标签:模型 策略 关联 lock imp 强制 数加 a* abstract
计数器限流可以分为:
固定窗口计数器限流简单明了,就是限制单位之间内的请求数,比如设置QPS为10,那么从一开始的请求进入就计数,每次计数前判断是否到10,到达就拒绝请求,并保证这个计数周期是1秒,1秒后计数器清零。
以下是利用redis实现计数器分布式限流的实现,曾经在线上实践过的lua脚本:
local key = KEYS[1]
local limit = tonumber(ARGV[1])
local refreshInterval = tonumber(ARGV[2])
local currentLimit = tonumber(redis.call('get', key) or '0')
if currentLimit + 1 > limit then
return -1;
else
redis.call('INCRBY', key, 1)
redis.call('EXPIRE', key, refreshInterval)
return limit - currentLimit - 1
end 一个明显的弊端就是固定窗口计数器算法无法处理突刺流量,比如10QPS,1ms中来了10个请求,后续的999ms的所有请求都会被拒绝。
为了解决固定窗口的问题,滑动窗口将窗口细化,用更小的窗口来限制流量。比如 1 分钟的固定窗口切分为 60 个 1 秒的滑动窗口。然后统计的时间范围随着时间的推移同步后移。
即便滑动时间窗口限流算法可以保证任意时间窗口内接口请求次数都不会超过最大限流值,但是仍然不能防止在细时间粒度上面访问过于集中的问题。
为了应对上面的问题,对于时间窗口限流算法,还有很多改进版本,比如:
多层次限流,我们可以对同一个接口设置多条限流规则,除了 1 秒不超过 100 次之外,我们还可以设置 100ms 不超过 20 次 (代码中实现写了平均的两倍),两条规则同时限制,流量会更加平滑。
简单实现的代码如下:
public class SlidingWindowRateLimiter {
// 小窗口链表
LinkedList<Room> linkedList = null;
long stepInterval = 0;
long subWindowCount = 10;
long stepLimitCount = 0;
int countLimit = 0;
int count = 0;
public SlidingWindowRateLimiter(int countLimit, int interval){
// 每个小窗口的时间间距
this.stepInterval = interval * 1000/ subWindowCount;
// 请求总数限制
this.countLimit = countLimit;
// 每个小窗口的请求量限制数 设置为平均的2倍
this.stepLimitCount = countLimit / subWindowCount * 2;
// 时间窗口开始时间
long start = System.currentTimeMillis();
// 初始化连续的小窗口链表
initWindow(start);
}
Room getAndRefreshWindows(long requestTime){
Room firstRoom = linkedList.getFirst();
Room lastRoom = linkedList.getLast();
// 发起请求时间在主窗口内
if(firstRoom.getStartTime() < requestTime && requestTime < lastRoom.getEndTime()){
long distanceFromFirst = requestTime - firstRoom.getStartTime();
int num = (int) (distanceFromFirst/stepInterval);
return linkedList.get(num);
}else{
long distanceFromLast = requestTime - lastRoom.getEndTime();
int num = (int)(distanceFromLast/stepInterval);
// 请求时间超出主窗口一个窗口以上的身位
if(num >= subWindowCount){
initWindow(requestTime);
return linkedList.getFirst();
}else{
moveWindow(num+1);
return linkedList.getLast();
}
}
}
public boolean acquire(){
synchronized (mutex()) {
Room room = getAndRefreshWindows(System.currentTimeMillis());
int subCount = room.getCount();
if(subCount + 1 <= stepLimitCount && count + 1 <= countLimit){
room.increase();
count ++;
return true;
}
return false;
}
}
/**
* 初始化窗口
* @param start
*/
private void initWindow(long start){
linkedList = new LinkedList<Room>();
for (int i = 0; i < subWindowCount; i++) {
linkedList.add(new Room(start, start += stepInterval));
}
// 总记数清零
count = 0;
}
/**
* 移动窗口
* @param stepNum
*/
private void moveWindow(int stepNum){
for (int i = 0; i < stepNum; i++) {
