标签:pool 字节 log 问题 monitor 更换 是否一致 mem read
Redis复制的原理和优化
主从复制
slave会通过被复制同步master上面的数据,形成数据副本
当master节点宕机时,slave可以升级为master节点承担写操作。
允许有一主多从,slave可以承担读操作,提高读性能,master承担写操作。即达到读写分离
性质
一个master可以有多个slave
每个slave只能有一个master
每个slave也可以有自己的多个slave
数据流是单向的,从master到slave
创建主从命令
slaveof ${masterIP} ${masterPort}
在希望成为slave的节点中执行以下命令,此过程会异步地将master节点中的数据全量地复制到当前节点中
配置
salveof ${masterIP} ${masterPort} 设置当前节点作为其他节点的slave节点
slave-read-only yes 设置当前slave节点是只读的,不会执行写操作
取消主从的方式
salveof no one 在不希望作为slave的节点中执行以下命令
执行完成之后,该节点的数据不会被清除。而是不会再同步master中的数据
主从配置应用
复制一个从机
cd /usr/local/redis 1.复制一个从机 cp bin/bin2 -r 2.修改从机的redis.conf slaveof 192.168.239.149 6379 3.修改从机的port为6380 port 6380 4.rm -rf appendonly.aof dump.rdb 5.已配置文件启动从机 ./redis-server redis.conf
主机一旦发生增删改操作,那么主机会将数据同步到从机中
从机不能执行写操作
查看当前节点是否主从
info replication
run_id与偏移量
run_id是Redis 服务器的随机标识符,用于 Sentinel 和集群,服务重启后就会改变
当slave节点复制时发现和之前的 run_id 不同时,将会对数据进行全量同步
查看runid
1 redis-cli -p 6379 info server | grep run 2 3 run_id:345dda992e5064bc80e01f96ea90f729b722b2ea
偏移量
通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
参与复制的主从节点都会维护自身的复制偏移量。主节点(master)在处理完写命令后,会把命令的字节长度做累加记录,统计信息在info replication中的master_repl_offset指标中。
从节点每秒上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量
从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计在info replication中的slave_repl_offset指标中
全量复制
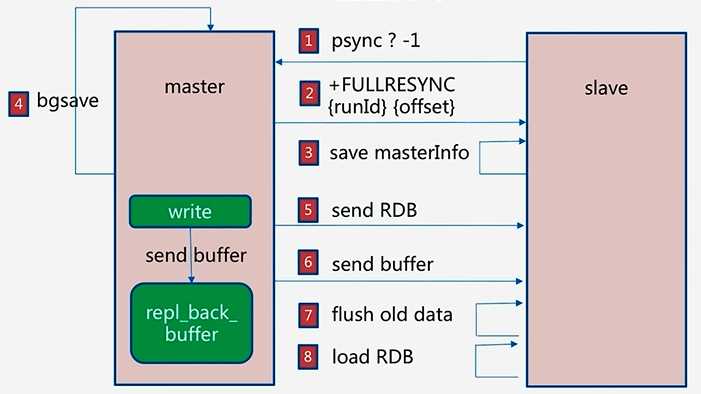
流程
1 1.slave -> master : psync ? -1 2 3 ? 代表当前slave节点不知道master节点的runid 4 -1代表当前slave节点的偏移量为-1 5 6 2.master -> slave : +FULLRESYNC runId offset 7 8 master通知slave节点需要进行全量复制 9 runId:master发送自身节点的runId给slave节点 10 offset:master发送自身节点的offset给slave节点 11 12 3.slave : save masterInfo 13 14 slave节点保存master节点的相关信息(runId与偏移量) 15 16 4.master : bgsave 17 18 master节点通过bgsave命令进行RDB操作 19 20 5.master -> slave : send RDB 21 22 master将bgsave完的RDB结果发送给slave节点 23 24 6.master -> slave : send buffer 25 26 master在执行写操作时,会将写命令写入repl_back_buffer中 27 为了维护bgsave过程中执行的写操作命令,并同步给slave,master将期间的buffer发送给slave。 28 29 7.slave : flush old data 30 31 slave节点将之前的数据全部清空 32 33 8.load RDB 34 35 slave节点加载RDB
全量复制的开销
bgsave时间
RDB文件网络传输时间
