标签:receive eset disco HCL sed 丢失 new writing 建立
DRBD(Distributed ReplicatedBlock Device)是一种基于软件的,无共享,分布式块设备复制的存储解决方案,在服务器之间的对块设备(硬盘,分区,逻辑卷等)进行镜像。
也就是说当某一个应用程序完成写操作后,它提交的数据不仅仅会保存在本地块设备上,DRBD也会将这份数据复制一份,通过网络传输到另一个节点的块设备上,这样,两个节点上的块设备上的数据将会保存一致,这就是镜像功能。
DRBD是由内核模块和相关脚本而构成,用以构建高可用性的集群,其实现方式是通过网络来镜像整个设备。它允许用户在远程机器上建立一个本地块设备的实时镜像,与心跳连接结合使用,可以把它看作是一种网络RAID,它允许用户在远程机器上建立一个本地块设备的实时镜像。
DRBD工作在内核当中,类似于一种驱动模块。DRBD工作的位置在文件系统的buffer cache和磁盘调度器之间,通过tcp/ip发给另外一台主机到对方的tcp/ip最终发送给对方的drbd,再由对方的drbd存储在本地对应磁盘 上,类似于一个网络RAID-1功能。在高可用(HA)中使用DRBD功能,可以代替使用一个共享盘阵。本地(主节点)与远程主机(备节点)的数据可以保 证实时同步。当本地系统出现故障时,远程主机上还会保留有一份相同的数据,可以继续使用。
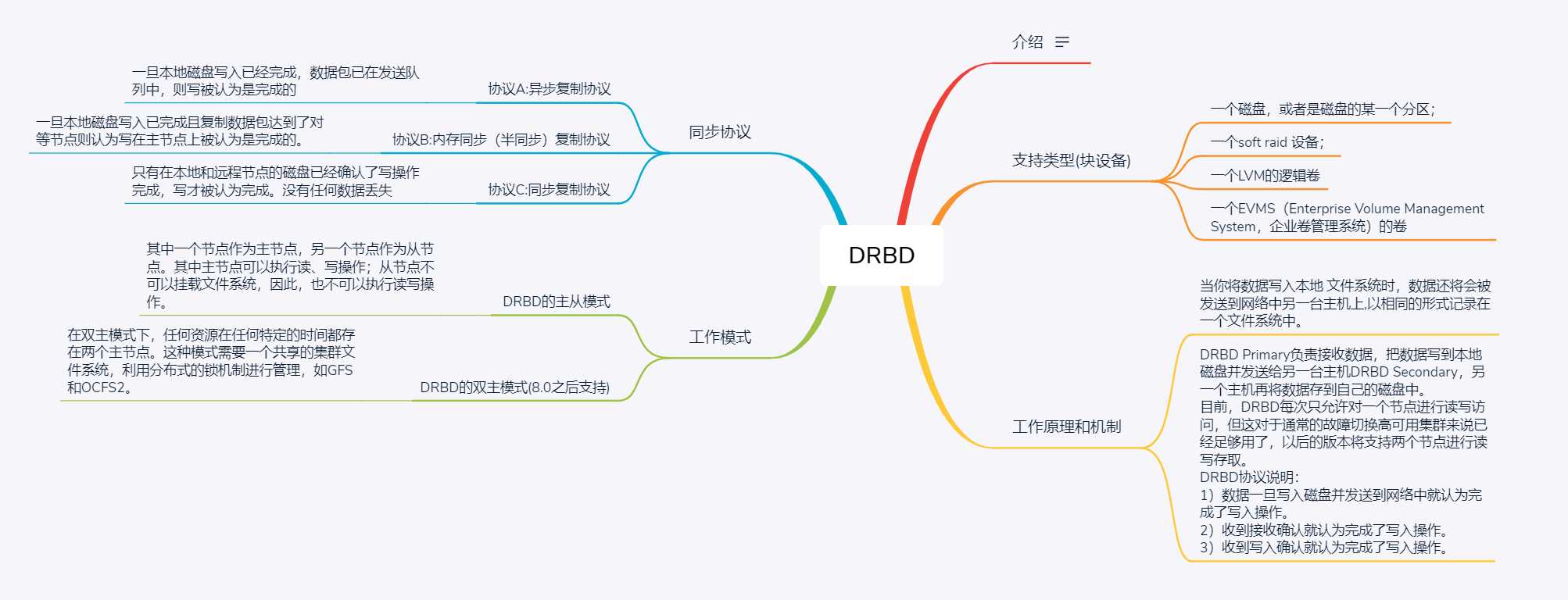
1 DRBD底层设备支持
DRBD需要构建在底层设备之上,然后构建出一个块设备出来。对于用户来说,一个DRBD设备,就像是一块物理的磁盘,可以在上面内创建文件系统。
DRBD所支持的底层设备有以下这些类:
1)一个磁盘,或者是磁盘的某一个分区;
2)一个soft raid 设备;
3)一个LVM的逻辑卷;
4)一个EVMS(Enterprise Volume Management System,企业卷管理系统)的卷;
5)其他任何的块设备。
2 DRBD工作原理
DRBD是一种块设备,可以被用于高可用(HA)之中,它类似于一个网络RAID-1功能,当你将数据写入本地 文件系统时,数据还将会被发送到网络中另一台主机上,以相同的形式记录在一个文件系统中。 本地(主节点)与远程主机(备节点)的数据可以保证实时同步.当本地系统出现故障时,远程主机上还会 保留有一份相同的数据,可以继续使用.在高可用(HA)中使用DRBD功能,可以代替使用一个共享盘阵.因为数据同时存在于本地主机和远程主机上,切换时,远程主机只要使用它上面的那份备份数据,就可以继续进行服务了。
3 DRBD工作机制
DRBD Primary负责接收数据,把数据写到本地磁盘并发送给另一台主机DRBD Secondary,另一个主机再将数据存到自己的磁盘中。
目前,DRBD每次只允许对一个节点进行读写访问,但这对于通常的故障切换高可用集群来说已经足够用了,以后的版本将支持两个节点进行读写存取。
DRBD协议说明:
1)数据一旦写入磁盘并发送到网络中就认为完成了写入操作。
2)收到接收确认就认为完成了写入操作。
3)收到写入确认就认为完成了写入操作。DRBD有2中模式,一种是DRBD的主从模式,另一种是DRBD的双主模式:
1 DRBD的主从模式
这种模式下,其中一个节点作为主节点,另一个节点作为从节点。其中主节点可以执行读、写操作;从节点不可以挂载文件系统,因此,也不可以执行读写操作。
在这种模式下,资源在任何时间只能存储在主节点上。这种模式可用在任何的文件系统上(EXT3、EXT4、XFS等等)。默认这种模式下,一旦主节点发生故障,从节点需要手工将资源进行转移,且主节点变成从节点和从节点变成主节点需要手动进行切换。不能自动进行转移,因此比较麻烦。
为了解决手动将资源和节点进行转移,可以将DRBD做成高可用集群的资源代理(RA),这样一旦其中的一个节点宕机,资源会自动转移到另一个节点,从而保证服务的连续性。
2 DRBD的双主模式
这是DRBD8.0之后的新特性,在双主模式下,任何资源在任何特定的时间都存在两个主节点。这种模式需要一个共享的集群文件系统,利用分布式的锁机制进行管理,如GFS和OCFS2。