Room removeRoom = linkedList.removeFirst();
count = count - removeRoom.count;
}
Room lastRoom = linkedList.getLast();
long start = lastRoom.endTime;
for (int i = 0; i < stepNum; i++) {
linkedList.add(new Room(start, start += stepInterval));
}
}
public static void main(String[] args) throws InterruptedException {
SlidingWindowRateLimiter slidingWindowRateLimiter = new SlidingWindowRateLimiter(20, 5);
for (int i = 0; i < 26; i++) {
System.out.println(slidingWindowRateLimiter.acquire());
Thread.sleep(300);
}
}
class Room{
Room(long startTime, long endTime) {
this.startTime = startTime;
this.endTime = endTime;
this.count = 0;
}
private long startTime;
private long endTime;
private int count;
long getStartTime() {
return startTime;
}
long getEndTime() {
return endTime;
}
int getCount() {
return count;
}
int increase(){
this.count++;
return this.count;
}
}
private volatile Object mutexDoNotUseDirectly;
private Object mutex() {
Object mutex = mutexDoNotUseDirectly;
if (mutex == null) {
synchronized (this) {
mutex = mutexDoNotUseDirectly;
if (mutex == null) {
mutexDoNotUseDirectly = mutex = new Object();
}
}
}
return mutex;
}
}以上实现使用了链表的特性,在一定窗口时是将前段删除后段加上的方式移动的。移动的操作是请求进入时操作的,没有使用单独线程移动窗口。并且按照前面讲的,两个维度控制流量一个时窗口的总请求数,一个是每个单独窗口的请求数。
原理如图:
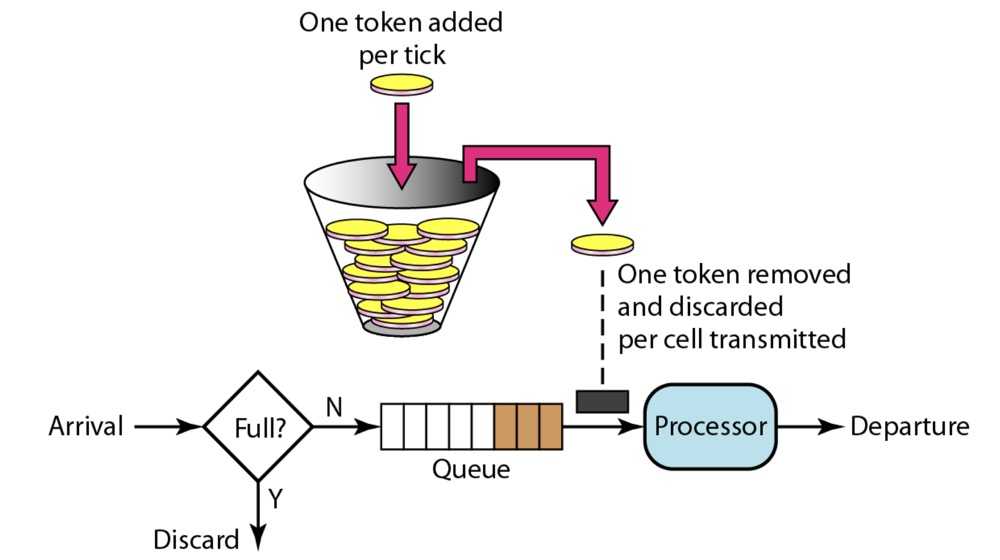
目前使用令牌桶实现的限流有以下几个:
zuul2跳票后Spring Cloud 自己开发的网关,内部也实现了限流器
因为是微服务架构,多服务部署是必然场景,所以默认提供了redis为存储载体的实现,所以直接看rua脚本是怎么样的就可以知道它的算法是怎么实现的了:
local tokens_key = KEYS[1]
local timestamp_key = KEYS[2]
--redis.log(redis.LOG_WARNING, "tokens_key " .. tokens_key)
// 速率
local rate = tonumber(ARGV[1])
// 桶容量
local capacity = tonumber(ARGV[2])
// 发起请求时间
local now = tonumber(ARGV[3])
// 请求令牌数量 现在固定是1
local requested = tonumber(ARGV[4])
// 存满桶耗时
local fill_time = capacity/rate
// 过期时间
local ttl = math.floor(fill_time*2)
--redis.log(redis.LOG_WARNING, "rate " .. ARGV[1])
--redis.log(redis.LOG_WARNING, "capacity " .. ARGV[2])
--redis.log(redis.LOG_WARNING, "now " .. ARGV[3])
--redis.log(redis.LOG_WARNING, "requested " .. ARGV[4])
--redis.log(redis.LOG_WARNING, "filltime " .. fill_time)
--redis.log(redis.LOG_WARNING, "ttl " .. ttl)
// 上次请求的信息 存在redis
local last_tokens = tonumber(redis.call("get", tokens_key))
// 可任务初始化桶是满的
if last_tokens == nil then
last_tokens = capacity
end
--redis.log(redis.LOG_WARNING, "last_tokens " .. last_tokens)
// 上次请求的时间
local last_refreshed = tonumber(redis.call("get", timestamp_key))
if last_refreshed == nil then
last_refreshed = 0
end
--redis.log(redis.LOG_WARNING, "last_refreshed " .. last_refreshed)
// 现在距离上次请求时间的差值 也就是距离上次请求过去了多久
local delta = math.max(0, now-last_refreshed)
// 这个桶此时能提供的令牌是上次剩余的令牌数加上这次时间间隔按速率能产生的令牌数 最多不能超过片桶大小
