标签:timestamp 性能 时间 压力 alert == alarm 归档 恢复
小米的监控系统:OpenFalcon是一款企业级、高可用、可扩展的开源监控解决方案。
自动发现,支持falcon-agent、snmp、支持用户主动push、用户自定义插件支持、opentsdb data model like(timestamp、endpoint、metric、key-value tags)
支持每个周期上亿次的数据采集、告警判定、历史数据存储和查询
高效的portal、支持策略模板、模板继承和覆盖、多种告警方式、支持callback调用
最大告警次数、告警级别、告警恢复通知、告警暂停、不同时段不同阈值、支持维护周期
单机支撑200万metric的上报、归档、存储(周期为1分钟)
采用rrdtool的数据归档策略,秒级返回上百个metric一年的历史数据
多维度的数据展示,用户自定义Screen
整个系统无核心单点,易运维,易部署,可水平扩展
整个系统的后端,全部golang编写,portal和dashboard使用python编写。
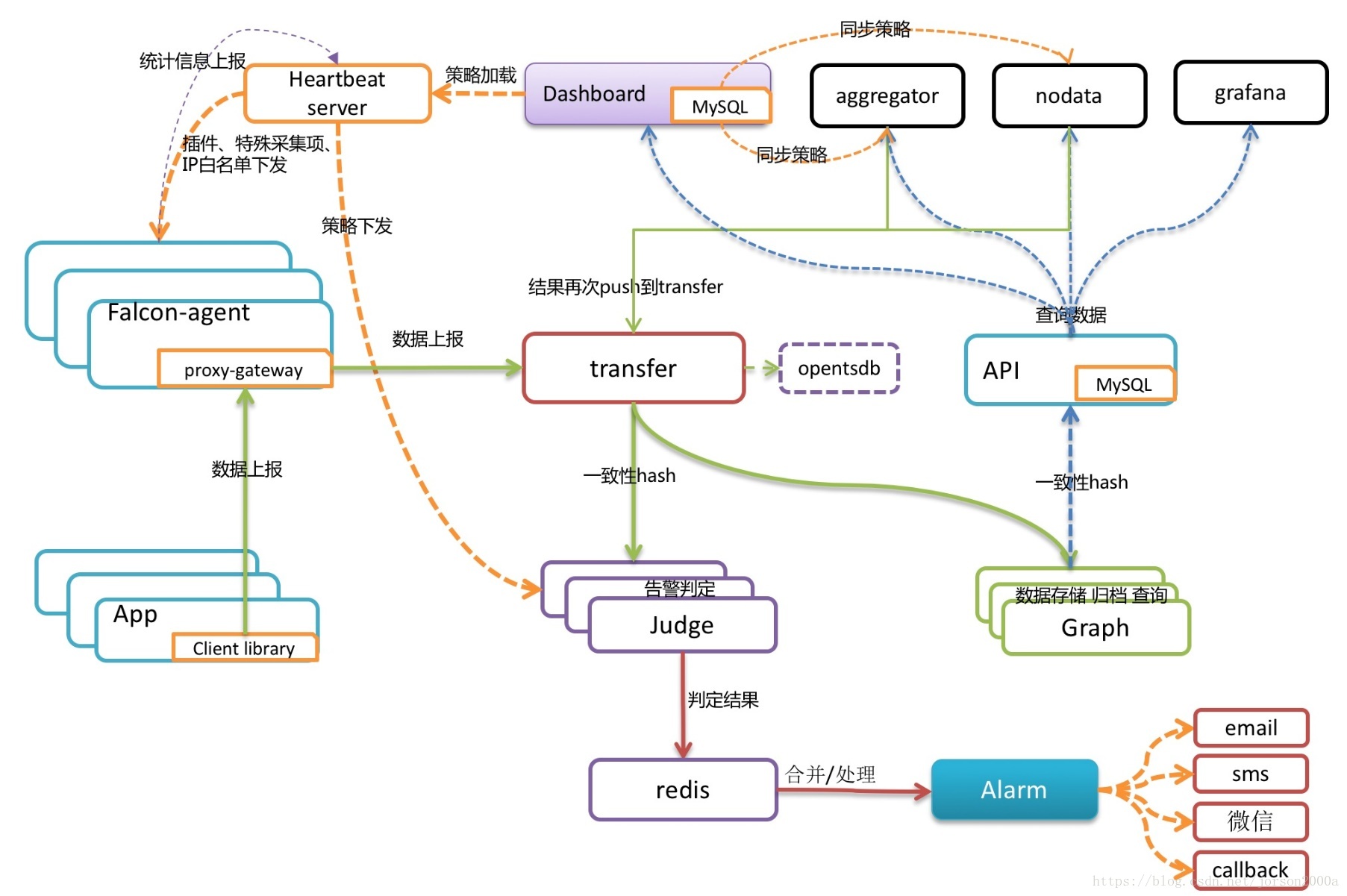
每台服务器都安装falcon-agent。falcon-agent是一个golang开发的daemon程序,用于自发现的采集单机的各种数据和指标。只要安装了falcon-agent,机器就会自动采集各项指标,主动上报,不需要用户在server做任何配置。虽然server端有较大的压力,但是open-falcon的服务端组件单机性能足够高,同时可以水平扩展,所以自动采集足够多的数据,更方便SRE和DEV事后追查问题。
另外,falcon-agent提供了一个proxy-gateway,用户可以方便的通过http接口,push数据到本机的gateway,gateway会帮忙高效率的转发到server端。
open-falcon采用和opentsdb相同的数据格式:metric、endpoint、多组key value tags。
{
metric: load.1min,
endpoint: open-falcon-host,
tags: srv=falcon,idc=aws-sgp,group=az1,
value: 1.5,
timestamp: date +%s,
counterType: GAUGE,
step: 60
}
1、transfer,接收客户端发送的数据,做数据规整。然后transfer会根据一致性hash算法,进行数据分片,并转发到多个后端系统。
2、transfer 提供jsonRpc接口和telnet接口。transfer是无状态的,挂掉一台或者多台不会有影响,同时transfer性能很高,每分钟可以转发超过500万条数据。
3、transfer支持的业务后端有judge、graph、opentsdb。judge是高性能告警判定组件;graph是高性能数据存储、归档、查询组件;opentsdb是开源的时间序列数据存储服务。
4、transfer的数据来源有:
1.falcon-agent采集的基础监控数据
2.falcon-agent执行用户自定义的插件返回的数据
3.client library:线上的业务系统,都嵌入使用了统一的perfcounter.jar,对于业务系统中每个RPC接口的qps、latency都会主动采集并上报
说明:上面这三种数据,都会先发送给本机的proxy-gateway,再由gateway转发给transfer。
1、报警判定,由judge组件来完成。用户在web portal配置相关的报警策略,存储在MySQL中。heartbeat server定期加载MySQL中的内容。judge也会定期和heartbeat server保持沟通,来获取相关的报警策略。
2、heartbeat sever除了加载MySQL中的内容,还会根据模板继承、模板项覆盖、报警动作覆盖、模板和hostGroup绑定,计算出最终关联到每个endpoint的告警策略,提供给judge组件来使用。
3、transfer转发到judge的每条数据,都会触发相关策略的判定,如果满足报警条件,则会发送给alarm,alarm再以邮件、短信、米聊等形式通知相关用户,也可以执行用户预先配置好的callback地址。
4、用户可以灵活配置告警判定策略,比如连续n次都满足条件、不同时间段不同阈值、维护周期内忽略等等。另外也支持突升突降类的判定和告警。
1、快速读取存储在graph里的数据,靠graph和API组件来实现。
2、transfer会将数据往graph组件转发一份,graph收到数据以后,会以rrdtool的数据归档方式来存储,同时提供查询RPC接口。
3、API面向终端用户,收到查询请求后,会去多个graph里查询不同metric的数据,汇总后统一返回给用户。
dashboard首页,用户可以以多个维度来搜索endpoint列表,即可以根据上报的tags来搜索关联的endpoint。
1、host group的管理可以和服务树结合,机器进出服务树节点,相关的模板会自动关联或者解除。服务上下线不需要手动来变更监控。
2、模板支持继承和策略覆盖,模板和host group绑定后,host group下的机器会自动应用该模板的所有策略。
3、也可以写表达式达到监控的目的,对于endpoint不是机器名的场景非常方便。
1、监控系统数据量大、写操作多、查询需要高效率。
2、open-falcon数据按照用途分成两类,用来绘图的和做数据挖掘的。
3、对于绘图的数据来讲,查询要快,信息不能丢失。open-falcon参考rrdtool的理念,在数据每次存入的时候,自动采样、归档。归档策略如下,历史数据保存5年;按照平均值采样、最大值采样、最小值采样存三份。
4、对于原始数据,transfer会打一份到hbase,也可以直接使用opentsdb,transfer支持往opentsdb写入数据。
标签:timestamp 性能 时间 压力 alert == alarm 归档 恢复
原文地址:https://www.cnblogs.com/junjun511/p/11373862.html