标签:etc 图形化界面 image 分配 大于 问题: 启动 延迟 source
redis cluster
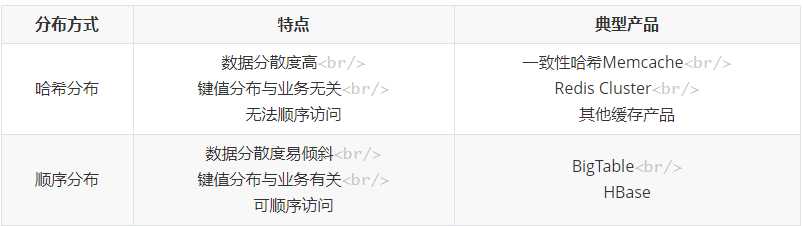
数据节点
顺序分区
哈希分区
hash(key) % node_count
哈希分区
1.节点取余分区
hash(key) % node_count
优点:hash+取余的方式计算节点的分区很简单
缺点:当节点伸缩时候,数据节点关系发生变化,导致数据迁移
扩容的时候建议翻倍扩容,可以降低数据的迁移量。
2.一致性哈希分区
哈希+顺时针(优化取余)
约定长度2的32次方 位的哈希环,在其中分布若干个hash点。
第一步对每个key做哈希处理得到hashVal
第二步将hashVal顺时针偏移,得到的第一个hash点,即为分区的落点
优点:节点伸缩的时候,只会影响邻近节点,但是还是会有数据迁移
翻倍的伸缩,可以保证最小的迁移数据且达到数据的负载均衡
3.虚拟槽分区
预设虚拟槽,每个槽映射一个数据子集,一般比节点数大
采用CRC16(key) & 16383来决定节点
每个节点顺序地平均分布16384个槽,即当有5个节点时
A 0 ~ 3276
B 3277 ~ 6553
C 6554 ~ 9830
D 9831 ~ 13107
E 13108 ~ 16383
RedisCluster架构
节点
由多个master主节点组成,各个master都负责去读写,每个master都有各自的slave节点。
每个node的cluster_enabled配置为yes
Gossip协议
多个master节点之间会使用Gossip协议进行通信
1.meet消息
用于通知新节点加入。消息发送者通知接收者加入到当前集群,meet消息通信正常完成后,接收节点会加入到集群中并进行周期性的ping、pong消息交换。
当A meet B以及A meet C之后,B就可以与C做交互了
2.ping消息
集群中交换最频繁的消息,集群内各个节点每秒向多个其他节点发送ping消息,用于检测节点是否在线和交换彼此状态信息。
ping消息发送封装了自身节点和部分其他节点的状态数据。
3.pong消息
当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信。
pong消息内部封装了自身状态数据。
节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新
4.fail消息
当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新诶下线状态
指派槽
需要为RedisCluster指派槽,指定各个master节点的槽范围,让它进行正常的读写
复制
每个master节点包含若干个slave节点,形成主从复制的形式,以提高高可用性
通过各个节点之间相互监控来达到Sentinel的目的
Redis Cluster的安装
环境安装
1 redis集群管理工具redis-trib.rb依赖ruby环境,首先需要安装ruby环境 2 3 1.yum install ruby 4 yum install rubygems 5 6 2.上传工具包 redis-3.0.0.gem 7 8 3.安装ruby和redis的接口程序 9 gem install /usr/local/redis-3.0.0.gem 10 11 4.将Redis集群搭建脚本文件复制到/usr/local/redis/redis-cluster目录下 12 #cd /root/redis-3.0.0/src/ 13 #ll *.rb 14 # cp redis-trib.rb /usr/local/redis/rediscluster/ -r
集群搭建
搭建集群最少也得需要3台主机,如果每台主机再配置一台从机的话,则最少需要6台机器。
端口设计如下:7001-7006
1 cd /usr/local/redis 2 3 1.复制出一个7001机器 4 cp bin ./redis-cluster/7001 –r 5 6 2.如果存在持久化文件,则删除 7 cd redis-cluster/7001 8 rm -rf appendonly.aof dump.rdb 9 10 3.设置集群参数 11 cluster-enable yes 12 13 4.修改端口 14 port 7001 15 16 5.复制出7002-7006机器 17 cp 7001/ 7002 -r 18 cp 7001/ 7003 -r 19 cp 7001/ 7004 -r 20 cp 7001/ 7005 -r 21 cp 7001/ 7006 -r 22 23 6.修改 7002 -7006 机器的端口 24 25 26 7.