local filled_tokens = math.min(capacity, last_tokens+(delta*rate))
// 能提供的令牌和要求的令牌比较
local allowed = filled_tokens >= requested
local new_tokens = filled_tokens
local allowed_num = 0
if allowed then
// 消耗调令牌
new_tokens = filled_tokens - requested
allowed_num = 1
end
--redis.log(redis.LOG_WARNING, "delta " .. delta)
--redis.log(redis.LOG_WARNING, "filled_tokens " .. filled_tokens)
--redis.log(redis.LOG_WARNING, "allowed_num " .. allowed_num)
--redis.log(redis.LOG_WARNING, "new_tokens " .. new_tokens)
// 存储剩余的令牌
redis.call("setex", tokens_key, ttl, new_tokens)
redis.call("setex", timestamp_key, ttl, now)
return { allowed_num, new_tokens }
1,在请求令牌时计算上次请求和此刻的时间间隔能产生的令牌,来刷新桶中的令牌数,然后将令牌提供出去。
2,如果令牌不足没有等待,直接返回。
3,实现的方式是将每个请求的时间间隔为最小单位,只要小于这个单位的请求就会拒绝,比如100qps的配置,1允许10ms一个,如果两个请求比较靠近小于10ms,后一个会被拒绝。
一个Guava实现的令牌桶限流器。
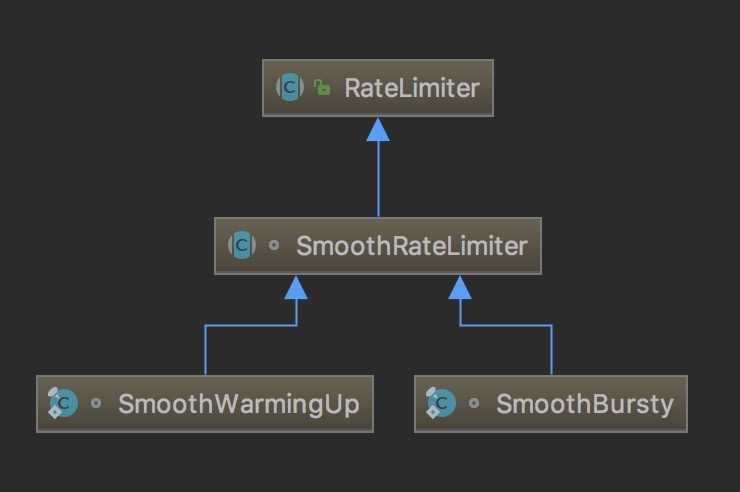
RateLimiter就是一个根据配置的rate分发permits的工具。每一次调用acquire()都会阻塞到获得permit为止,一个permit只能用一次。RateLimiter是并发安全的,它将限制全部线程的全部请求速率,但是RateLimiter并不保证是公平的。
限速器经常被使用在限制访问物理或逻辑资源的速率,和java.util.concurrent.Semaphore对比,Semaphore用于限制同时访问的数量,而它限制的是访问的速率(两者有一定关联:就是little‘s law(律特法则))。
RateLimiter主要由发放许可证的速度来定义。如果没有其他配置,许可证将以固定的速率分发,以每秒许可证的形式定义。许可证将平稳分发,各许可证之间的延迟将被调整到配置的速率。(SmoothBursty)
也可以将RateLimiter配置为有一个预热期,在此期间,每秒钟发出的许可稳步增加,直到达到稳定的速率。(SmoothWarmingUp)
一个例子:我们一个任务列表需要执行,但是每秒提交的任务个数不能超过2个。
final RateLimiter rateLimiter = RateLimiter.create(2.0); // rate is "2 permits per second"
void submitTasks(List<Runnable> tasks, Executor executor) {
for (Runnable task : tasks) {
rateLimiter.acquire(); // may wait
executor.execute(task);
}
}另一个例子:我们生产一个数据流想以5kb每秒的速度传输,这个可以通过将一个permit对应一个byte,并定义5000/s的速率。
final RateLimiter rateLimiter = RateLimiter.create(5000.0); // rate = 5000 permits per second
void submitPacket(byte[] packet) {
rateLimiter.acquire(packet.length);
networkService.send(packet);
}有一点需要注意,请求令牌的数量不会影响请求自身的节流,但是会影响下一次请求,如果一个需要大量令牌的任务到达时,将马上授予,但是下一次请求将会为上次昂贵任务付出代价。
对于RateLimiter来说最关键的特性是:在一般情况下允许的最大速率-“恒定速率”。这需要对传入的请求强制执行即计算“节流”,也需要在适当的节流时间,让请求线程等待。
维护QPS的速率最简单的方式就是保留最后准许请求的时间戳,确保能计算从那是到现在流逝的时间和QPS。举个例子,一个QPS为5(5个token每秒)的速率,如果我们确保请求被准许时比最后的请求早200ms,我们就达到了想要的速率。如果最后准许的请求只过去100ms,那么我们需要等待100ms。在这个速率下,提供新的15个许可证(即调用acquire(15))自然需要3s。
RateLimiter只记住最后一次请求的时间戳,只是对过去非常浅的记忆,意识到这点很重要。假如很长一段时间没有使用RateLimiter,然后来了一个请求,是马上准许吗?这样的RateLimiter将马上忘记刚刚过去的利用不足的时间。最终,因为现实请求速率的不规则导致要么利用不足或溢出的结果。过去利用不足意味着存在过剩可用资源,所以RateLimiter想要利用这些资源,就需要提速一会儿。在计算机网络中应用的速率(带宽限制),那些过去利用不足的一般会转换成“几乎为空的缓冲区”,可以马上用于后续流量。
另一方面,过去利用不足也意味着“服务器对未来请求的处理的准备变得越来越少”,也就是说,缓存变过期,请求将更有可能触发昂贵的操作(一个更极端的例子,当服务启动后,它通常忙于提高自己的速度)。
为了处理这类场景,我们增加了一个额外的维度,将过去利用不足建模到storedPermits字段。没有利用不足情况时这个字段的值是0,随着逐渐到达充分利用不足,这个字段的值会增大到一个最大值maxStoredPermits。