部署双主模式时,DRBD可以是负载均衡的集群,这就需要从两个并发的主节点中选取一个首选的访问数据。这种模式默认是禁用的,如果要是用的话必须在配置文件中进行声明。DRBD的复制功能就是将应用程序提交的数据一份保存在本地节点,一份复制传输保存在另一个节点上。但是DRBD需要对传输的数据进行确认以便保证另一个节点的写操作完成,就需要用到DRBD的同步协议,DRBD同步协议有三种:
1 协议A:异步复制协议
一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。这通常是用于地理上分开的节点。
数据在本地完成写操作且数据已经发送到TCP/IP协议栈的队列中,则认为写操作完成。如果本地节点的写操作完成,此时本地节点发生故障,而数据还处在TCP/IP队列中,则数据不会发送到对端节点上。因此,两个节点的数据将不会保持一致。这种协议虽然高效,但是并不能保证数据的可靠性。
2 协议B:内存同步(半同步)复制协议
一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据
可能不会被提交到磁盘数据在本地完成写操作且数据已到达对端节点则认为写操作完成。如果两个节点同时发生故障,即使数据到达对端节点,这种方式同样也会导致在对端节点和本地节点的数据不一致现象,也不具有可靠性。
3 协议C:同步复制协议
只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有任何数据丢失,所以这是一个群集节点的流行模式,但I / O吞吐量依赖于网络带宽。
只有当本地节点的磁盘和对端节点的磁盘都完成了写操作,才认为写操作完成。这是集群流行的一种方式,应用也是最多的,这种方式虽然不高效,但是最可靠。
以上三种协议中,一般使用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,在生产环境使用时须慎重选项使用哪一种协议。[root@primary ~]# systemctl stop firewalld
[root@primary ~]# systemctl disable firewalld
[root@primary ~]# sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
[root@primary ~]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
[root@primary ~]# cat <<EOF | tee -a /etc/hosts
192.168.1.1 primary
192.168.1.2 secondary
[root@secondary ~]# systemctl stop firewalld
[root@secondary ~]# systemctl disable firewalld
[root@secondary ~]# sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/selinux/config
[root@secondary ~]# cat /etc/redhat-release
CentOS Linux release 7.4.1708 (Core)
[root@secondary ~]# cat <<EOF | tee -a /etc/hosts
192.168.1.1 primary
192.168.1.2 secondary[root@primary ~]# yum install kernel-devel kernel kernel-headers -y
[root@primary ~]# reboot
[root@primary ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
[root@primary ~]# yum install drbd84-utils kmod-drbd84 -y
[root@primary ~]# modprobe drbd #加载模块
[root@primary ~]# lsmod | grep drbd
drbd 397041 0
libcrc32c 12644 2 xfs,drbd