slave节点清空数据时间
slave节点加载RDB的时间
可能的AOF重写时间,当加载完RDB之后,如果开启了AOF重写,需要重写AOF,以保证AOF最新
在redis4.0中,优化了psync,简称psync2,实现了即使redis实例重启的情况下也能实现部分同步
部分复制
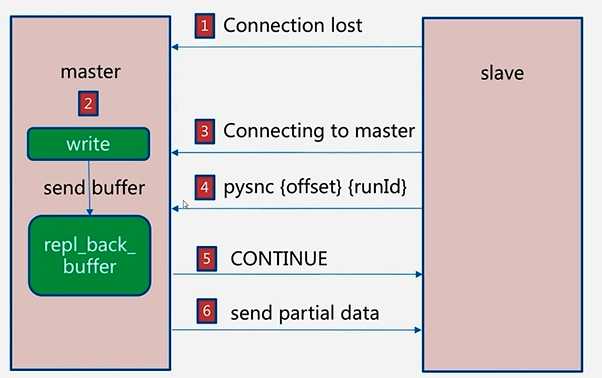
流程
1 1.slave -> master : Connection lost 2 3 由于网络抖动等原因,slave对master的网络连接发生中断 4 5 2.slave -> master : Connection to master 6 7 slave重新建立与master节点的连接 8 9 3.slave -> master : psync runId offset 10 11 slave节点发送master节点的runId以及自身的offset 12 13 4.master -> slave :CONTINUE 14 15 在第3步中,master节点校验offset,在当前buffer的范围中,则将反馈从节点CONTINUE表示部分复制。 16 如果offset不在当前buffer的范围中,则将反馈从节点FULLRESYNC表示需要全量复制 17 buffer的大小默认为1MB,由repl_back_buffer维护 18 19 5.master -> slave : send partial data 20 21 发送部分数据给slave节点让slave节点完成部分复制
故障处理
slave宕机故障
会影响redis服务的整体读性能,对系统可用性没有影响,将slave节点重新启动并执行slaveof即可。
master宕机故障
redis将无法执行写请求,只有slave节点能执行读请求,影响了系统的可用性
随机找一个节点,执行slaveof no one,使其成为master节点
然后对其他slave节点执行slaveof newMatserIp newMasterPort
重启master节点,它将会重新成为master
常见问题
读写分离
master只承担写请求,读请求分摊到slave节点执行
复制数据延迟
当写操作从master同步到slave的时候,会有很短的延迟
当网络原因或者slave阻塞时,会有比较长的延迟
在这种情况下,可以通过配置一个事务中的读写都在主库得已实现
可以通过偏移量对这类问题进行监控
读到过期数据(在v3.2中已经解决)
删除过期数据的策略1:操作key的时候校验该key是否过期,如果已经过期,则删除
删除过期数据的策略2:redis内部有一个定时任务定时检查key有没有过期,如果采样的速 度比不上过 期数据的产生速度,会导致很多过期数据没有被删除。
在redis集群中,有一个约定,slave节点只能读取数据,而不能操作数据
从节点故障
配置不一致
maxmemory不一致:可能会丢失数据
数据结构优化参数(例如hash-max-ziplist-entries):导致内存不一致
规避全量复制
第一次全量复制
第一次不可避免
小主节点,低峰处理(夜间)
节点运行ID不匹配
主节点重启(运行ID变化)
可以使用故障转移进行处理,例如哨兵或集群。
复制积压缓冲区不足
如果offset在缓冲区之内,则可以完成部分复制,否则需要全量复制
可以增大复制缓冲区的大小:rel_backlog_size,默认1M,可以提升为10MB
规避复制风暴
1.单主节点复制风暴
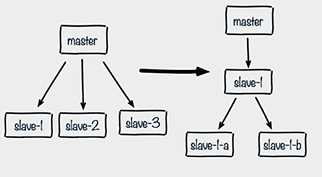
主节点重启,多从节点复制
更换复制拓扑,由(m-s1,s2,s3)的模式改成(m-s1-s1a,s1b)的模式,可以减轻master的压力
2.单机器复制风暴
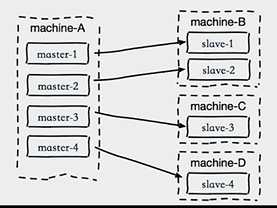
机器宕机后,大量全量复制
主节点分散多机器
Redis Sentinel 架构
主从复制的问题
当master节点发生故障时,需要手动进行故障转移
写能力与存储能力受限,写能力和存储能力都依赖于master节点
在主从复制的基础上,新增多个Redis Sentinel节点,这些Sentinel不存储任何的数据。这些Sentinel节点会完成Redis的故障判断并故障转移的处理,然后通知客户端。一套Redis Sentinel集群可以监控多套Redis主从,每一套Redis主从通过master-name作为标识。
客户端不直接连接Redis服务,而连接Redis Sentinel。在Redis Sentinel中清楚哪个节点是master节点
故障转移流程
1. 多个Sentinel发现并确认master有问题
2. 选举出一个Sentinel作为领导
3. 选出一个slave作为master
4. 通知其余slave成为新的master的slave