所以,当执行acquire(permits)方法来请求许可证从两方面获取:
下面用一个例子来解释工作原理:假设RateLimiter每秒生成一个token,每一秒过去而RateLimiter没有被使用的话,就会把storedPermits加1。我们不使用RateLimiter10秒(即,我们期望在一个X时间有一个请求,可是实际在X+10秒后请求才到达;这个和最后一个段落的结论有关),storedPermits会变成10(假定maxStoredPermits>=10)。在那时一个调用acquire(3)的请求到达。我们使用storedPermits将它降到7来响应这个请求(how this is translated to throttling time is discussed later),之后acquire(10)的请求马上到达。我们使用storedPermits中全部剩余的7个permits,剩下的3个使用RateLimiter生产的新permits。我们已经知道,获得三个fresh permits需要多少时间:如果速率是“1秒一个token”,那么需要3秒时间。但是提供7个存储的permits意味着什么?前面的解释中没有唯一的答案。如果主要关注处理利用不足的情况,我们存储permits为了给出比fresh permits快,因为利用不足=空闲资源。如果主要关注overflow的场景,存储permits可以比fresh permits慢给出。所以,我们需要一个方法将storedPermits转换成节流时间(throttling time)。
而storedPermitsToWaitTime(double storedPermits, double permitsToTake)这个方法就扮演了这个转换的角色。它的基础模型是一个连续函数映射存储令牌(从0到maxStoredPermits)在1/Rate的积分。我们利用空闲时间来存储令牌,所以storedPermits本质上是度量了空闲时间(unused time)。Rate=permits/time,1/Rate=time/permits,所以,1/Rate和permits相乘就可以算出时间。即处理一定量的令牌请求时,对这个函数进行积分就是对应于后续请求的最小间隔。
关于storedPermitsToWaitTime的一个例子:如果storedPermits==10,我们先需要3个从storedPermits中拿,storedPermits降到7,使用storedPermitsToWaitTime(storedPermits=10, permitsToToken=3)计算节流时间,它将求出函数从7到10的积分值。
使用积分保证了一个单独的acquire(3)和拆分成{acquire(1),acquire(1),acquire(1)}或{acquire(2),acquire(1)}都是一样的,另外,不管函数是怎么样的,对于函数[7,10]的求积分是等于[7,8],[8,9],[9,10]的总和的。这就保证了我们可以正确处理不同权重(permits不同)的请求,不管函数是什么,因此我们可以自由调整函数的算法(很显然,只有一个要求:可以被求积分)。注意,如果这个函数画的是个数值刚好是1/QPS的水平线,那么这个函数就失去作用了,因为它表示存储令牌的速率和生产新令牌的速率是一致的,后续中会用到这个技巧。如果这个函数的值在水平线的下面,也就是f(x)<1/Rate,表示我们减少了积分的面积,也就是相同存储的令牌数映射的节流时间相对于正常速率产生的时间变少了,也代表RateLimiter在一段时间空闲后变快了。相反的,如果函数的值在水平线的上面,表示增加了积分的面积,获得存储令牌的消耗要大于新生产令牌,那就意味着RateLimiter在一段时间空闲后变慢了。
最后但也重要,如果RateLimiter采用QPS=1的速度,那么开销较大的acquire(100)到达时,那是没有必要等到100s才开始实际任务,为什么不在等待的时候做点什么呢?更好的办法是我们可以马上先开始执行任务(就像它是acquire(1)一个个请求的样子),需要把未来的请求推后。
在这个版本,我们允许马上执行任务,并把未来的请求推后100s,所以,我们允许在这段时间里完成工作,而不是空等。
这就有了一个很重要的结论:RateLimiter并需要不记住最后请求的时间,而只需要记住期望下一个请求到来的时间。因为我们一直坚持这一点,如此我们就可以马上识别出一个请求(tryAcquire(timeout))超时时间是否满足下一个预期请求到达的时间点。通过这个概念我们可以重新定义“一个空闲的RateLimiter”:当我们观察到“期望下一个请求达到时间”实际已经过去,并且差值(now-past)也就是大量时间被转换成storedPermits。(我们把在空闲时间生产的令牌增加storedPermits)。所以,如果Rate=1 permit/s,且到达时间恰好比前一次请求晚一秒,那么storedPermits将永远不会增加—我们只会在到达时间晚于一秒时增加它。
SmoothWarmingUp实现原理:顾名思义,这里想要实现的是一个有预热能力的RateLimiter,作者在注释中还画了这幅图:
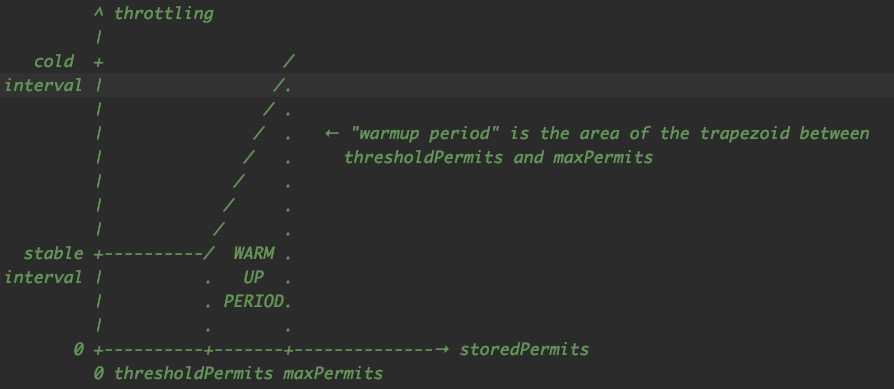
在进入详细实现前,让我们先记住几个基本原则:
总之,向左移动K个permits所需要花费的节流时间等于长度为K的函数的面积。假设RateLimiter的storedPermits饱和状态,从maxPermits到thresholdPermits就等于warmupPeriod。从thresholdPermits到0的时间是warmupPeriod/2(原因是为了维护以前的实现,其中coldFactor硬编码为3)
计算thresholdPermits和maxPermits的公式:
从thresholdPermits到0花费的节流时间等于函数从0到thresholdPermits的积分,也就是thresholdPermits*stableIntervals。也等于warmupPeriod/2。