[root@secondary ~]# yum install kernel-devel kernel kernel-headers -y
[root@secondary ~]# reboot
[root@secondary ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
[root@secondary ~]# yum install drbd84-utils kmod-drbd84 -y
[root@secondary ~]# modprobe drbd
[root@secondary ~]# lsmod | grep drbd
drbd 397041 0
libcrc32c 12644 2 xfs,drbd[root@primary ~]# cat /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";[root@primary ~]# cp /etc/drbd.d/global_common.conf /etc/drbd.d/global_common.conf.bak
[root@primary ~]# vim /etc/drbd.d/global_common.conf
global {
usage-count no;#不让linbit公司收集目前drbd的使用情况
# minor-count dialog-refresh disable-ip-verification
}
common {
protocol C; #A/B/C复制模式,默认C,数据可靠性高
handlers {#信息处理的一些策略
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when chosing your poison.
# pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
wfc-timeout 240;
degr-wfc-timeout 240;
outdated-wfc-timeout 240;
}
disk {
on-io-error detach; ###同步IO错误的做法:分离该磁盘
}
net {
cram-hmac-alg md5; ##设置加密算法md5
shared-secret "testdrbd"; ##加密密码
}
syncer {
rate 30M; ##传输速率
}
}[root@primary ~]# vim /etc/drbd.d/r0.res
resource r0 {
on primary {
device /dev/drbd0; //这是Primary机器上的DRBD虚拟块设备,事先不要格式化
disk /dev/sdb1;
address 192.168.1.1:7898;
meta-disk internal;
}
on secondary {
device /dev/drbd0; //这是Secondary机器上的DRBD虚拟块设备,事先不要格式化
disk /dev/sdb1;
address 192.168.1.2:7898; //DRBD监听的地址和端口。端口可以自己定义
meta-disk internal;
}
}在Primary机器上添加一块20G的硬盘作为DRBD,分区为/dev/sdb1,不做格式化,并在本地系统创建/data目录,不做挂载操作
[root@primary ~]# fdisk /dev/sdb
依次输入"n->p->1->回车->回车->w"
在Secondary机器上添加一块20G的硬盘作为DRBD,分区为/dev/sdb1,不做格式化,并在本地系统创建/data目录,不做挂载操作
[root@secondary ~]# fdisk /dev/sdb
依次输入"n->p->1->回车->回车->w"
[root@primary ~]# mknod /dev/drbd0 b 147 0
[root@primary ~]# drbdadm create-md r0
initializing activity log
initializing bitmap (640 KB) to all zero
Writing meta data...
