标签:source real 参数 基本 几句话 end 实际应用 含义 综述
一、前言:
在6月底来到鹅厂实习,在这一个多月的时间内,主要将我之前研究的目标跟踪和人脸模型结合起来,完成一些人脸跟踪的应用。其中将之前研究的单目标跟踪(SOT, single object tracking)拓展到多目标跟踪(MOT, multi object tracking),针对人脸的应用引入人脸模型,形成针对人脸的多目标跟踪。
在这里还是学习到不少东西的:面向业务应用的算法开发;关注预研的过程;跨任务地思考;把控时间点。
整体和在实验室的感觉是差不多的,但是要比在实验室严肃一些,需要在一段时间内要有产出,不能说像在实验室一样,研究了半年,说没研究出来成果就过了。毕竟要有kpi的要求,要对自己要求严格一些。抛开心态来说,我反而觉得实验室要求还要更严一些:周报、每周的组会等等。在这里只要简单几句话的周报就可以了,但是这句话的周报含义和实验室是差很多的。 - -!
言归正传,这篇博文主要总结我在这段时间调研过的内容和尝试过的一些应用。其实百度一下“人脸检测、人脸识别”等等关键词也会出现很多相关博文,但是这篇主要是我在这段时间的总结。
二、主要内容:
1. dlib: 基于C++实现的人脸应用库,具有python的接口。
这是个非常方便的工具,不只是人脸的相关应用,还具有很多机器学习的算法:聚类算法、svm算法等等。最突出的就是其中的人脸检测、人脸描述子模型等等。应用非常方便,简单几句代码就可以完成功能,基于C++的底层实现,决定了他的高效。
2. MTCNN:人脸检测+对齐模型
MTCNN是中科院在2016年提出来的算法,在做图片预处理或者人脸检测应用中得到大量应用,是一个效果和运算效率都挺优秀的算法。这个算法的流程很简单,通过特征金字塔优化对不同大小目标的检测效果,后续通过三个大小不同的网络,实现从粗略到精细的检测,最后输出人脸目标框和5个人脸关键点(眼睛+鼻子+嘴巴)。但是在使用的过程中需要关注超参的设置:factor和minisize,这些决定了其中的特征金字塔的层数,对检测速率和效果有直接影响。pytorch的运行速率有60fps,但是tf的只有41。但是tf的代码知名度要高一些。
3. 人脸识别模型
人脸数据集:lfw、webFace、celebraA、youtubeFace……
人脸模型和ReID模型是一脉相传,都是对人脸或者行人的图像提取有辨别性高鲁棒性的特征,后续用欧式距离或者余弦距离来进行度量,实现1对1或者1对N的人脸识别,是典型的度量学习。这两者模型的优化都是基于相同的思想:增强网络的表达能力:拉近相同类别的人物在特征域中的距离,拉远不同类别的人物在特征域中的距离。除了增强网络结构和引入外挂组建(attention mechanism)外,主要是针对损失函数进行改进。(这些损失函数的发展历程,非常值得参考。)
1?? FaceNet:
google-CVPR2015

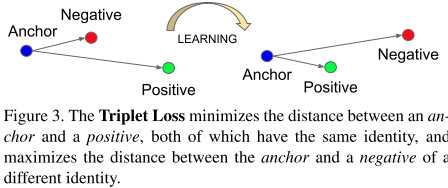
triplet loss示意图:
triplet loss 表达式:
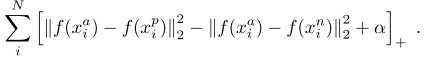
上标含义:a代表某一个样本;p代表a的正样本;n代表a的负样本,$alpha代表两个类别的最小距离,是一个自定义的阈值。+号代表是取正数,小于0则取。其实整个损失函数就是合页损失函数。triplet loss的创新点还有三元子的筛选方式:选取一个batch中距离最远的正样本和距离最近的负样本进行训练。其实这个就是构造困难负样本的方法。
2?? CenterFace:
ECCV2016
主要思想是:softmax-cross-entropy训练的结果是使不同类别的特征拉开,但是忽视相同类别的特征之间的距离。意思就是只关注不同类别的特征。center loss的目的就是将相同类别的特征的距离拉近,使相同、不相同类别的特征都具有更好的辨别性。
softmax-cross-entropy-loss的训练结果(将特征映射到其中的某两维进行可视化):
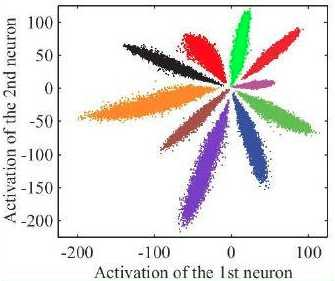
center loss+cross-entropy-loss的训练结果:
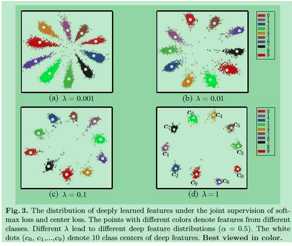
center loss 表达式:
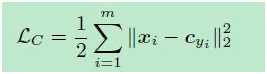
难点在于如何决定一个类别的中心,解决方法是每个batch取计算一次中心,计算方法为:(c为中心点)
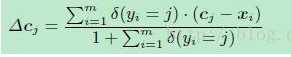
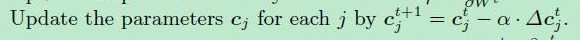