thresholdPermits=0.5*warmupPeriod/stableInterval
从maxPermits到thresholdPermits就是函数从thresholdPermits到maxPermits的积分,也就是梯型部分的面积,它等于0.5(stableInterval+coldInterval)(maxPermits - thresholdPermits),也就是warmupPeriod
maxPermits = thresholdPermits + 2*warmupPeriod/(stableInterval+coldInterval)
这里源码先从SmoothBursty入手,首先是RateLimiter类里的创建:
public static RateLimiter create(double permitsPerSecond) {
return create(permitsPerSecond, SleepingStopwatch.createFromSystemTimer());
}
@VisibleForTesting
static RateLimiter create(double permitsPerSecond, SleepingStopwatch stopwatch) {
// maxBurstSeconds代表这个桶能存储的令牌数换算的秒数,通过这个秒数就可以知道能存储的令牌数,也就表示这个桶的大小。
RateLimiter rateLimiter = new SmoothBursty(stopwatch, 1.0 /* maxBurstSeconds */);
rateLimiter.setRate(permitsPerSecond);
return rateLimiter;
}我们看到外界无法自定义SmoothBursty的桶大小,所以我们无论是创建什么速率的RateLimiter,桶的大小就必然是rate*1的大小,那么就有人通过反射的方式在满足自己想要修改桶大小的需求:https://github.com/vipshop/vjtools/commit/9eacb861960df0c41b2323ce14da037a9fdc0629
setRate方法:
public final void setRate(double permitsPerSecond) {
checkArgument(
permitsPerSecond > 0.0 && !Double.isNaN(permitsPerSecond), "rate must be positive");
// 需要全局同步
synchronized (mutex()) {
doSetRate(permitsPerSecond, stopwatch.readMicros());
}
}
private volatile Object mutexDoNotUseDirectly;
// 产生一个同步使用的对象,适应双重检查锁保证这个对象是个单例
private Object mutex() {
Object mutex = mutexDoNotUseDirectly;
if (mutex == null) {
synchronized (this) {
mutex = mutexDoNotUseDirectly;
if (mutex == null) {
mutexDoNotUseDirectly = mutex = new Object();
}
}
}
return mutex;
}
互斥锁来保证线程的安全,具体实现代码中使用volatile修饰的mutexDoNotUseDirectly字段和双重校验同步锁来保证生成单例,从而保证每次调用mutex()都是锁同一个对象。这在后续的获取令牌中也需要用到。
doSetRate方法是子类SmoothRateLimiter实现:
// 当前存储的令牌
double storedPermits;
// 最大能够存储的令牌
double maxPermits;
// 两次获取令牌的固定间隔时间
double stableIntervalMicros;
// 下一个请求能被授予的时间,一次请求后这个值就会推后,一个大请求推后的时间比一个小请求推后的时间要多
// 这和预消费有关系,上一次消费的令牌
private long nextFreeTicketMicros = 0L;
final void doSetRate(double permitsPerSecond, long nowMicros) {
resync(nowMicros);
// 计算出请求授予的间隔时间
double stableIntervalMicros = SECONDS.toMicros(1L) / permitsPerSecond;
this.stableIntervalMicros = stableIntervalMicros;
doSetRate(permitsPerSecond, stableIntervalMicros);
}
// 更新storedPermits和nextFreeTicketMicros
void resync(long nowMicros) {
// 当前时间大于下一个请求时间 说明这次请求不用等待 如果不是就不会出现增加令牌的操作
if (nowMicros > nextFreeTicketMicros) {
// 根据上次请求和这次请求间隔计算能够增加的令牌
double newPermits = (nowMicros - nextFreeTicketMicros) / coolDownIntervalMicros();
// 存储的令牌不能超过maxPermits
storedPermits = min(maxPermits, storedPermits + newPermits);
// 修改nextFreeTicketMicros为当前时间
nextFreeTicketMicros = nowMicros;
}
}
// 子类实现