创建startall.sh可执行文件 27 28 cd 7001 29 ./redis-server redis.conf 30 cd ../7002 31 ./redis-server redis.conf 32 cd ../7003 33 ./redis-server redis.conf 34 cd ../7004 35 ./redis-server redis.conf 36 cd ../7005 37 ./redis-server redis.conf 38 cd ../7006 39 ./redis-server redis.conf 40 cd .. 41 42 8.增大权限 43 chomd u+x startall.sh 44 ./startall.sh 45 46 9.创建集群 47 ./redis-trib.rb create --replicas 1 192.168.239.139:7001 192.168.239.139:7002 192.168.239.139:7003 192.168.239.139:7004 192.168.239.139:7005 192.168.239.139:7006
集群连接与查看
1 ./redis-cli –h 127.0.0.1 –p 7001 -c c表示集群连接方式 2 3 4 查看集群 5 >cluster info 6 7 查看集群节点 8 >cluster nodes
集群伸缩
一. 伸缩原理
集群伸缩 = 槽和数据在节点之间的移动
二、扩容集群
1.准备新节点(例如,加入6385,6386)
需要是集群模式 cluster_enabled = yes
配置和其他集群节点保持一致
启动后是一个孤儿节点
redis-server conf/redis-6385.conf
redis-server conf/redis-6386.conf
2.加入集群
redis-trib.rb add-node newHost:newPort existsHost:existPort --slave --master-id
redis-trib.rb add-node 127.0.0.1:6385 127.0.0.1:6379
reids-trib.rb add-node 127.0.0.1:6386 127.0.0.1:6379
在没有图形化界面时,建议使用redis-trib.rb能够避免新节点已加入其它集群,造成故障
新节点加入到集群中,有两类作用
为它迁移槽和数据实现扩容
作为从节点负责参与故障转移
3.迁移槽和数据
基于原生命令
1. 对目标节点发送:cluster setslot ${slot} importing \${sourceNodeId},让目标节点准备导入槽的数据。
2. 对源节点发送:cluster set ${slot} migrating \${targetNodeId},让源节点准备迁出槽的数据
3. 源节点循环执行:cluster getkeysinslot ${slot} \${count},每次获取count个属于槽的键
4. 在源节点上执行:migrate ${targetIp} \${targetPort} key 0 \${timeout},将指定的key迁移
5. 重复执行步骤3~步骤4直到槽下所有的数据迁移至目标节点
6. 向集群内所有主节点发送 cluster setslot ${slot} node \${targetNodeId},通知槽分配给目标节点
基于redis-trib.rb
1 #指定任意一个集群中的节点即可 2 redis-trib.rb reshard ${everyHost}:${everyPort} 3 #首先通过提示输入需要迁移多少个slot 4 #然后提示输入接收这些槽的nodeId 5 #接着提示输入源节点的节点ID集合,输入all则表示所有待迁移节点平均 6 7 redis-trib.rb reshard host:port --from ${fromNodeId} --to ${toNodeId} 8 --slots ${slotCount} --yes --timeout --pipeline ${batchSize} 9 #host:port 必传参数,集群内任意节点地址,用来获取整个集群信息 10 #--from 源节点ID,当有多个源节点用逗号分隔,如果是all,则源节点为集合内除目标节点外的所有主节点 11 #--to 目标节点ID,只能填写一个 12 #--slots 需要迁移槽的总数量 13 #--yes 迁移无需用户手动确认 14 #--timeout 每次migrate操作的超时时间,默认为60000毫秒=60秒 15 #--pipeline 控制每次批量迁移键的数量,默认是10
三、缩容集群
1.迁移槽到其他节点
#将槽从当前节点迁出可以使用上文中的reshard进行完成
redis-trib.rb reshard ${everyHost}:${everyPort}
2.通知其他节点忘记下线节点
#在‘其他节点’上依次执行如下命令,需要在60秒内执行
cluster forget ${downNodeId}
3.关闭节点
客户端路由
#计算指定key的对应的槽位
cluster keyslot ${key}
一、moved重定向
1. 客户端给任一节点发送请求
2. 节点计算该请求的槽位以及对应的节点