New drbd meta data block successfully created.
success
[root@primary ~]# drbdadm create-md r0
You want me to create a v08 style flexible-size internal meta data block.
There appears to be a v08 flexible-size internal meta data block
already in place on /dev/sdb1 at byte offset 21473783808
Do you really want to overwrite the existing meta-data?
[need to type 'yes' to confirm] yes //此处输入yes
initializing activity log
initializing bitmap (640 KB) to all zero
Writing meta data...
New drbd meta data block successfully created.
[root@secondary ~]# mknod /dev/drbd0 b 147 0
[root@secondary ~]# drbdadm create-md r0
initializing activity log
initializing bitmap (640 KB) to all zero
Writing meta data...
New drbd meta data block successfully created.
success
[root@secondary ~]# drbdadm create-md r0
You want me to create a v08 style flexible-size internal meta data block.
There appears to be a v08 flexible-size internal meta data block
already in place on /dev/sdb1 at byte offset 21473783808
Do you really want to overwrite the existing meta-data?
[need to type 'yes' to confirm] yes //此处输入yes
initializing activity log
initializing bitmap (640 KB) to all zero
Writing meta data...
New drbd meta data block successfully created.
[root@primary ~]# systemctl start drbd
[root@primary ~]# systemctl enable drbd
[root@secondary ~]# systemctl start drbd
[root@secondary ~]# systemctl enable drbd
[root@primary ~]# cat /proc/drbd
version: 8.4.11-1 (api:1/proto:86-101)
GIT-hash: 66145a308421e9c124ec391a7848ac20203bb03c build by mockbuild@, 2018-04-26 12:10:42
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20969820
[root@secondary ~]# cat /proc/drbd
version: 8.4.11-1 (api:1/proto:86-101)
GIT-hash: 66145a308421e9c124ec391a7848ac20203bb03c build by mockbuild@, 2018-04-26 12:10:42
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:20969820
[root@primary ~]# drbdsetup /dev/drbd0 primary --force
[root@primary ~]# mkfs.ext4 /dev/drbd0
[root@primary ~]# mkdir /data
[root@primary ~]# mount /dev/drbd0 /data
[root@primary ~]# cd /data/
[root@primary data]# touch haha
[root@primary data]# cd ..
[root@primary /]# umount /data/
[root@primary /]# drbdsetup /dev/drbd0 secondary
[root@secondary ~]# drbdsetup /dev/drbd0 primary
[root@secondary ~]# mkdir /data
[root@secondary ~]# mount /dev/drbd0 /data
[root@secondary ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 48G 1.7G 47G 4% /
devtmpfs 476M 0 476M 0% /dev
tmpfs 488M 0 488M 0% /dev/shm
tmpfs 488M 6.7M 481M 2% /run
tmpfs 488M 0 488M 0% /sys/fs/cgroup
/dev/sda1 197M 132M 65M 67% /boot
tmpfs 98M 0 98M 0% /run/user/0
/dev/drbd0 20G 45M 19G 1% /data
[root@secondary ~]# cd /data/
[root@secondary data]# ls
haha
[root@secondary data]# touch heihei
[root@secondary data]# ls
haha heihei
[root@secondary data]# cd ..