abstract void doSetRate(double permitsPerSecond, double stableIntervalMicros);
// 返回冷却期间需要等待获得新许可证的微秒数。子类实现
abstract double coolDownIntervalMicros();SmoothBursty的实现
static final class SmoothBursty extends SmoothRateLimiter {
/** The work (permits) of how many seconds can be saved up if this RateLimiter is unused? */
final double maxBurstSeconds;
SmoothBursty(SleepingStopwatch stopwatch, double maxBurstSeconds) {
super(stopwatch);
this.maxBurstSeconds = maxBurstSeconds;
}
@Override
void doSetRate(double permitsPerSecond, double stableIntervalMicros) {
double oldMaxPermits = this.maxPermits;
// 计算出桶的最大值
maxPermits = maxBurstSeconds * permitsPerSecond;
if (oldMaxPermits == Double.POSITIVE_INFINITY) {
// if we don't special-case this, we would get storedPermits == NaN, below
storedPermits = maxPermits;
} else {
// 初始化为0 后续重新设置时按新maxPermits和老maxPermits的比例计算storedPermits
storedPermits =
(oldMaxPermits == 0.0)
? 0.0 // initial state
: storedPermits * maxPermits / oldMaxPermits;
}
}
@Override
long storedPermitsToWaitTime(double storedPermits, double permitsToTake) {
return 0L;
}
// 对于SmoothBursty 没有什么冷却时期,所以始终返回的是stableIntervalMicros
@Override
double coolDownIntervalMicros() {
return stableIntervalMicros;
}
}然后看下获取令牌:
public double acquire() {
return acquire(1);
}
public double acquire(int permits) {
long microsToWait = reserve(permits);
// 等待microsToWait时间 控制速率
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return 1.0 * microsToWait / SECONDS.toMicros(1L);
}
final long reserve(int permits) {
checkPermits(permits);
synchronized (mutex()) {
return reserveAndGetWaitLength(permits, stopwatch.readMicros());
}
}
// 获得需要等待的时间
final long reserveAndGetWaitLength(int permits, long nowMicros) {
long momentAvailable = reserveEarliestAvailable(permits, nowMicros);
return max(momentAvailable - nowMicros, 0);
}
// 子类SmoothRateLimiter实现
abstract long reserveEarliestAvailable(int permits, long nowMicros);
reserveEarliestAvailable方法,刷新下一个请求能被授予的时间
final long reserveEarliestAvailable(int requiredPermits, long nowMicros) {
// 每次acquire都会触发resync
resync(nowMicros);
// 返回值就是下一个请求能被授予的时间
long returnValue = nextFreeTicketMicros;
// 选出请求令牌数和存储令牌数较小的一个 也就是从存储的令牌中需要消耗的数量
double storedPermitsToSpend = min(requiredPermits, this.storedPermits);
// 计算本次请求中需要行创建的令牌
double freshPermits = requiredPermits - storedPermitsToSpend;
// 计算需要等待的时间 就是存储令牌消耗的时间+新令牌产生需要的时间
long waitMicros =
storedPermitsToWaitTime(this.storedPermits, storedPermitsToSpend)
+ (long) (freshPermits * stableIntervalMicros);
// 刷新下一个请求能被授予的时间 是将这次等待的时间加上原先的值 就是把这次请求需要产生的等待时间延迟给下一次请求 这就是一个大请求会马上授予 但后续的请求会被等待长时间 所以这里的思路核心就是再每次请求时都是在预测下一次请求到来的时间