5. 通知客户端主从发生的变化
6. 等待老的master复活成为新master的slave
Redis Sentinel的相关配置
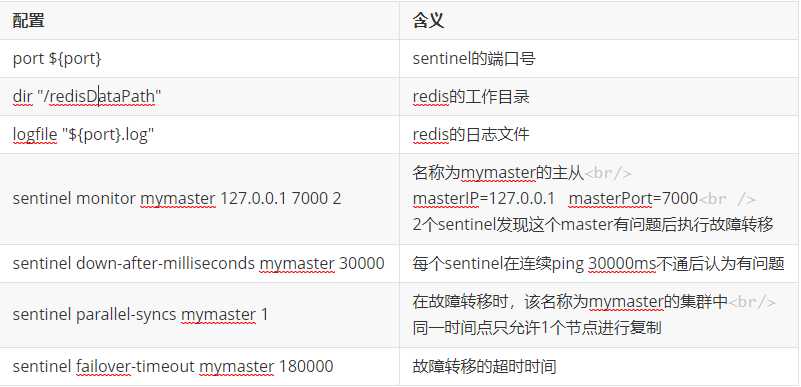
查看去除注释和空格的配置文件
cat xxx.conf | grep -v "#" | grep -v "^$"
redis sentinel 的安装和配置
1 新建config目录 2 3 redis-7000.conf 4 5 port 7000 6 daemonize yes 7 pidfile /var/run/redis-7000.pid 8 logfile "7000.log" 9 dir /redisDataPath 10 11 12 13 redis-7001.conf 14 15 port 7001 16 daemonize yes 17 pidfile /var/run/redis-7001.pid 18 logfile "7001.log" 19 dir /redisDataPath 20 slaveof 127.0.0.1 7000 21 22 redis-7002.conf 23 24 port 7002 25 daemonize yes 26 pidfile /var/run/redis-7002.pid 27 logfile "7002.log" 28 dir /redisDataPath 29 slaveof 127.0.0.1 7000 30 31 #如若master设置了认证密码,那么所有redis数据节点都配置上masterauth属性 32 masterauth "myredis" 33 34 节点启动 35 redis-server redis-7000.conf 36 redis-server redis-7001.conf 37 redis-server redis-7002.conf
开启sentinel监控主节点
2 3 redis-26379.conf 4 5 port 26379 6 daemonize yes 7 dir "/redisDataPath" 8 logfile "26379.log" 9 sentinel monitor mymaster 127.0.0.1 7000 2 10 sentinel down-after-milliseconds mymaster 30000 11 sentinel parallel-syncs mymaster 1 12 sentinel failover-timeout mymaster 180000 13 14 15 redis-26380.conf 16 17 port 26380 18 daemonize yes 19 dir "/redisDataPath" 20 logfile "26380.log" 21 sentinel monitor mymaster 127.0.0.1 7000 2 22 sentinel down-after-milliseconds mymaster 30000 23 sentinel parallel-syncs mymaster 1 24 sentinel failover-timeout mymaster 180000 25 26 27 redis-26381.conf 28 29 port 26381 30 daemonize yes 31 dir "/redisDataPath" 32 logfile "26381.log" 33 sentinel monitor mymaster 127.0.0.1 7000 2 34 sentinel down-after-milliseconds mymaster 30000 35 sentinel parallel-syncs mymaster 1 36 sentinel failover-timeout mymaster 180000 37 38 39 #redis数据master节点设置了认证,则需要如下配置 40 sentinel auth-pass mymaster myredis 41 42 启动 43 redis-sentinel sentinel-23679.conf 44 redis-sentinel sentinel-23679.conf 45 redis-sentinel sentinel-23679.conf 46 47 > sentinel masters //查看主服务信息 48 > sentinel slaves mymaster //查看所有从服务信息
客户端的接入
