朴,本质上是可以做降维和升维的,取决于怎么设置网络拓朴。
我们来看下如果拓扑结构表示实际中生活中的例子:
比如回家过年, 假设三个维度X1为玩火,X2为动刀,X3为上房,相当于是有一个表x1,x2,x3对应数值,现在的Y是来判断父母会不会打你,打的话是1,不打就是0。
父母打你这件事情很茫然,因为最后结果,好像跟x关系不大,如果直接来判断的话,肯定不准,那应该怎么去做?
比如H1神经元它代表伤人,比如放鞭炮把别人炸了、动刀伤人,那么结果父母就是打你。伤人这件事是推断出来的,它是隐藏在玩火和动刀背后,推断出来一个隐藏的情况,一个节点。上房也是一样,上的是别人家的房顶,导致伤人了。
如果没有隐藏层,直接拿玩火、动刀、上房推断打你还是不打你,这件事情会难,因为它们没有什么直接联系。如果再往前再推一层,加一个隐藏节点H1,比如伤人,按照伤人来判断父母是打你还是不打你,这件事就更简单的来判断。
H2比如是孝顺,比如你玩火了十次,不是放鞭炮,而是开火生灶,开了10次;动刀是切菜;上房是上自己家房顶打扫,都可以。
所以隐藏层里面隐藏节点,代表一些隐含在背后可能推断出来的,可能演化出来的,演变出来一些中间的结果,然后根据这些中间的结果,再对最后的结果进行推测和预测,这种情况可以判断的更准。
如果咱们只推出两个结果的话,就是降维;神经网络里面一层有多少神经元,是可以随便设置的,如果神经元设置更多,相当于推断出更多有可能发生的事件。如果隐藏层设置更多神经元,就可以做到升维。
它就是神经网络意义所在,它可以帮助我们推断一些东西出来。
我们需要计算是什么呢?对于机器学习模型来说,我们要算的是每根连线上面参数w值是多少。这个例子要算8个w,如图:
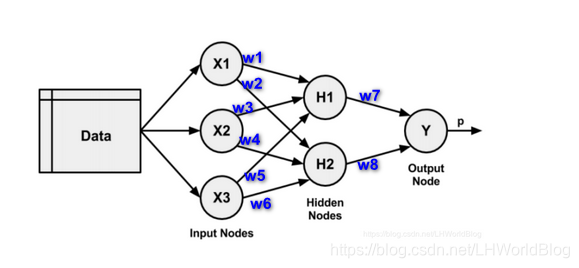 ?
?
那么算w的个数比刚才要远远的多。 一层的神经网络只要算三个w,现在至少算八个。
这些w值有什么用呢?做预测。比如下次一个人给我传他的数据,x1到xn,我根据已经算好的w进行正向传播,最后算出来y结果就会得到一个概率,根据概率我们再来预测,最后是正例还是负例。
神经网络它的意义是,在一定程度上可以进行推断,或者叫演绎,可以把一些隐藏它背后的事件给它推导和演绎出来。
结合以前最火的AlphaGo,它用的是人工智能,背后就是深度学习,深度学习的本质就是神经网络,为什么要用神经网络来做下围棋这件事情,因为能看到的输入是现在棋盘上这些子所在的位置,也就是有x1到xn个输入,就是每一个子所在的位置。直白一点,可以把它理解为一个棋盘有多少行多少列,n就是它多少行乘多少列的值。有子是几,没有子是几,白颜色是几,黑颜色是几。
下一层是推断,但是推断出来是什么咱们不用关心,知道已知和最后的结果,因为AlphaGo在训练的过程当中,它一定是知道x和y的,然后它根据已知x和y来算x,y之间的隐藏层所对应的连接。
不管下围棋还是象棋,什么叫高手?你能想到3步,人家能想到后7步;你能想到后7步,人家能想到后20步。后一步相当于是你往前推断和演绎了一步,就是一个隐藏层。如果你用一个隐藏层,相当于是推断和演绎了另外一步。隐藏层越多,网络层次就越深,它就越是深度学习。
每往前推断一步,推断的情形越多,就意味着隐藏层上面的隐藏节点的数量就越多。
如果隐藏层层数多,每一层上的神经元个数又很多,就会导致整个网络的连接就越多,w值越多。如果计算机的话,它要需要反复迭代来算它最优解。一旦有了网络拓朴,还是拿AlphaGo举例,它其实就是一个模型,这种模型就是一个网络拓扑结构,网络拓扑结构里面,点和点之间都有连线,都有w权重。 每当这个人输入一个子的时候,相当于x1到xn的输入就变了,走一次正向传播,得到一个概率值。但是下棋落子的位置有很多种,比如说棋盘上面有很多个点,每下一步的时候,落子的位置不同,就会导致这一次的x1到xn的输入就不一样了。
