标签:enable keep mon Collector set sla ops compute stand
随着业务的发展,数据量剧增,我们一些简单报表大盘类的任务,就不能简单的依赖于RDBMS了,而是依赖于数仓之类的大数据平台。
数仓有着巨量数据的存储能力,但是一般都存在一定数据延迟,所以要想完全依赖数数仓来解决实时报表问题,是困难的。
其实,所谓的实时报表,往简单了说就是: 对现在的一些数据进行加减乘除聚合后,得到的一串与时间相关的数字。
所以,这类问题的关键点应该在于这个实时数据怎么来,以及怎么处理这些实时数据。
一般地,做这类报表类工作,最基本的原则就是: 业务无侵入性,然后又要做到实时。
所以,本能性地想到,使用消息中间件来解耦这个数据就好了,Kafka 可能是个比较好的选择。当然,这个前提是业务技术都是使用这一套东西的,如果没有,则可能想另外的招了,比如: binlog 解析?
有了数据来源之后,我们就可以做相应的报表数据了。
前面既然提到,报表基本上就是进行简单的加减乘除,那就是很简单了呗。
也就是,自己起几个kafka消费者,然后消费数据,运算后,得到结果,然后存入DB中,而已。
所以,完全可以去做这么一件事。但是你知道,凡事不会那么简单,你要处理多少异常:时间边界问题,宕机问题,业务新增问题。。。
不多说了,回到本文正题:像这类场景,其实就是简单的流处理流计算而已,早已相应的开发模块被提炼出来,咱们只要学会使用就好了。
Flink是其中做得比较好的一个框架,据说也是未来的一个趋势。既然如此,何不学他一学。
Flink,流计算,感觉挺难啊!
其实不然,就像前面我们提到解决方案一样,入门就是这么简单。
好,接下来我们通过一个 flink-demo,试着入门一下!
解释:
1. 以下demo的应用场景是: 统计1分钟类的渠道下单数量;
2. 数据源源为kakfa;
3. 数据输出存储为kafka和控制台;
真实的代码如下:
package com.my.flink.kafka.consumer; import com.my.flink.config.KafkaConstantProperties; import com.my.flink.kafka.serializer.KafkaTuple4StringSchema; import org.apache.flink.api.java.tuple.Tuple4; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010; import org.apache.flink.streaming.util.serialization.SimpleStringSchema; import java.util.Properties; import java.util.concurrent.TimeUnit; /** * 用java 写消费者 * */ public class ConsumeKafkaByJava { private static final String CONSUMER_GROUP_ID = "test.flink.consumer1"; public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // env.enableCheckpointing(1000); Properties kafkaProps = new Properties(); kafkaProps.setProperty("bootstrap.servers", KafkaConstantProperties.KAFKA_BROKER); kafkaProps.setProperty("group.id", CONSUMER_GROUP_ID); FlinkKafkaConsumer010<String> myConsumer = new FlinkKafkaConsumer010<String>( KafkaConstantProperties.FLINK_COMPUTE_TOPIC_IN1, new SimpleStringSchema(), kafkaProps); DataStream<String> dataStream = env.addSource(myConsumer); // 四元组数据为: 订单号,统计维度标识,订单数,订单金额 DataStream<Tuple4<String, String, Integer, Double>> counts = dataStream .flatMap(new TestBizDataLineSplitter()) .keyBy(1) .timeWindow(Time.of(30, TimeUnit.SECONDS)) .reduce((value1, value2) -> { return new Tuple4<>(value1.f0, value1.f1, value1.f2 + value2.f2, value1.f3 + value2.f3); }); // 暂时输入与输出相同 counts.addSink(new FlinkKafkaProducer010<>( KafkaConstantProperties.FLINK_DATA_SINK_TOPIC_OUT1, new KafkaTuple4StringSchema(), kafkaProps) ); // 统计值多向输出 dataStream.print(); counts.print(); env.execute("Test Count from Kafka data"); } }
如上,就是一个 flink 的统计代码了,简单不?肯定简单!