最后center loss结合cross-entropy loss共同进行训练。这个center loss和实验室LNN学姐的center loss是类似的,但是不同之处在于类别中心的决定方法。其实center loss也就是普通discriminative loss的改进版本。如果涉及特征工程,不妨尝试一下这个损失函数,在一定程度可以弥补交叉熵损失函数的缺点。
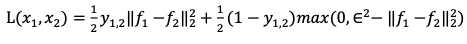
从表达式中可以看出,discriminative loss、center loss、triplet loss是具有很大的关联的。
3?? Sphere face | Arc face | Cos face:(增加特征之间的角度)
这三篇思想都是非常类似,算是同一个时期的论文
主要思想:
不同于交叉熵函数、center loss和triplet loss,这三个face的损失函数将特征映射到一个球上,并且设定特征之间的cos角度之间的margin,从而增大特征之间的差异。注意这三个损失函数都是基于余弦相似度来做度量,所以在1v1或者1vN的应用中,也需要基于余弦相似度。不同之处是这三者添加margin的方法。如图所示:
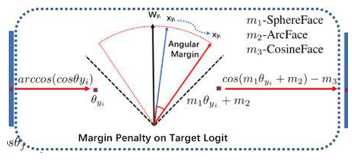
首先将全连接层的权重W和提取的特征x进行l2归一化,使得softmax-cross-entropy loss变成以角度度量分类的形式。如图所示:
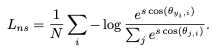
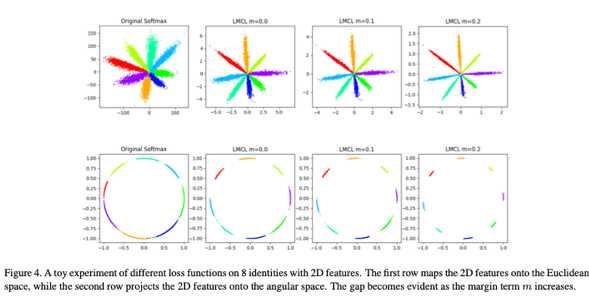
s是将特征x归一化后scale到s的长度,cos(i,j)是指特征x_i和权重W_j之间的角度差的余弦值。具体的推倒步骤,cosFace的论文中有详细的解释。SphereFace是乘性的余弦margin,cosFace和ArcFace是加性的余弦magin,加性的margin会比较容易实现和优化,其中arcFace直接将margin加在角度上,具有更好的集合解释方式,效果会更加明显。其中arcFace现在在人脸识别或者人脸验证的benchmark上,都排名第一,cosFace紧随其后,这大大说明了损失函数的主要性,基于损失函数进行小小的改进,也许会收获大大的性能提升。得到的效果如图所示:
三、一些应用:
1?? dlib库应用:
要实现人脸识别的功能,要分为四个步骤:人脸检测、人脸对齐、人脸模型提取特征、分类器
人脸检测
定义cnn人脸检测器:
face_detector = api.dlib_cnn_face_detector(models.cnn_face_detector_model_location())
进行人脸检测:
face_detections = face_detector(frames, 0)
人脸对齐
定义人脸关键点检测器:
sp = dlib.shape_predictor(models.pose_predictor_model_location())
detection_sp = sp(frame, face_detection.rect)
人脸模型提取人脸描述子(128D)
定义人脸描述子模型:
face_rec = dlib.face_recognition_model_v1(models.face_recognition_model_location())
face_detections = face_rec.compute_face_descriptor(frame, sp(frame, face_detection.rect))
人脸识别:
人脸识别就是对描述子进行分类,分类的模型可以是:决策树、SVM、KNN、神经网络等等。神经网络的方法比较直接,但是随着识别的人脸数量增加,需要的参数量和计算量需要大大增加;这里采用SVM和KNN的方法来实现。这两个实现的模型,都是用sklearn的库来实现。
More:
dlib不只是实现这四个功能,其中也是一个机器学习的算法库,更多可以参考文档
2?? face_recognition:一个基于dlib库的更抽象的人脸检测+识别库
基于几句代码即可实现功能,repo里面有许多example,但是不推荐使用这个库,因为这个库也是基于dlib实现的,完全可以用dlib来实现。
3?? video_cut:
顾名思义就是找出各个明星出现的时间段,这个应用是基于dlib来实现的。
4?? 人脸跟踪
MTCNN人脸检测+Sort多目标跟踪实现,是一个很简单直接的实现
5?? 实时人脸检测与识别:
技术路线:MTCNN+faceNet+KNN

总结:
面对公司的实际应用,只拘泥于自己的领域是远远不够的。我的感悟是,在阅读资料和文献时,也该多了解其他领域的做法和改进。最后希望能成功转正吧!拜托??。
深度学习帮你“认”人—人脸模型 by wilson
标签:source real 参数 基本 几句话 end 实际应用 含义 综述
原文地址:https://www.cnblogs.com/bupt213/p/11372987.html