AlphaGo就是把你这两次落子的位置,转变为x1到xn,两次不同输入,然后一路算下来会得到两个概率值,哪个概率值越大,胜的概率就越大。
相当于每走一步之前,它都会把现在落子的可能性带入这个模型,走一遍正向传播,然后使得走哪一步棋的时候,概率最大,就是最终决定要走的。
深度学习,每次传一个数据都是一个向量,每次传入的向量大概是几百个?输入层输入量多少都可以,根据需求来。比如刚才数据集里面,x1是玩火,x2是动刀,x3是上房,只有三个维度,那么输入层就是这三个。可以是0到正无穷,也可以是0和1,看你的需求。在输入层这地方也可以有很多特征转换的工作,比如x1是动刀,数据里面就是0和1,1是动了,0就表示没动,那么x就是一个输入;如果x是一个次数,比如说10次,20次,30次,40次,我们也可以通过一种手段,比如去做离散化,比如10到30的归为0,40到60的归为1,依次类推。这个就看去做预处理的时候怎么思考这件事情,然后来决定输入的形式。
神经网络就是未来的方向,换句话说,深度学习就是未来的方向,它会把很多事情整合到一起,比如输入层到第一个隐藏层,不管升维还是降维,它都做了一下数据的预处理。如果再有隐藏层,它就对这个数据再进行预处理。
而之前讲机器学习的时候,数据预处理和算法训练,其实是分开的。神经网络数据预处理和最后的模型训练是一个整体。这就是神经网络的好处。
神经网络它是未来的一个趋势,但是它其实是一个大招,就是真正在公司里面去做这个模型的时候,不是上来就用深度学习大招了,往往都是先用机器学习的算法,如果算模型满足业务需求,比如说准确率达到了公司收入的90%,能用就这样用了。未来如果说公司专业准确率不够,还要提升准确率,其它的算法都不行的情况下,然后再去用深度学习、神经网络。
为什么公司不是直接就用神经网络呢?耗资源,如果网络层次多了,每层里面神经元的个数多了,要去算的w会特别多,它不是一下能算出来,需要反复的迭代。所以深度学习的模型一算可能就是一天,数量大的时候可能一算就是三天,所以深度学习的模型往往需要算很长的时间。
我们再欣赏下不同的网络拓扑层。
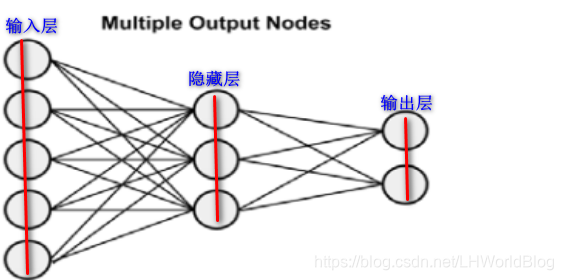 ?
?
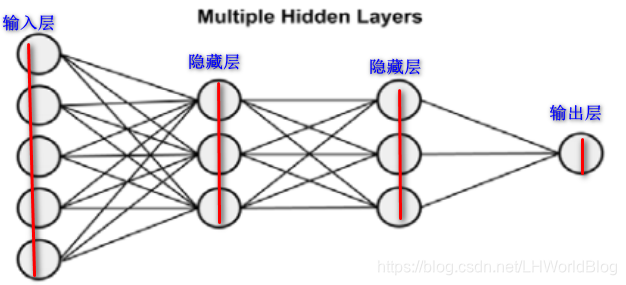 ?
?
神经网络的网络拓扑,上面是一个隐藏层,下面是多个隐藏层。
分为两个阶段,一个是正向传播,一个是反向传播。通常人们会用SGD随机梯度下降,最重要的就是算梯度,根据梯度再来调整w。正向传播就是一路算它的Loss损失,有了损失之后再进行反向传播,反向传播就是算每根线上面w所对应的梯度。
为什么需要反向传播?因为最终算的是每根线的w,所以w都要调整到最优解,所以反向传播就是要反过头来算每根线上所对应的梯度g1,g2……然后跟据梯度再去调整w。
之前讲逻辑回归或者浅层模型的时候,为什么没有提过反向传播呢?因为浅层的模型不用传播。
如图是浅层模型:
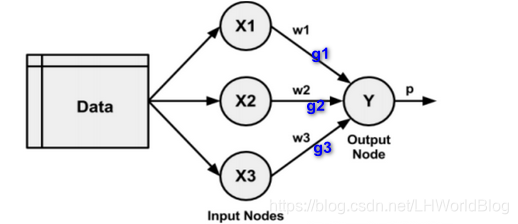 ?
?
最后输出节点是∑f,function是Sigmoid函数,也就是逻辑回归,对于逻辑回归来说,不需要传播,这里算出来Loss损失,以及w来求偏倒,可以得到梯度g1,g2,g3,因为它前面没有更多的层,所以它不需要去传播。
换句话说,就是浅层模型里面也是反向传播,只不过反向传播只传了一下,就从Loss经过中间一层,往前传求梯度。
反向传播最终会用到一个法则,数学上叫做链式法则求导,最终会一层层的把前面的梯度给它求出来。
大白话5分钟带你走进人工智能-第34节神经网络之多神经网络概念(2)
标签:随机梯度 需要 keep 概率 最大 趋势 near 情况下 框架
原文地址:https://www.cnblogs.com/LHWorldBlog/p/11365486.html