1 Set<String> sentinelSet = new HashSet<String>() {{ 2 add("127.0.0.1:26379"); 3 add("127.0.0.1:26380"); 4 add("127.0.0.1:26381"); 5 }}; 6 JedisPoolConfig poolConfig = new JedisPoolConfig(); 7 String masterName = "myMaster"; 8 int timeout = 30_000; //jedis连接sentinel的超时时间 9 JedisSentinelPool sentinelPool = new JedisSentinelPool( 10 masterName , sentinelSet , poolConfig , timeout); 11 Jedis jedis = sentinelPool.getResource(); 12 jedis.close();
三个定时任务
每10秒每个sentinel对master和slave执行info
发现slave节点
确认主从关系
每2秒每个sentinel通过mster节点的channel交换信息(pub/sub)
通过__sentinel__:hello频道交互
交互对节点的“看法”和自身信息
每1秒每个sentinel对其他sentinel和redis执行ping
主观下线与客观下线
主观下线:每个sentinel节点对Redis节点失败的看法。
sentinel down-after-milliseconds masterName timeout
每个sentinel节点每秒会对Redis节点进行ping,当连续timeout毫秒之后还没有得到PONG,则sentinel认为redis下线。
客观下线:所有sentinel节点对Redis节点失败达成共识。
sentinel monitor masterName ip port quorum
大于等于quorum个sentinel主观认为Redis节点失败下线
通过sentinel is-master-down-by-addr提出自己认为Redis master下线
领导者选举
只有sentinel节点完成故障转移
选举:通过 sentinel is-master-down-by-addr 命令都希望成为领导者
每个主观下线的sentinel节点向其他sentinel节点发送命令,要求将它设置为领导者
收到命令的Sentinel节点如果没有同意其他Sentinel节点发送的命令,那么将同意该请求,否则拒绝。
如果该Sentinel节点发现自己的票数已经超过Sentinel集合半数且超过quorum,那么将它成为领导者
如果此过程有多个Sentinel节点成为了领导者,那么将等待一段时间重新进行选举
故障转移(Sentinel领导者节点完成之后)
1. 从slave节点中选出一个“合适的”节点作为新的master节点
选择slave-priority(slave节点优先级)最高的slave节点,如果存在则返回,不存在则继续
选择复制偏移量最大的slave节点(复制的最完整性),如果存在则返回,不存在则继续
选择runId最小的slave节点
2. 对上面的slave节点执行slave no one命令让其成为master节点
3. 向其余的slave节点发送命令,让它们成为新master节点的slave节点,复制规则和parallel-syncs参数有关。
4. 更新对原来master节点配置为slave,并保持对其“关注”,当其恢复后命令它去复制新的master节点
节点运维(上线与下线)
生产节点下线可能原因
机器下线:过保等情况
机器性能不足:例如CPU、内存、磁盘、网络等
1.主节点
节点下线
手动进行故障转移
sentinel failover ${masterName}
跳过主观下线、客观下线与领导者选举,领导者即为当前连接的sentinel节点
节点上线
config set slave-priority num #调大新增节点的优先级
sentinel failover ${masterName}
2.从节点
需要区分是临时下线还是永久下线。例如需要做一些配置、AOF、RDB等方面的清理工作。
当上线时候,执行slaveof masterIp masterPort即可
3.Sentinel节点
需要区分是临时下线还是永久下线。例如需要做一些配置的清理工作。
高可用读写分离
可以考虑尝试扩展 JedisSentinelPool,维护master节点与slave节点池
并关注三条消息来维护节点池
switch-master : 切换主节点(从节点晋升为主节点)
convert-to-slave : 切换从节点(原主节点降为从节点)
sdown : 主动下线
完
标签:pool 字节 log 问题 monitor 更换 是否一致 mem read
原文地址:https://www.cnblogs.com/quyangyang/p/11371444.html