标签:soft 学习 info 线性 margin 支持 最大化 适合 回归
逻辑斯蒂回归主要用于二分类,推广到多分类的话是类似于softmax分类。求


上述问题可以通过最大化似然函数求解。

上述问题可以采用最小化logloss进行求解。
一般地,我们还需要给目标函数加上正则项,参数w加上l1或者l2范数。
LR适合大规模数据,数据量太小的话可能会欠拟合(考虑到数据通常比较稀疏)。另外,我们可以将连续型属性转化成离散型属性,这样可以提升模型的鲁棒性,防止模型过拟合。
LR和SVM的异同点
相同点
1.他们都是分类算法,是监督学习算法。
2.如果不考虑核函数,LR和SVM都是线性分类算法,他们的分类决策面是线性的。
3.LR和SVM都是判别模型。
不同点
1.目标函数不同:LR最小化logloss或者极大化似然函数,SVM最大化几何间隔,支持向量离超平面越远越好。最后SVM的目标函数可以写成如下拉格朗日函数:
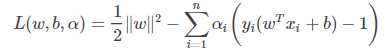
SVM只考虑局部的边界线附近的点(支持向量),LR考虑全局的点,远离边界线的点也起作用。LR适合大型数据集,SVM适合中小型数据集。
2.解决非线性问题时,SVM采用核函数,而LR不采用核函数的方法,一般需要对数据进行预处理(高阶特征)。
3.线性SVM依赖数据表达的距离测量,需要先对数据做标准化处理,而LR不受影响。为了加快收敛速度,LR通常也会先对数据做标准化处理。
4.SVM的损失函数自带正则,即$\frac{1}{2}||w||^2$,因此SVM是结构风险最小化算法。LR是经验风险最小化算法,需要在损失函数上添加正则项。
逻辑斯蒂回归(logisic regression)和SVM的异同
标签:soft 学习 info 线性 margin 支持 最大化 适合 回归
原文地址:https://www.cnblogs.com/xiaoyunjun/p/11370905.html