[root@secondary /]# umount /data/
[root@secondary /]# drbdsetup /dev/drbd0 secondary
[root@primary /]# drbdsetup /dev/drbd0 primary
[root@primary /]# mount /dev/drbd0 /data
[root@primary /]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 48G 1.7G 47G 4% /
devtmpfs 476M 0 476M 0% /dev
tmpfs 488M 0 488M 0% /dev/shm
tmpfs 488M 6.7M 481M 2% /run
tmpfs 488M 0 488M 0% /sys/fs/cgroup
/dev/sda1 197M 132M 66M 67% /boot
tmpfs 98M 0 98M 0% /run/user/0
/dev/drbd0 20G 45M 19G 1% /data
[root@primary /]# cd data/
[root@primary data]# ls
haha heihei
[root@primary ~]# yum install rpcbind nfs-utils -y
[root@primary ~]# vim /etc/exports
/data 192.168.1.0/24(rw,sync,no_root_squash)
[root@primary ~]# systemctl start rpcbind
[root@primary ~]# systemctl start nfs
[root@primary ~]# systemctl enable rpcbind
[root@primary ~]# systemctl enable nfs
[root@secondary ~]# yum install rpcbind nfs-utils -y
[root@secondary ~]# vim /etc/exports
/data 192.168.1.0/24(rw,sync,no_root_squash)
[root@secondary ~]# systemctl start rpcbind
[root@secondary ~]# systemctl start nfs
[root@secondary ~]# systemctl enable rpcbind
[root@secondary ~]# systemctl enable nfs
[root@primary ~]# yum install keepalived -y
[root@secondary ~]# yum install keepalived -y
primary
[root@primary ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id DRBD_HA_MASTER
}
vrrp_script chk_nfs {
script "/etc/keepalived/check_nfs.sh"
interval 5
}
vrrp_instance VI_1 {
state MASTER
interface eth1
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
track_script {
chk_nfs
}
notify_stop /etc/keepalived/notify_stop.sh
notify_master /etc/keepalived/notify_master.sh
virtual_ipaddress {
192.168.1.20
}
}
secondary
[root@secondary ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id DRBD_HA_BACKUP
}
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
notify_master /etc/keepalived/notify_master.sh
notify_backup /etc/keepalived/notify_backup.sh
virtual_ipaddress {
192.168.1.20
}
}
此脚本只在Primary机器上配置
[root@primary ~]# vim /etc/keepalived/check_nfs.sh
#!/bin/bash
# 检查nfs可用性:进程和是否能够挂载
systemctl status nfs &>/dev/null
if [ $? -ne 0 ];then
# 如果服务状态不正常,先尝试重启服务
systemctl restart nfs
systemctl status nfs &>/dev/null
if [ $? -ne 0 ];then
# 若重启nfs服务后,仍不正常
# 卸载drbd设备
umount /dev/drbd0
# 将drbd主降级为备
drbdadm secondary r0
# 关闭keepalived
systemctl stop keepalived
fi
fi
[root@primary ~]# chmod 0755 /etc/keepalived/check_nfs.sh
此脚本只在Primary机器上配置
[root@primary ~]# mkdir /etc/keepalived/logs
[root@primary ~]# vim /etc/keepalived/notify_stop.sh
#!/bin/bash
time=`date "+%F %H:%M:%S"`
echo -e "$time ------notify_stop------\n" >> /etc/keepalived/logs/notify_stop.log
systemctl stop nfs &>> /etc/keepalived/logs/notify_stop.log
/bin/umount /data &>> /etc/keepalived/logs/notify_stop.log
/sbin/drbdadm secondary r0 &>> /etc/keepalived/logs/notify_stop.log
echo -e "\n" >> /etc/keepalived/logs/notify_stop.log
[root@primary ~]# chmod 0755 /etc/keepalived/notify_stop.sh
此脚本在两台机器上都要配置
[root@primary ~]# vim /etc/keepalived/notify_master.sh
[root@secondary ~]# vim /etc/keepalived/notify_master.sh