this.nextFreeTicketMicros = LongMath.saturatedAdd(nextFreeTicketMicros, waitMicros);
// 刷新存储令牌
this.storedPermits -= storedPermitsToSpend;
return returnValue;
}
// 这个是用来计算存储令牌在消耗时的节流时间 也就是通过这个方法子类可以控存储令牌的速率 我们看到的SmoothBursty的实现是始终返回0 表示消耗存储的令牌不需要额外的等待时间 我们在预热的实现中可以看到不一样的实现
abstract long storedPermitsToWaitTime(double storedPermits, double permitsToTake);
再来看一下请求令牌方法带超时时间的方法:
public boolean tryAcquire(long timeout, TimeUnit unit) {
return tryAcquire(1, timeout, unit);
}
public boolean tryAcquire(int permits) {
return tryAcquire(permits, 0, MICROSECONDS);
}
public boolean tryAcquire() {
return tryAcquire(1, 0, MICROSECONDS);
}
public boolean tryAcquire(int permits, long timeout, TimeUnit unit) {
long timeoutMicros = max(unit.toMicros(timeout), 0);
checkPermits(permits);
long microsToWait;
synchronized (mutex()) {
long nowMicros = stopwatch.readMicros();
// 判定设置的超时时间是否足够等待下一个令牌的给予,等不了,就直接失败
if (!canAcquire(nowMicros, timeoutMicros)) {
return false;
} else {
// 获得需要等待的时间
microsToWait = reserveAndGetWaitLength(permits, nowMicros);
}
}
// 等待
stopwatch.sleepMicrosUninterruptibly(microsToWait);
return true;
}
private boolean canAcquire(long nowMicros, long timeoutMicros) {
return queryEarliestAvailable(nowMicros) - timeoutMicros <= nowMicros;
}以上可以基本理解一个普通的限流器的实现方式,可以看到实现中可以通过doSetRate,storedPermitsToWaitTime,coolDownIntervalMicros方法进行定制自己的限流策略。
那么这里的SmoothBursty的策略是:
maxPermits = maxBurstSeconds * permitsPerSecond;我们继续看稍微复杂点的SmoothWarmingUp,毕竟为了说明它人家作者都用注释画了示意图。
static final class SmoothWarmingUp extends SmoothRateLimiter {
// 预热累计消耗时间
private final long warmupPeriodMicros;
/**
* The slope of the line from the stable interval (when permits == 0), to the cold interval
* (when permits == maxPermits)
*/
private double slope;
private double thresholdPermits;
// 冷却因子 固定是3 意思是通过这个因子可以计算在令牌桶满的时候,消耗令牌需要的最大时间
private double coldFactor;
SmoothWarmingUp(
SleepingStopwatch stopwatch, long warmupPeriod, TimeUnit timeUnit, double coldFactor) {
super(stopwatch);
this.warmupPeriodMicros = timeUnit.toMicros(warmupPeriod);
this.coldFactor = coldFactor;
}
@Override
void doSetRate(double permitsPerSecond, double stableIntervalMicros) {
double oldMaxPermits = maxPermits;
// 通过coldFactor就可以算出coldInterval的最高点 即stableIntervalMicros的3倍 也就是说图中的梯形最高点是固定的了
double coldIntervalMicros = stableIntervalMicros * coldFactor;
// 根据warmupPeriodMicros*2=thresholdPermits*stableIntervalMicros换算thresholdPermits 因为我们看到梯形最高点是固定的 那么通过设置warmupPeriod是可以控制thresholdPermits,从而控制maxPermits的值
thresholdPermits = 0.5 * warmupPeriodMicros / stableIntervalMicros;
// 也是根据上面提到的公式计算maxPermits
maxPermits =
thresholdPermits + 2.0 * warmupPeriodMicros / (stableIntervalMicros + coldIntervalMicros);