不过,单这个东西肯定是跑不起来的,我们还需要框架基础依赖附加模板工作,不过这些真的只是 copy 而已哦。
1. pom.xml 依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.my.flink</groupId> <artifactId>flink-kafka-test</artifactId> <version>1.0-SNAPSHOT</version> <inceptionYear>2008</inceptionYear> <properties> <scala.version>2.11.6</scala.version> </properties> <repositories> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </pluginRepository> </pluginRepositories> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.4</version> <scope>test</scope> </dependency> <dependency> <groupId>org.specs</groupId> <artifactId>specs</artifactId> <version>1.2.5</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>1.3.2</version> <scope>compile</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka-0.10_2.11 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.10_2.11</artifactId> <version>1.3.2</version> <scope>compile</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka_2.11 --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.11</artifactId> <version>0.10.2.0</version> <scope>compile</scope> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.3.0</version> <scope>compile</scope> </dependency> <!-- flink-streaming的jar包,2.11为scala版本号 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>1.3.2</version> <scope>compile</scope> </dependency> <!-- <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>1.3.2</version> <scope>compile</scope> </dependency>--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.59</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <useUniqueVersions>false</useUniqueVersions> <classpathPrefix>lib/</classpathPrefix> <mainClass>com.my.flink.kafka.consumer.ConsumeKafkaByJava</mainClass> </manifest> </archive> </configuration> </plugin> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.5</arg> </args> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-eclipse-plugin</artifactId> <configuration> <downloadSources>true</downloadSources> <buildcommands> <buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand> </buildcommands> <additionalProjectnatures> <projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature> </additionalProjectnatures> <classpathContainers> <classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer> <classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer> </classpathContainers> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>2.4.1</version> <configuration> <!-- get all project dependencies --> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <!-- MainClass in mainfest make a executable jar --> <archive> <manifest> <mainClass>com.my.flink.kafka.consumer.ConsumeKafkaByJava</mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <!-- bind to the packaging phase --> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> <reporting> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <configuration> <scalaVersion>${scala.version}</scalaVersion> </configuration> </plugin> </plugins> </reporting> </project>
2. 另外再加几个辅助类:
// 1. package com.my.flink.config; /** * kafka 相关常量定义 * */ public class KafkaConstantProperties { /** * kafka broker 地址 */ public static final String KAFKA_BROKER = "127.0.0.1:9092"; /** * zk 地址,低版本 kafka 使用,高版本已丢弃 */ public static final String ZOOKEEPER_HOST = "master:2181,slave1:2181,slave2:2181"; /** * flink 计算使用topic 1 */ public static final String FLINK_COMPUTE_TOPIC_IN1 = "mastertest"; /** * flink消费结果,输出到kafka, topic 数据 */ public static final String FLINK_DATA_SINK_TOPIC_OUT1 = "flink_compute_result_out1"; } // 2. package com.my.flink.kafka.formatter; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple4; import org.apache.flink.util.Collector; import java.math.BigDecimal; /** * 原始消息参数处理类 * */ public final class TestBizDataLineSplitter implements FlatMapFunction<String, Tuple4<String, String, Integer, Double>> { private static final long serialVersionUID = 1L; /** * 进行 map 阶段展开操作 * * @param value 原始值: bizData: 2019-08-01 17:39:32, * P0001,channel1,201908010116100001,100 * * dateTimeMin, * productCode, channel, * orderId, money * [, totalCount, totalMoney] * * @param out 输出值, 用四元组保存 * */ @Override public void flatMap(String value, Collector<Tuple4<String, String, Integer, Double>> out) { String[] tokens = value.split(","); String time = tokens[0].substring(0, 16); String uniqDimKey = time + "," + tokens[1] + "," + tokens[2]; // totalCount: 1, totalPremium: premium // todo: 写成 pojo out.collect(new Tuple4<>(tokens[3], uniqDimKey, 1, Double.valueOf(tokens[4]))); } } // 3. package com.my.flink.kafka.serializer; import org.apache.flink.api.common.typeinfo.TypeInformation; import org.apache.flink.api.java.tuple.Tuple4; import org.apache.flink.streaming.util.serialization.DeserializationSchema; import org.apache.flink.streaming.util.serialization.SerializationSchema; import java.nio.charset.Charset; import java.nio.charset.StandardCharsets; import static org.apache.flink.util.Preconditions.checkNotNull; /** * kafka 自定义序列化器 */ public class KafkaTuple4StringSchema implements DeserializationSchema<Tuple4<String, String, Integer, Double>>, SerializationSchema<Tuple4<String, String, Integer, Double>> { private static final long serialVersionUID = -5784600791822349178L; // ------------------------------------------------------------------------ // Kafka Serialization // ------------------------------------------------------------------------ /** The charset to use to convert between strings and bytes. * The field is transient because we serialize a different delegate object instead */ private transient Charset charset; private String separator = ","; /** * Creates a new SimpleStringSchema that uses "UTF-8" as the encoding. */ public KafkaTuple4StringSchema() { this(StandardCharsets.UTF_8); } /** * Creates a new SimpleStringSchema that uses the given charset to convert between strings and bytes. * * @param charset The charset to use to convert between strings and bytes. */ public KafkaTuple4StringSchema(Charset charset) { this.charset = checkNotNull(charset); } @Override public Tuple4<String, String, Integer, Double> deserialize(byte[] message) { String rawData = new String(message, StandardCharsets.UTF_8); String[] dataArr = rawData.split(separator); return new Tuple4<>(dataArr[0], dataArr[1], Integer.valueOf(dataArr[2]), Double.valueOf(dataArr[3])); } @Override public boolean isEndOfStream(Tuple4<String, String, Integer, Double> nextElement) { return false; } @Override public byte[] serialize(Tuple4<String, String, Integer, Double> element) { return (element.f0 + separator + element.f1 + separator + element.f2 + separator + element.f3).getBytes(); } @Override public TypeInformation<Tuple4<String, String, Integer, Double>> getProducedType() { return null; } }
这样,加上上面的 demo, 其实就可以跑起来了。
下面我们从demo里看看 flink 的开发套路:
// 1. 获取运行环境 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 配置接入数据源 Properties kafkaProps = new Properties(); kafkaProps.setProperty("bootstrap.servers", KafkaConstantProperties.KAFKA_BROKER); kafkaProps.setProperty("group.id", CONSUMER_GROUP_ID); FlinkKafkaConsumer010<String> myConsumer = new FlinkKafkaConsumer010<String>( KafkaConstantProperties.FLINK_COMPUTE_TOPIC_IN1, new SimpleStringSchema(), kafkaProps); DataStream<String> dataStream = env.addSource(myConsumer); // 3. 处理数据 DataStream<Tuple4<String, String, Integer, Double>> counts = dataStream .flatMap(new ProposalBizDataLineSplitter()) .keyBy(1) .timeWindow(Time.of(30, TimeUnit.SECONDS)) .reduce((value1, value2) -> { return new Tuple4<>(value1.f0, value1.f1, value1.f2 + value2.f2, value1.f3 + value2.f3); }); // 4. 输出处理结果 counts.addSink(new FlinkKafkaProducer010<>( KafkaConstantProperties.FLINK_DATA_SINK_TOPIC_OUT1, new KafkaTuple4StringSchema(), kafkaProps) ); // 统计值多向输出 dataStream.print(); counts.print(); // 5. 正式提交运行 env.execute("Test Count from Kafka data");
其实就5个步骤,而且自己稍微想想,除了第5个步骤外,这些也都是必须的东西,再无多余了。
1. 获取运行环境
2. 配置接入数据源
3. 处理数据
4. 输出处理结果
5. 正式提交运行
所以,你觉得复杂吗?除了那些模板?(模板从来都是复制)
所以,我们可以随意使用这些框架来帮我们处理事务吗?
你还得看下公司的环境:比如 资金支持、运维支持、框架支持?