3. 如果对应的节点是自身,则将执行命令并返回执行结果
4. 如果对应的节点不是当前节点自身,将会返回一个moved异常:MOVED ${slot} \${targetHost} \${targetPort}
5. 然后客户端再重新按照targetHost:targetPort连接另一redis节点,发送请求,跳转至第2步。
二、ask重定向
1. ask请求发生在slot迁移的过程中
2. 客户端向source发送命令(不存在moved重定向的情况)
3. source节点回复客户端一个ASK重定向:ASK ${slot} \${targetHost} \${targetPort}
4. 客户端给target节点发送一个Asking请求
5. 然后紧接着客户端发送命令给target节点
6. target节点执行请求并响应结果
move 和 ask 的比较
MOVED的场景下,可以确定槽不在当前节点
ASK的场景下,槽还在迁移过程中
三、smart客户端(JedisCluster)
1.smart客户端原理:追求性能
从集群中选一个可运行节点,使用clutser slots初始化槽和节点映射
将cluster slots结果映射到本地,为每个节点创建JedisPool
准备执行命令
JedisCluster
1 Set<HostAndPort> nodeList = new HashSet<>(); 2 nodeList.add(new HostAndPort("127.0.0.1" , 7000) ); 3 nodeList.add(new HostAndPort("127.0.0.1" , 7001) ); 4 nodeList.add(new HostAndPort("127.0.0.1" , 7002) ); 5 nodeList.add(new HostAndPort("127.0.0.1" , 7003) ); 6 nodeList.add(new HostAndPort("127.0.0.1" , 7004) ); 7 nodeList.add(new HostAndPort("127.0.0.1" , 7005) ); 8 JedisPoolConfig poolConfig = new JedisPoolConfig(); 9 int timeout = 30_000; 10 JedisCluster jedisCluster = new JedisCluster(nodeList , timeout , poolConfig); 11 jedisCluster.set("hello" , "world"); 12 System.out.println(jedisCluster.get("hello")); 13 14 //获取所有节点的JedisPool 15 Map<String,JedisPool> jedisPoolMap = jedisCluster.getClusterNodes();
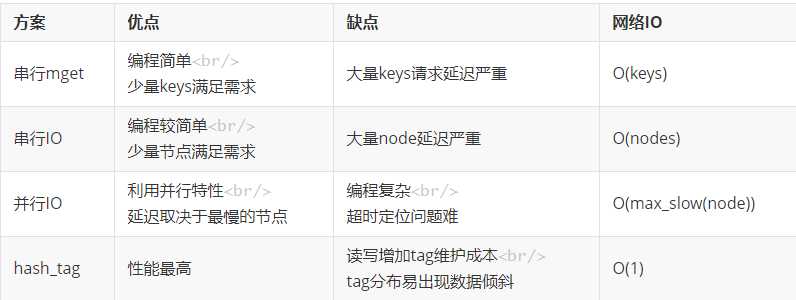
集群模式下批量操作的实现
mget、mset需要一组key必须在同一个槽下
1.串行GET/SET
对每一个key在for循环中依次执行GET/SET
优点:执行简单
缺点:n个key就需要n次网络时间,效率低下
2.根据CRC16&16383的结果做内聚后串行IO
在本地通过CRC16&16383计算出各个key的槽,然后以各个槽做内聚,然后串行依次访问各个node
3.根据CRC16&16383的结果做内聚后并行IO
在本地通过CRC16&16383计算出各个key的槽,然后以各个槽做内聚,然后并行访问各个node
4.使用hash_tag的方式
当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash。
此时对每个key拼接一个字符串{tag},就可以访问一个节点,完成O(1)的请求
比较
故障转移
一、故障发现
通过ping、pong消息实现故障发现:不需要sentinel
1.主观下线(pfail消息)
某个节点认为另一个节点不可用,“偏见”
主观下线流程
节点1每秒定时给节点2发送PING消息
当节点2收到PING消息后返回的PONG消息被节点1收到时,节点1会更新与节点2的最后更新时间
否则如果PING/PONG失败,会触发通信异常断开连接
当与节点2最后的通信时间达到或大于***cluster-node-timeout***,则节点1主观认为节点2下线。
2.客观下线(fail消息)
当半数以上持有槽的主节点都标记某节点主观下线
流程
当每个节点收到其他节点发来的PING消息时,会解析其中是否包含其他节点的主观下线消息
收到PING的结果会把收到的主观下线消息存入故障链表中
在故障链表中,节点可以知道有多少主节点主观下线
故障链表存在有效期,有效期为***cluster-node-timeout X 2***,防止很久之前的主观下线消息长久存在于故障链表中。
计算有效的下线报告数量,当达到半数以上时,就将节点更新为客观下线
并向集群广播下线节点的fail消息
3.客观下线的作用