#!/bin/bash
time=`date "+%F %H:%M:%S"`
echo -e "$time ------notify_master------\n" >> /etc/keepalived/logs/notify_master.log
/sbin/drbdadm primary r0 &>> /etc/keepalived/logs/notify_master.log
/bin/mount /dev/drbd0 /data &>> /etc/keepalived/logs/notify_master.log
systemctl restart nfs &>> /etc/keepalived/logs/notify_master.log
echo -e "\n" >> /etc/keepalived/logs/notify_master.log
[root@primary ~]# chmod 0755 /etc/keepalived/notify_master.sh
[root@secondary ~]# chmod 0755 /etc/keepalived/notify_master.sh
此脚本只在Secondary机器上配置
[root@secondary ~]# mkdir /etc/keepalived/logs
[root@secondary ~]# vim /etc/keepalived/notify_backup.sh
#!/bin/bash
time=`date "+%F %H:%M:%S"`
echo -e "$time ------notify_backup------\n" >> /etc/keepalived/logs/notify_backup.log
systemctl stop nfs &>> /etc/keepalived/logs/notify_backup.log
/bin/umount /dev/drbd0 &>> /etc/keepalived/logs/notify_backup.log
/sbin/drbdadm secondary r0 &>> /etc/keepalived/logs/notify_backup.log
echo -e "\n" >> /etc/keepalived/logs/notify_backup.log
[root@secondary ~]# chmod 0755 /etc/keepalived/notify_backup.sh
[root@primary ~]# systemctl start keepalived
[root@primary ~]# systemctl enable keepalived
[root@secondary ~]# systemctl start keepalived
[root@secondary ~]# systemctl enable keepalived
[root@emm ~]# yum install rpcbind nfs-utils -y
[root@emm ~]# systemctl start rpcbind
[root@emm ~]# mount -t nfs 192.168.1.20:/data /data
[root@emm ~]# vim /etc/fstab
192.168.1.20:/data /data nfs defaults 0 0
ansible backup -m shell -a "hostnamectl set-host backup"
ansible backup -m shell -a "hostnamectl set-hostname backup"
vim /etc/hosts
ansible all -m copy -a "src=/etc/hosts dest=/etc/hosts"
ansible all -m shell -a "hostname -i"
vim ifcfg-eth1.j2
vim setip.yml
ansible-playbook setip.yml
vim setip.yml
ansible-playbook setip.yml
ip l s mtu 1450 dev eth1
ip a a 192.168.1.100/16 brd 192.168.255.255 dev eth1
ifup eth1
ip l set up dev eth1
ansible all -m service -a "name=firewalld state=stopped enabled=false"
ansible all -m yum -a "name=kernel-devel,kernel,kernel-headers"
ansible all -m shell -a "sed -i s/=enforcing/=disabled/g /etc/selinux/config"
ansible all -m shell -a "reboot"
ssh root@192.168.1.1 "dhclient eth0"
ansible -m ping
ansible all -m ping
ansible all -m shell -a "rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm"
echo "安装drdb模块"
ansible all -m yum -a "name=drbd84-utils,kmod-drbd84"
echo "加载drdb模块"
ansible all -m shell -a "modprobe drbd"
vim hosts
ansible all -m ping
ansible all -m shell -a "dhclient eth0"
ansible all -m shell -a "reboot"
ansible all -m shell -a "dhclient eth0"
ansible all -m shell -a "modprobe drbd"
ansible all -m service -a "name=drbd stated=started"
ansible all -m service -a "name=drbd state=started"
ansible all -m shell -a "cat /proc/drbd "
ansible all -m yum -a "name=rpcbind,nfs-utils"
ansible all -m service -a "name=rpcbind state=started enabled=true"
ansible all -m service -a "name=nfs state=started enabled=true"
ansible all -m yum -a "name=keepalived state=installed"
ansible all -m service -a "name=keepalived state=started enabled=true"