总之,入门很简单,但不要以为真简单!(保持敬畏之心)
接下来,我们来看一下关于Flink的一些架构问题:
和大多数的大数据处理框架一样,Flink也是一种 master-slave 架构;如图:
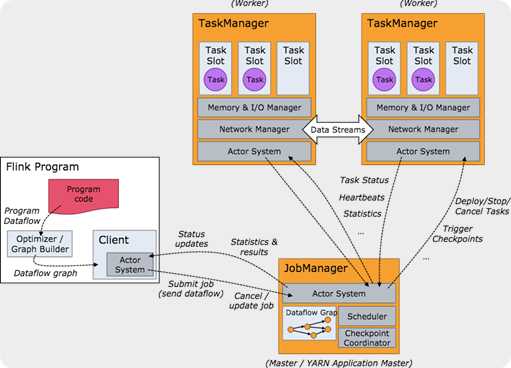
简单点说就是,flink 是一套自管理的运行环境,你只需按照flink范式编写代码,提交到集群运行即可。
Flink 抽象层级:
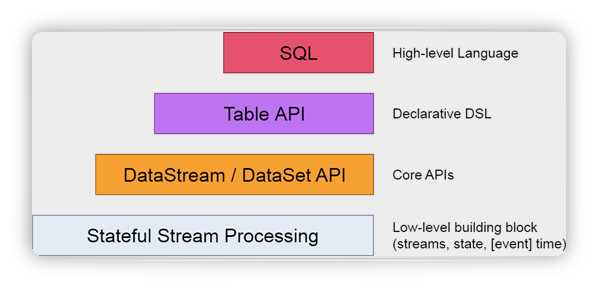
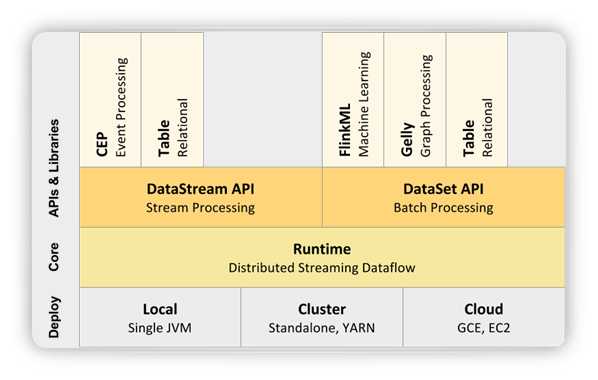
Flink 的重要特性:
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口操作
支持有状态计算的Exactly-once语义
支持高度灵活的窗口操作,支持基于time、count、session,以及data-driven的窗口操作
支持具有Backpressure功能的持续流模型
支持基于轻量级分布式快照实现的容错
支持批流合一处理
Flink在JVM内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
支持Table-API的操作
支持SQL式友好开发
重要概念解释:
Watermark: 是一种衡量Event Time进展的机制,它是数据本身的一个隐藏属性;包含: eventTime / IngestionTime / processTime
DataStream 流处理, DataSet 批处理;
Window: TumblingWindow / SlidingWindow / SessionWindow / CountWindow
Map: 一对一映射数据流,flatMap: 一对N数据流映射;
Filter: 过滤返回false的数据,keyBy: 将相同key的DataStream分配到同一分区以便进行聚合计算, reduce: 将数据合并为一个新的数据;
Sink: 输出,RichSinkFunction 实现自定义输出;基于文件的:如 writeAsText()、writeAsCsv()、writeUsingOutputFormat、FileOutputFormat。 写到socket: writeToSocket。 用于显示的:print、printToErr。 自定义Sink: addSink。connectors 用于给接入第三方数据提供接口,现在支持的connectors 包括:Apache Kafka/Apache Cassandra/Elasticsearch/Hadoop FileSystem/RabbitMQ/Apache NiFi
SnapShot:由于 Flink 的 checkpoint 是通过分布式快照实现的,接下来我们将 snapshot 和 checkpoint 这两个词交替使用。由于 Flink checkpoint 是通过分布式 snapshot 实现的,snapshot 和 checkpoint 可以互换使用。
Backpressure: 反压通常产生于这样的场景:短时负载高峰导致系统接收数据的速率远高于它处理数据的速率。许多日常问题都会导致反压,例如,垃圾回收停顿可能会导致流入的数据快速堆积,或者遇到大促或秒杀活动导致流量陡增。反压如果不能得到正确的处理,可能会导致资源耗尽甚至系统崩溃。
唠叨: 方向。
标签:enable keep mon Collector set sla ops compute stand
原文地址:https://www.cnblogs.com/yougewe/p/11371676.html