通知集群内所有节点标记故障节点为客观下线
通知故障节点的从节点触发故障转移流程
二、故障恢复
1.资格检查(对从节点进行资格检查)
每个从节点检查与故障主节点的断线时间
超过cluster-node-timeout * cluster-slave-validity-factor取消资格
cluster-slave-validity-factor:默认是10
2.准备选举时间
对各个符合资格的从节点按照偏移量进行排序偏移量越大(与主节点数据越接近)的节点准备选举时间越小(越早被选举,后续投票阶段可获得更多票数)
3.选举投票
由可用的master节点给各个符合资格的slave节点投票
准备选举时间越小的节点,越早被master节点投票,就更可能得到更多的票数
当投票数达到 (可用master节点数)/2 + 1,可以晋升成为master节点
4.替换主节点
1. 当前从节点取消复制变成主节点(slaveof no one)
2. 执行cluster del slot撤销故障主节点负责的槽,并执行cluster add slot把这些槽分配给自己
3. 向集群广播自己的pong消息,表明已经替换了故障从节点
Redis Clutser常见问题
一、集群完整性
cluster-require-full-converage 默认为yes
完整性要求集群中所有节点都是在线状态并且16384个槽都在一个服务的状态***才对外提供服务
大多数业务无法容忍,cluster-require-full-coverage建议设置为no
二、带宽消耗
官方建议:RedisCluster的节点不要超过1000个
每秒的PING/PONG消息会引起大量的带宽消耗
消息发送频率:节点发现与其他节点通信时间超过cluster-node-timeout / 2时会直接发PING消息
消息数据量:slots槽数组(2KB空间)和整个集群1/10的状态数据(10个节点状态数据约1KB)
节点部署的机器规模:集群分布的机器越多且每台机器划分的节点数越均匀,则集群内整体的可用带宽越高
优化方法
避免使用“大”集群:避免多业务使用一个集群,大业务可用多集群
cluster-node-timeout:影响带宽和故障转移时间,需要权衡
尽量均匀分配到多机器上:保证高可用和带宽
三、Pub/Sub广播
问题:publish在集群每个节点中广播:加重带宽压力
解决方案1:需要使用Pub/Sub时,为了保证高可用,可以单独开启一套Redis Sentinel
解决方案2:使用消息队列
数据倾斜
1.数据倾斜
节点和槽的分配不均匀
redis-trib.rb info ip:port 查看节点、槽、键值分布
redis-trib.rb rebalance ip:port 进行槽的均衡(谨慎使用)
不同槽对应的键值数差异较大
CRC16正常情况下比较均匀
可能存在hashKey
cluster countkeysnslot ${slot} 获取槽对应的键值个数
包含bigKey(大字符串、几百万元素的hash、set、zset、list)
可以在从节点上执行:redis-cli --bigkeys
优化数据结构
内存相关配置不一致
2.请求倾斜(热点key或者bigKey)
通过优化数据结构避免bigKey
热点Key不要使用hash_tag
当一致性要求不高时,可以用本地缓存+MQ
读写分离
只读连接:集群模式的从节点不接受任何读写请求
重定向到负责槽的主节点
readonly命令可以读:连接级别的命令
读写分离:更加复杂
与主从复制有同样的问题:复制延迟、读取过期数据、从节点故障
需要实现自己的客户端:cluster slave ${nodeId}
思路与Redis Sentinel一致
数据迁移
官方迁移工具:redis-trib.rb import
只能从单机迁移到集群
不支持在线迁移:source需要停止写入
不支持断点续传
单线程迁移:影响速度
对source数据进行SCAN,然后进行导入操作
在线迁移
唯品会:redis-migrate-tool
豌豆荚:redis-port
均支持在线迁移,会伪装成source节点的slave,利用这份更新数据再传送给target
集群与单机比较
集群限制
key批量操作支持有限:例如mget、mset必须在一个slot
Key事务和Lua支持有限,操作的Key必须在一个节点
Key是数据分区的最小粒度,不支持bigKey分区
不支持多数据库:集群模式下只有db 0
复制只支持一层:不支持树形复制结构
分布式Redis不一定好
Redis Cluster:满足容量和性能的扩展性,很多业务不需要
不多数客户端性能会降低
命令无法跨节点使用:mget、mset、scan、flush、sinter
Lua和事务无法跨节点使用
客户端维护更复杂:SDK和应用本身消耗(例如更多的连接池)
很多场景下:Redis Sentinel已经足够好
完
标签:etc 图形化界面 image 分配 大于 问题: 启动 延迟 source
原文地址:https://www.cnblogs.com/quyangyang/p/11372902.html