yum install rpcbind nfs-utils -y
systemctl start rpcbind
mount -t nfs 192.168.1.20:/data /data
mkdir /data
mount -t nfs 192.168.1.20:/data /data
ansible all -m shell -a "echo '/data 192.168.1.0/16(rw,sync,no_root_squash)' >>/etc/exports"
ansible all -m service -a "name=nfs state=restarted"
mount -t nfs 192.168.1.20:/data /data
[root@manage mansible]# ls
ansible.cfg hosts ifcfg-eth1.j2 setip.yml testnfsalive.sh
[root@manage mansible]# cat *
ansible.cfg
[defaults]
inventory=hosts
host_key_checking=False
hosts
[master]
192.168.1.1
[backup]
192.168.1.2
[nfs:children]
master
backup
[nfs:vars]
ansible_ssh_user=root
ansible_ssh_pass=Abcabc123
ifcfg-eth1.j2
DEVICE=eth1
ONBOOT=yes
NM_CONTROLLED=no
BOOTPROTO=static
IPADDR={{ipinfo['stdout']}}
NETMASK=255.255.0.0
IPV6INIT=no
MTU=1450
setip.yml
---
- hosts: all
remote_user: root
tasks:
- name: register ip
shell: hostname -i
register: ipinfo
- name: cpIpconf
template: src=ifcfg-eth1.j2 dest=/etc/sysconfig/network-scripts/ifcfg-eth1
# notify:
# # - up eth1
# #
# # handlers:
# # - name: up eth1
# # shell: /usr/sbin/ifup eth1
# #
- name: up eth1
shell: ifup eth1
testnfsalive.sh
#!/bin/bash
while [ 1 -eq 1 ]
do
echo `date`
echo `date` >>/data/date
sleep 1
done
实际上是指在某种情况下,造成drbd的两个节点断开了连接,都以primary的身份来运行。当drbd某primary节点连接对方节点准备发送信息的时候如果发现对方也是primary状态,那么会会立刻自行断开连接,并认定当前已经发生split brain了,这时候他会在系统日志中记录以下信息:“Split-Brain detected,dropping connection!”
当发生split brain之后,如果查看连接状态,其中至少会有一个是StandAlone状态,另外一个可能也是StandAlone(如果是同时发现split brain状态),也有可能是WFConnection的状态。 drbdmon 查看状态
drbdadmin status
处理
查看日志发现脑裂
tail -n 12 /var/log/messages
Sep 21 11:19:53 lab4 kernel: block drbd0: Split-Brain detected but unresolved, dropping connection!
Sep 21 11:19:53 lab4 kernel: block drbd0: helper command: /sbin/drbdadm split-brain minor-0
Sep 21 11:19:53 lab4 kernel: block drbd0: helper command: /sbin/drbdadm split-brain minor-0 exit code 0 (0x0)
Sep 21 11:19:53 lab4 kernel: block drbd0: conn( WFReportParams -> Disconnecting )
Sep 21 11:19:53 lab4 kernel: block drbd0: error receiving ReportState, l: 4!
Sep 21 11:19:53 lab4 kernel: block drbd0: meta connection shut down by peer.
Sep 21 11:19:53 lab4 kernel: block drbd0: asender terminated
Sep 21 11:19:53 lab4 kernel: block drbd0: Terminating drbd0_asender
Sep 21 11:19:53 lab4 kernel: block drbd0: Connection closed
Sep 21 11:19:53 lab4 kernel: block drbd0: conn( Disconnecting -> StandAlone )
Sep 21 11:19:53 lab4 kernel: block drbd0: receiver terminated
Sep 21 11:19:53 lab4 kernel: block drbd0: Terminating drbd0_receiver
保留主节点数据,丢弃从节点数据.
主节点执行:
? #设置主节点
? drbdadm primary r0
? mount /dev/drbd0 /data
ls -lh /data 查看文件情况
从节点执行:
? #设置自己为从节点
? drbdadm secondary r0
? drbdadm -- --discard-my-data connect r0 #丢弃自己数据
? drbdadm connect r0 手动连接主资源节点
经过测试 故障切换大概10s左右不可用时间.
该内容来自大神博客:https://www.mrlapulga.com/?p=365
参考
https://blog.csdn.net/sfdst/article/details/77879684
https://blog.csdn.net/tjiyu/article/details/52723125
标签:receive eset disco HCL sed 丢失 new writing 建立
原文地址:https://www.cnblogs.com/lovesKey/p/11371228.html