// 倾斜角度
slope = (coldIntervalMicros - stableIntervalMicros) / (maxPermits - thresholdPermits);
if (oldMaxPermits == Double.POSITIVE_INFINITY) {
// if we don't special-case this, we would get storedPermits == NaN, below
storedPermits = 0.0;
} else {
storedPermits =
(oldMaxPermits == 0.0)
? maxPermits // 这里的初始值是maxPermits
: storedPermits * maxPermits / oldMaxPermits;
}
}
@Override
long storedPermitsToWaitTime(double storedPermits, double permitsToTake) {
// 超过thresholdPermits的存储令牌
double availablePermitsAboveThreshold = storedPermits - thresholdPermits;
long micros = 0;
// measuring the integral on the right part of the function (the climbing line)
if (availablePermitsAboveThreshold > 0.0) {
double permitsAboveThresholdToTake = min(availablePermitsAboveThreshold, permitsToTake);
// 这里就开始算这个梯形的面积了 梯形面积=(上底+下底)*高/2
double length =
permitsToTime(availablePermitsAboveThreshold)
+ permitsToTime(availablePermitsAboveThreshold - permitsAboveThresholdToTake);
micros = (long) (permitsAboveThresholdToTake * length / 2.0);
permitsToTake -= permitsAboveThresholdToTake;
}
// measuring the integral on the left part of the function (the horizontal line)
micros += (long) (stableIntervalMicros * permitsToTake);
return micros;
}
private double permitsToTime(double permits) {
return stableIntervalMicros + permits * slope;
}
// 为了确保从0到maxpermit所花费的时间等于预热时间 可以看下resync方法中对coolDownIntervalMicros方法的使用
@Override
double coolDownIntervalMicros() {
return warmupPeriodMicros / maxPermits;
}
}1,Guava在对RateLimiter设计中采用的是令牌桶的算法,提供了普通和预热两种模型,在存储令牌增加和消耗的设计思路是计算函数积分的方式。
2,对于第一个新来的请求,无论请求多少令牌,不阻塞。
3,内部使用线程sleep方式达到线程等待,没超时时间会一直等到有令牌
4,令牌存储发生在请求令牌时,不需要单独线程实现不断产生令牌的算法
5,内部设计的类一些参数并不开放外部配置
原理如图:
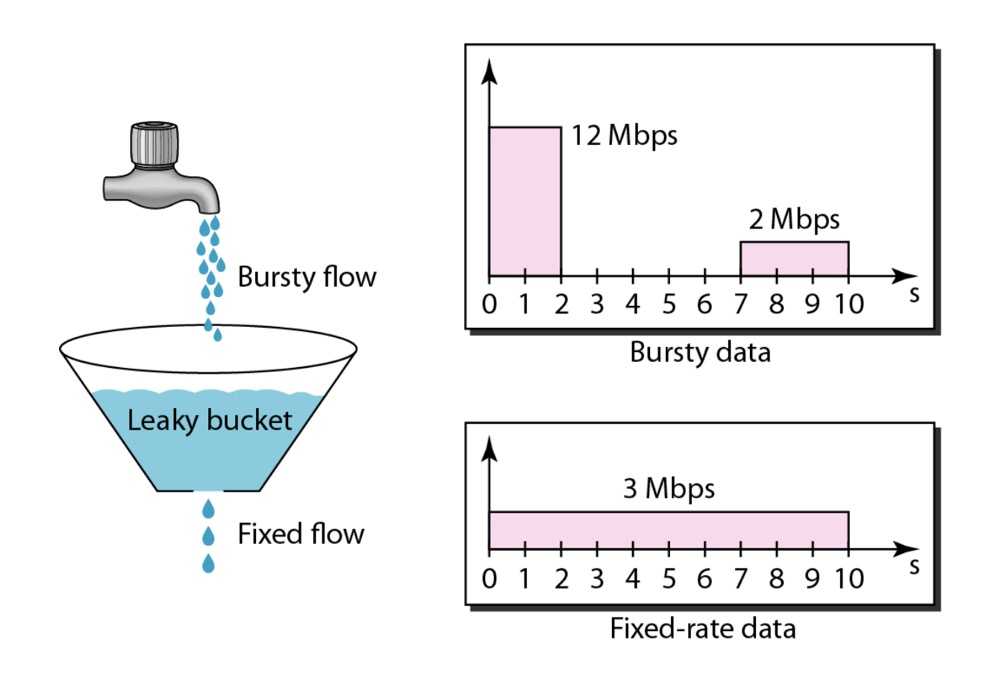
我们有一个固定的桶,这个桶的出水速率是固定的,流量不断往桶中放水,进水速度比出水速度快的时候,可以在桶中有一个缓冲,可是到达一定量超出桶的容量,就会溢出桶,无法接受新的请求。
这个思路不就是阻塞队列嘛,只要在消费的放保持固定速率即可。
实现类似如下代码(示意使用):
public class LeakyBucketLimiter {
BlockingQueue<String> leakyBucket;
long rate;
public LeakyBucketLimiter(int capacity, long rate) {
this.rate = rate;
this.leakyBucket = new ArrayBlockingQueue<String>(capacity);
}
public boolean offer(){
return leakyBucket.offer("");
}
class Consumer implements Runnable{
public void run() {
try {
while (true){
Thread.sleep(1000/rate);
leakyBucket.take();
}
} catch (InterruptedException e) {
}
}
}
}和令牌桶允许一定突发请求时的高速率,以及空闲后降低速率不同的是,漏桶算法是必然保证速率不变的。
一个思路是监控系统的状态,比如cpu,内存,io等,依据这些信息来开关限流器。
在分布式系统中,如果想用分布式限流,就需要公用存储的载体,比如redis,zk等。还需要考量分布式存储载体失效,不能影响正常业务功能。
http://www.cs.ucc.ie/~gprovan/CS6323/2014/L11-Congesion-Control.pdf(网上很多桶算法限流的图都来自这里)
标签:模型 策略 关联 lock imp 强制 数加 a* abstract
原文地址:https://www.cnblogs.com/killbug/p/11370694.html